我们知道,有了合适的技术,我们可以做得比仅仅跟上更新要好得多,并且如果我们还可以确保灵活的开发并能更轻松地保护我们的数据,在需要时访问,处理和分析数据的过程,那么我们会做得更好。借助正确的工具和最佳实践,组织可以使用其所有数据,使更多的用户可以访问它,并推动做出更好的业务决策。
新技术的创新可以改善可用性,简单性,成本和性能方面的现代基于云的数据湖,数据仓库和分析能力,这些能力应能够独立扩展计算和存储,从而满足当前和未来的需求。它不应干扰任何正在进行的工作负载,降低性能或由于后台运行备份进程而导致服务不可用。而且它应该便宜,可以通过巧妙的方式来保存我们的数据,而不必将其复制和移动到其他地方。
现代数据湖是现代企业的基础。如果设置正确,则数据湖将吸引人们自然而然地将想法吸引到那里,并在确保系统的耐用性,灵活性和可用性方面获得有用的见解。
技术是任何现代数据湖的最基本需求-如今,如今,诸如Databricks,Microsoft Azure,AWS云之类的许多技术正在提供许多服务来支持大数据,这既是实现强大洞察力的特定方法,也是一种思想。更快,更好的决策,甚至跨多个行业的业务转型。
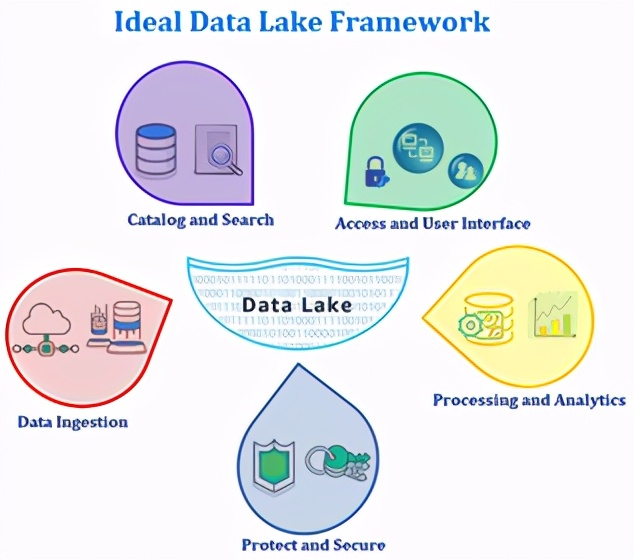
数据湖的支柱包括可扩展和持久的数据存储,收集和组织数据的机制以及处理和分析数据以及共享发现的工具。因此,我们专注于任何现代数据湖中应包含的关键技术,以支持大数据意味着任何类型的数据。
- 云具有无限的资源-基于云的服务特别适合数据湖,因为它为我们提供了无限的资源,这意味着云基础架构可在几分钟或几秒钟内按需提供几乎无限的资源,而无需担心任何事情。组织只需为使用的资源付费,从而可以在不影响性能的情况下动态支持任何规模的用户和工作负载。
- 节省资金,专注于数据的云技术—基于云的服务可为任何组织提供云构建的解决方案,从而避免了硬件,软件和其他基础架构的昂贵,前期投资以及维护,更新和保护的成本本地系统。
- 云技术附带了自然集成点:据估计,您要分析的数据中有多达80%来自业务应用程序数据,运营数据存储,点击流数据,社交媒体平台,物联网事物和实时流数据。与构建内部数据中心相比,将这些数据集成到云中要容易得多,而且成本更低。
- 使用noSQL内置-它描述了一种技术,该技术可以存储和分析更新形式的数据,例如从计算机和社交媒体生成的数据,以丰富和扩展组织的数据分析。众所周知,传统的数据仓库无法很好地容纳这些数据类型。因此,近年来出现了更新的系统来处理这些半结构化和非结构化数据形式,例如JSON,Avro和XML。
- 支持现有技能和专业知识-Data Lake支持有效存储和处理任何类型的数据,数据管理,数据转换,集成,可视化,商业智能和分析工具所需的功能,可以轻松地与SQL数据仓库进行通信。标准SQL根深蒂固的角色也意味着大量人具有SQL技能。它使其他编程语言能够提取和分析数据。
应该清楚地认识到云在成本,规模,性能,易用性和安全性方面的内在优势,因为它们对整体数据湖计划和成果的影响。弹性云数据湖具有两个主要优势:
- 容量规划和管理的复杂性和成本–系统的规模,平衡和调整系统应内置于系统中,并由其自动化,并由我们的订购成本承担。
- 快速动态配置存储和计算资源以满足高峰和稳定使用期间不断变化的工作负载的需求也是如此。容量是我们在需要时所需的一切。
选择最佳的基于云的数据湖生态系统-理想的云数据湖解决方案兼具两全其美的能力-灵活地集成关系和非关系数据以及识别服务,从而为企业和企业用户提供所需的架构方法并切实可行,数据科学家也是如此。最好的基于云的数据湖生态系统产品完美地说明了这些要点。这些包括:
- 存储— Data Lake存储必须能够容纳大量结构化,半结构化和非结构化数据。尽管Hadoop的HDFS可以支持,但基于云的对象存储可能是更好的选择,不仅可以在节点之间分布数据冗余。AWS提供了用于可靠,安全且可扩展的对象存储的Amazon Simple Storage Service(S3)和Amazon Glacier,后者具有相似的特性,可以以最低的管理开销实现极低成本的长期归档和备份。
- 计算—在数据湖中,您可以通过使用不同的计算资源轻松地应用不同的分析算法。例如,流分析将需要高吞吐量,而批处理可能会占用大量处理器。Apache Spark可能需要大量内存,而AI在GPU上可能效果最好。与其他云提供商以及本地Hadoop相比,基于云的理想数据湖服务具有显着的灵活性,后者将存储直接绑定到每个节点中的计算。
- 分析—数据湖的美德在于它如何针对许多不同的用例,以多种不同的方式分析同一数据。理想的基于云的数据湖生态系统无需将数据迁移到不同的操作环境,也不需要随之而来的开销,成本,工作量或延迟。
- 数据库-并非所有的数据湖数据都是非结构化的。通常,在事务和分析处理方面拥有更紧密的组织是很有意义的。同样,这提供了满足许多数据湖应用程序需求的多功能性。
- 实时流处理-并非所有数据都简单地存储在数据湖中并在以后进行分析。通常,需要收集,存储,处理甚至分析运动中的实时数据。一个理想的基于云的数据湖生态系统,可提供强大的服务来收集,存储和分析流数据,并能够构建满足特殊需求的自定义流数据应用程序。
- 人工智能-这是任何理想的基于云的数据湖生态系统中最有用的功能。人工智能和机器学习越来越成为构建智能应用程序的流行工具,例如预测分析和深度学习。
- 安全服务-如图所示,安全,隐私和治理是将敏感数据信任到云数据湖的基本要素。
- 数据管理服务-由于数据在不同的平台中使用,因此ETL是一项重要功能,可确保正确地移动和理解数据。理想的基于云的数据湖生态系统必须具有ETL引擎,以轻松理解数据源,准备数据并将其可靠地加载到数据存储中。
- 应用程序服务—尽管数据湖本身可以是无价的资源,但当与更高级别的应用程序集成时,它确实会变得活跃起来。理想的基于云的数据湖生态系统具有功能全面的实用程序,可用于IoT用例,移动应用程序以及对其他任何对象的API调用。
数据湖的基本前提是对各种分析和面向分析的应用程序和用户具有适应性,并且所有其他企业需求都有安全性,访问控制以及合规性框架和实用程序等服务满足。