












本文转载自微信公众号「后端技术指南针」,作者+++++ 。转载本文请联系后端技术指南针公众号。
1. MySQL磁盘报警了
年前的一周,大白早早来到公司,像往常一样泡上一杯枸杞水,然后看了下数据库的磁盘。
嚯!super库的bighero表磁盘占用率竟然85%了,马上就到报警设定的阈值。
喝了一口养生枸杞水,大白决定盘它,因为这磁盘不能在过年的时候爆了,否则这事就大了。
分析了下bighero表中的数据,发现有几百万数据目前已经不用了,可以直接删掉,说干就干,一顿操作猛如虎,半个多小时,删除脚本写完自测OK了。
考虑到白天算是高峰期,于是决定晚上回家再执行脚本,大白怕忘了在手机上订了个闹钟提醒。
经过一天的忙碌,晚上11点半回到家中,简单收拾下,闹钟提醒大白要删数据了,于是连上准备开搞。
安全起见删除脚本加了个sleep几毫秒,nohup脚本拉起,看了下日志已经正常启动了,看着时间还早刷了会儿抖音,回来看脚本也执行完了,完美!
数据删完了,呼呼睡大觉去了!
2. 为啥磁盘还满?
第二天,像往常一样,大白去小区附近的菜市场3元买了个饼,边吃边等公交车。
转了3次地铁,终于到公司了,一杯枸杞水,准备开干!
呃?昨晚删了 咋磁盘占用率竟然86%了,不降反而涨了,真是见鬼了。
稳住了神,分析一波应该是MySQL并没有真正清理掉这部分数据,而是假删除。
这种假删除的行为在Linux中并不稀罕,属于常规操作,算是一种策略思想,所以断定MySQL也可能这么干了。
谷歌一下,文章还真不少呢,翻了几篇之后 找到了一个命令查看碎片信息:
- SELECT * from
- (
- SELECT CONCAT(table_schema,'.',table_name) AS 'table_name',
- table_rows AS 'Number of Rows',
- CONCAT(ROUND(data_length/(1024*1024),6),' M') AS 'data_size',
- CONCAT(ROUND(index_length/(1024*1024),6),' M') AS 'index_size' ,
- CONCAT(ROUND(data_free/(1024*1024),6),' M') AS'data_free',
- ENGINE as 'engine'
- FROM information_schema.TABLES
- WHERE table_schema = #{库名}
- ) t ORDER BY data_free DESC;
- data_size : 数据的大小
- index_size: 索引的大小
- data_free :数据在使用中的留存空间
- engine:表引擎名称
其中data_free就代表磁盘碎片的大小,也就是我们需要消灭的地方。
于是把上面的sql语句修改了一下执行,果然bighero表的data_free有20GB这么多,找到了原因,所以大白准备手动清理一波。
3. 磁盘清理神器
谷歌一波之后发现,不同的MySQL存储引擎清理方式有所不同。
- SHOW ENGINES;//查看引擎命令
MySQL有多种存储引擎,常用的是MyISAM和InnoDB,大白的库使用的是InnoDB引擎,不过先简单看下这俩有啥特点吧。
3.1 MyISAM引擎
MyISAM基于ISAM存储引擎,并对其进行扩展。
- 支持 B-tree/FullText/R-tree 索引类型;
- 锁级别为表锁,表锁优点是开销小,加锁快;缺点是锁粒度大,发生锁冲动概率较高,容纳并发能力低,这个引擎适合查询为主的业务;
- 此引擎不支持事务,也不支持外键;
- BLOB和TEXT列可以被索引;
- 强调了快速读取操作,比如它存储表的行数,只需要直接读取已经保存好的值而不需要进行全表扫描。
3.2 InnoDB引擎
- 支持事务,支持回滚,支持外键;
- 支持 Hash/B-tree 索引类型;
- 锁级别为行锁,行锁优点是适用于高并发的频繁表修改,高并发是性能优于 MyISAM;
- 系统消耗较大,索引不仅缓存自身,也缓存数据,相比 MyISAM 需要更大的内存;
3.3 操作一把
InnoDB引擎可以选择的操作命令包括:
- OPTIMIZE TABLE tablename
- ALTER TABLE tablename ENGINE = INNODB
实际上在运行上述清理命令时,MySQL会锁定表,清理的数据越大消耗的时间越长,因此这个操作一定要在夜深人静的时候进行操作。
OPTIMIZE TABLE命令会重组表和索引的物理存储,减少对存储空间使用。
ALTER TABLE tablename ENGINE = Innodb;命令好像是句废话,但是实际上也重新整理碎片了,它实际执行的是一个空的ALTER命令,会重建整个表,删掉未使用的空白空间。
好了,大致找到了命令,但是还得半夜操作,这事真是不地道啊,不过也没办法。
像往常一样,11点半到家,洗漱了下,开始清理,心里还有点忐忑,等待了一会儿,看到已经OK了。
刷一下监控磁盘占用率已经降到80%以下了,舒一口气,可以安心睡觉了。
4. MySQL为什么会有碎片?
我们以InnoDB存储引擎为例,来看看为什么会出现碎片。
- 当执行删除一些行,这些行只是被标记为“已删除”,而不是真的从索引中物理删除了,因而空间也没有真的被释放回收。
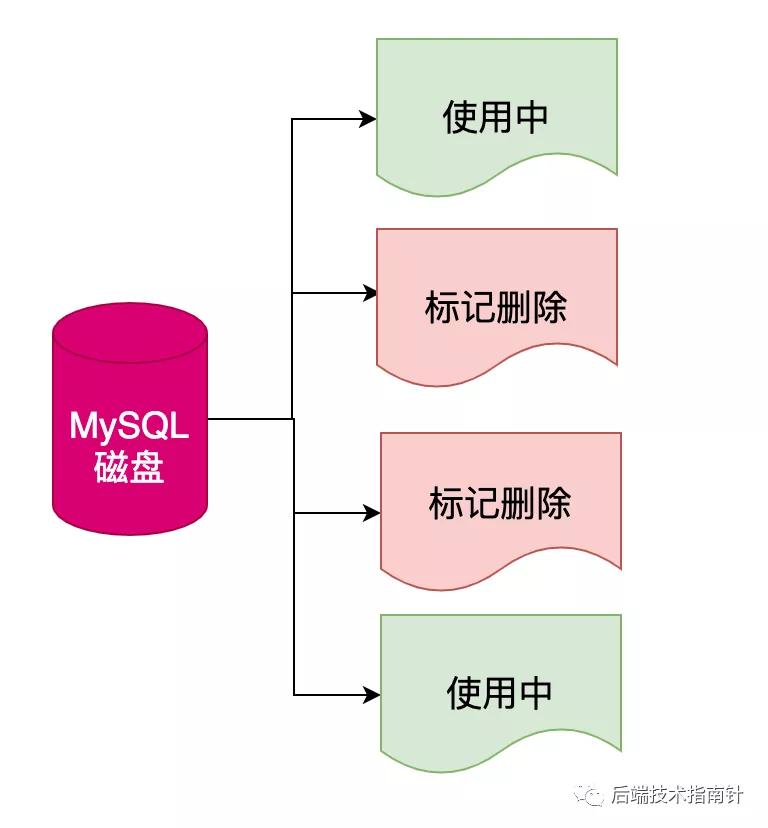
- 大量随机删除操作,会造成不连续的空白空间,当插入数据时,这些空白空间则会优先被利用起来,但是肯定不会全部被利用,也就出现数据碎片。
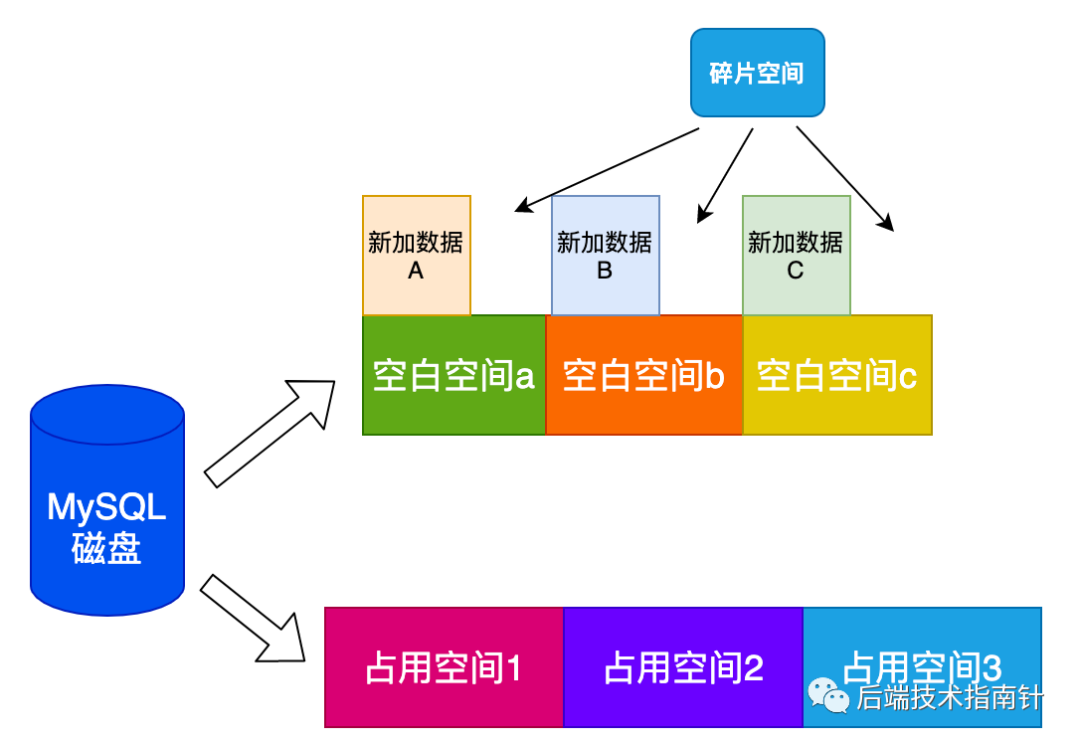
- 大量UPDATE操作,Innodb的最小物理存储分配单位是页,在更新变长数据时UPDATE也可能导致页分裂,频繁的页分裂,页会变得稀疏,并且被不规则的填充,最终会有碎片,比如原来长度是255字节修改之后是128字节,那么就可能出现128字节左右的空洞无法被100%利用。
由于清理碎片需要锁表,对于业务有影响,MySQL官方建议不要每小时或每天进行碎片整理,一般根据实际情况,只需要每周甚至更久整理一次即可。
就这样吧!明天就要开工了,今天再好好耍一天。





















