












Python以语法简单、关键字少著称,因此经常被各大媒体忽悠其是一门非常容易入门的编程语言。他的特定描述自然不言而喻,但其是否容易入门却饱受争议。因为每个人的基础都不一样。
市面上大部分的 Python 入门书籍的目录都非常长(毕竟缺少某个重要的知识点会被批),但是作为入门来说,真的需要所有的知识点都学习一遍吗?
对于入门者来说,看着这些书籍目录学习往往会遇到各种陷阱,今天我就来分享一下我的个人观点。
语法太多了
Python 的语法规则多不多?其实非常多,如果你学习过一些古老不再更新的编程语言,对比下来你就会发现其实 Python 语法非常多。
因为 Python 需要适应现代的开发要求,他"逼不得已"需要不断加入新的语法特性,比如像"装饰器"、"海象运算符"等等。
此时初学者会陷入第一个陷阱——抵受不住"目录"的诱惑,感觉自己跳过了某个知识点就会无法入门。
作为入门者我是不建议学习这些东西(短期内你大概率用不上)。
那么,到底需要学习哪些语法?
- 分支判断
- 循环
说白了就是 if 和 for 循环。
其实,学习这些语法不是要你去记忆怎么写,大部分时候这些语法语句不需要我们亲手敲出每个字母,因为现在的 ide 都非常友好,一般都能提供生成代码段的功能,如下是 vscode 的演示:
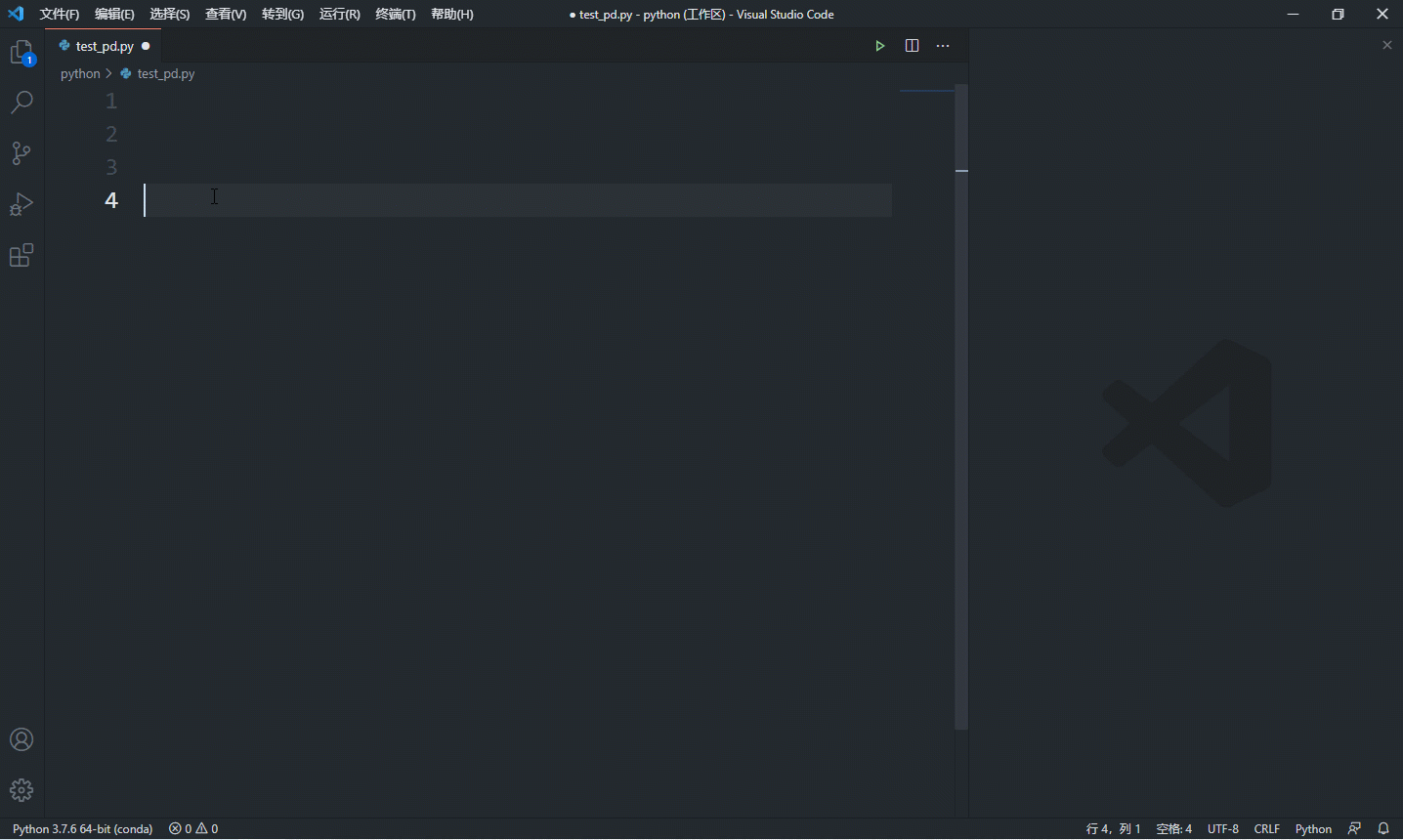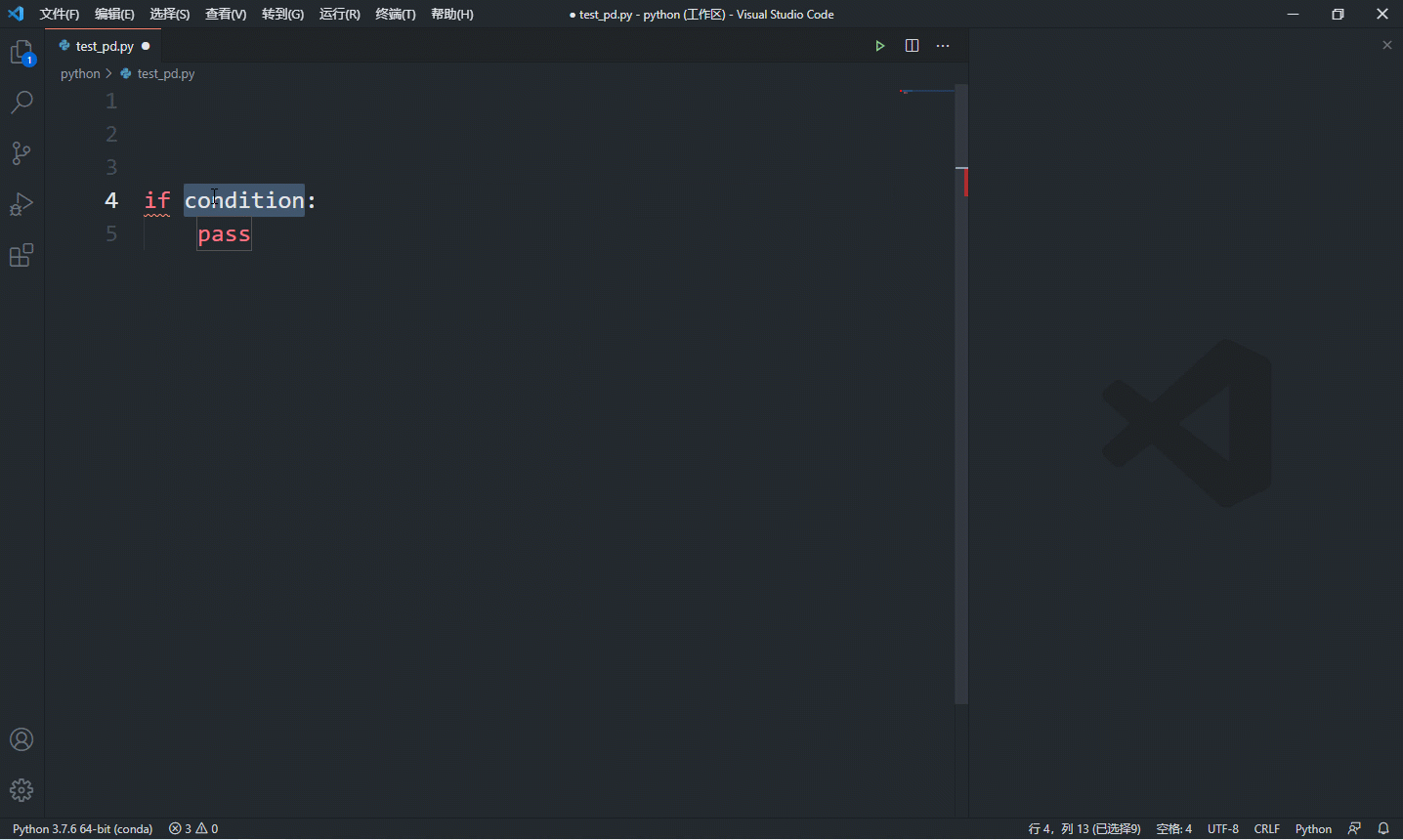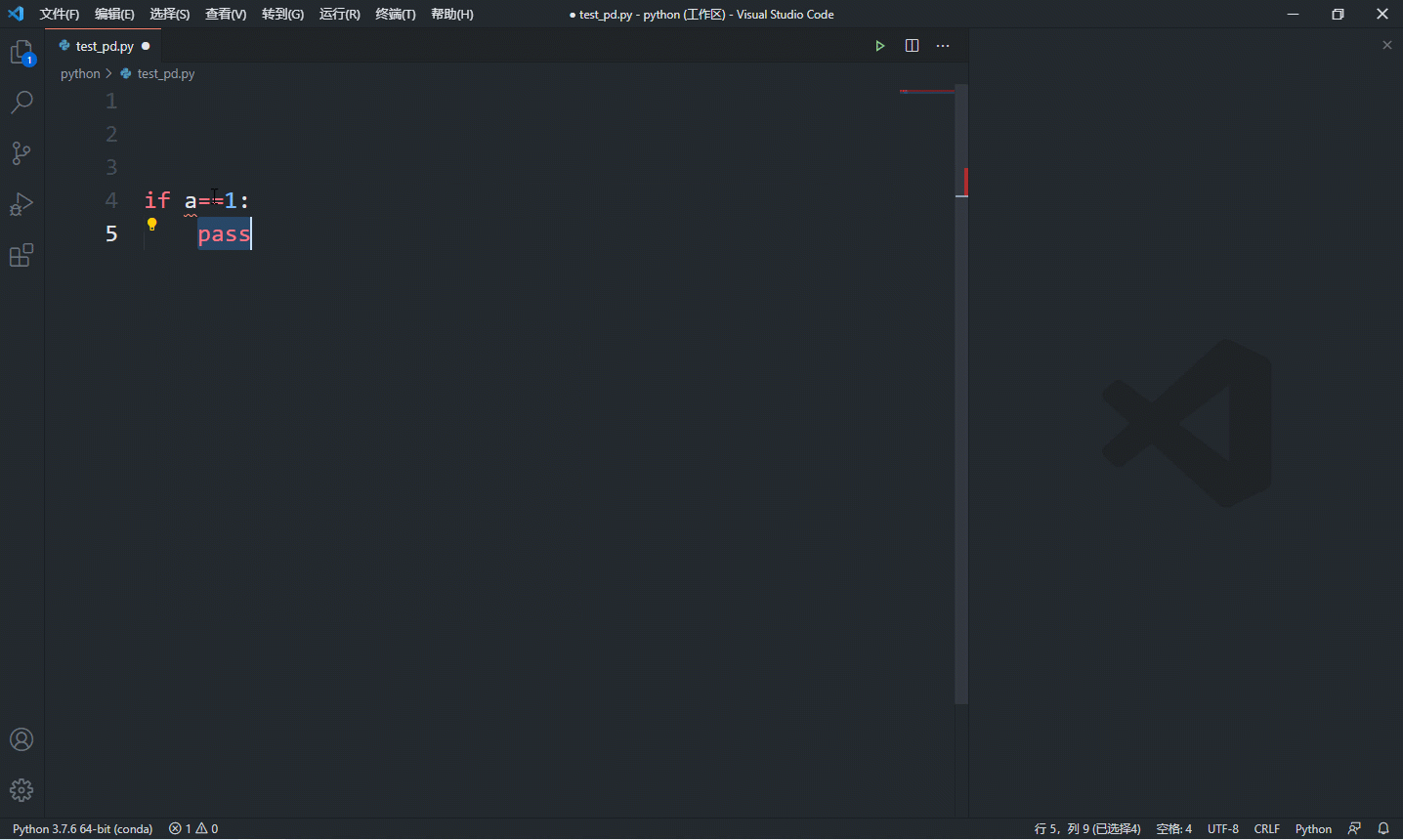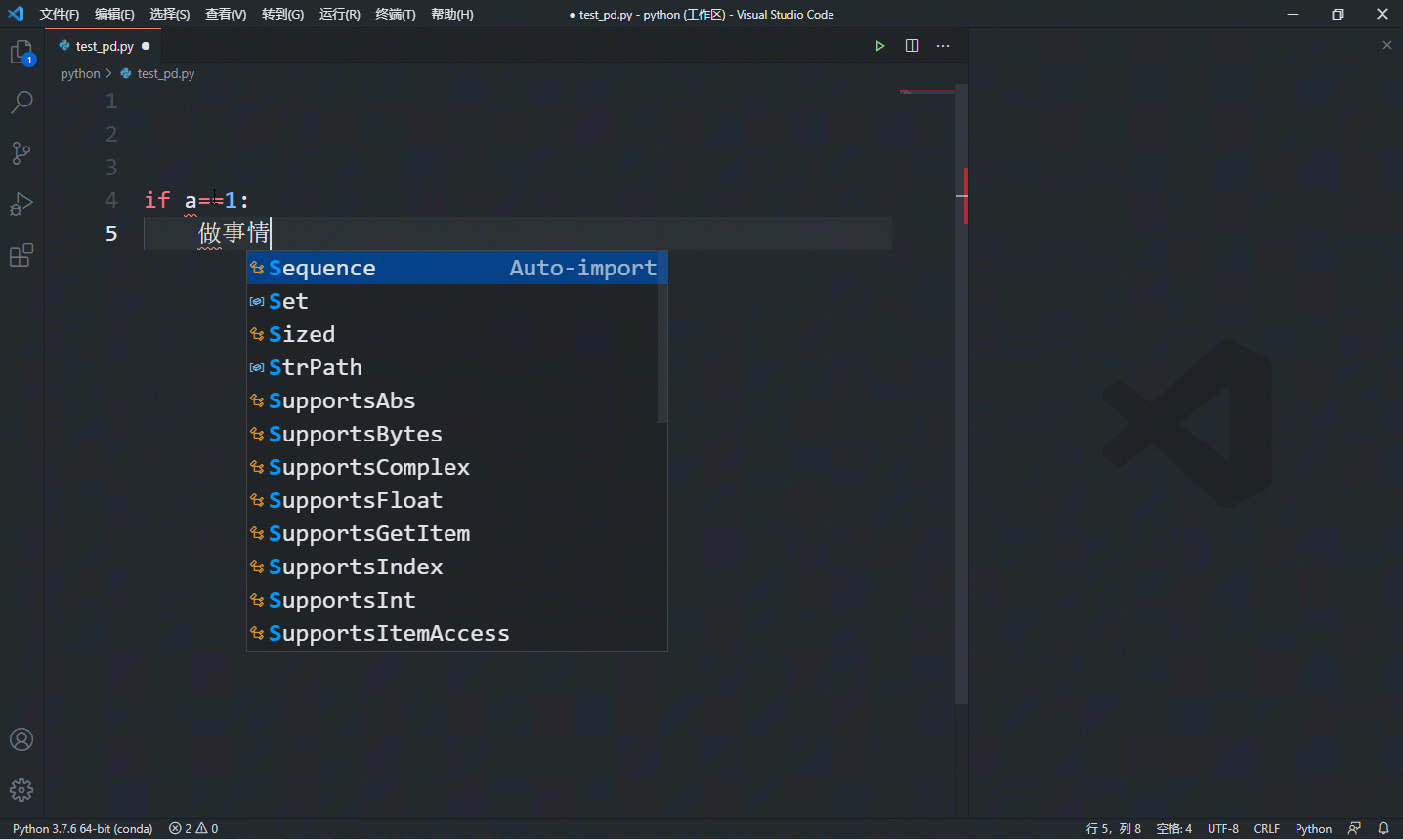
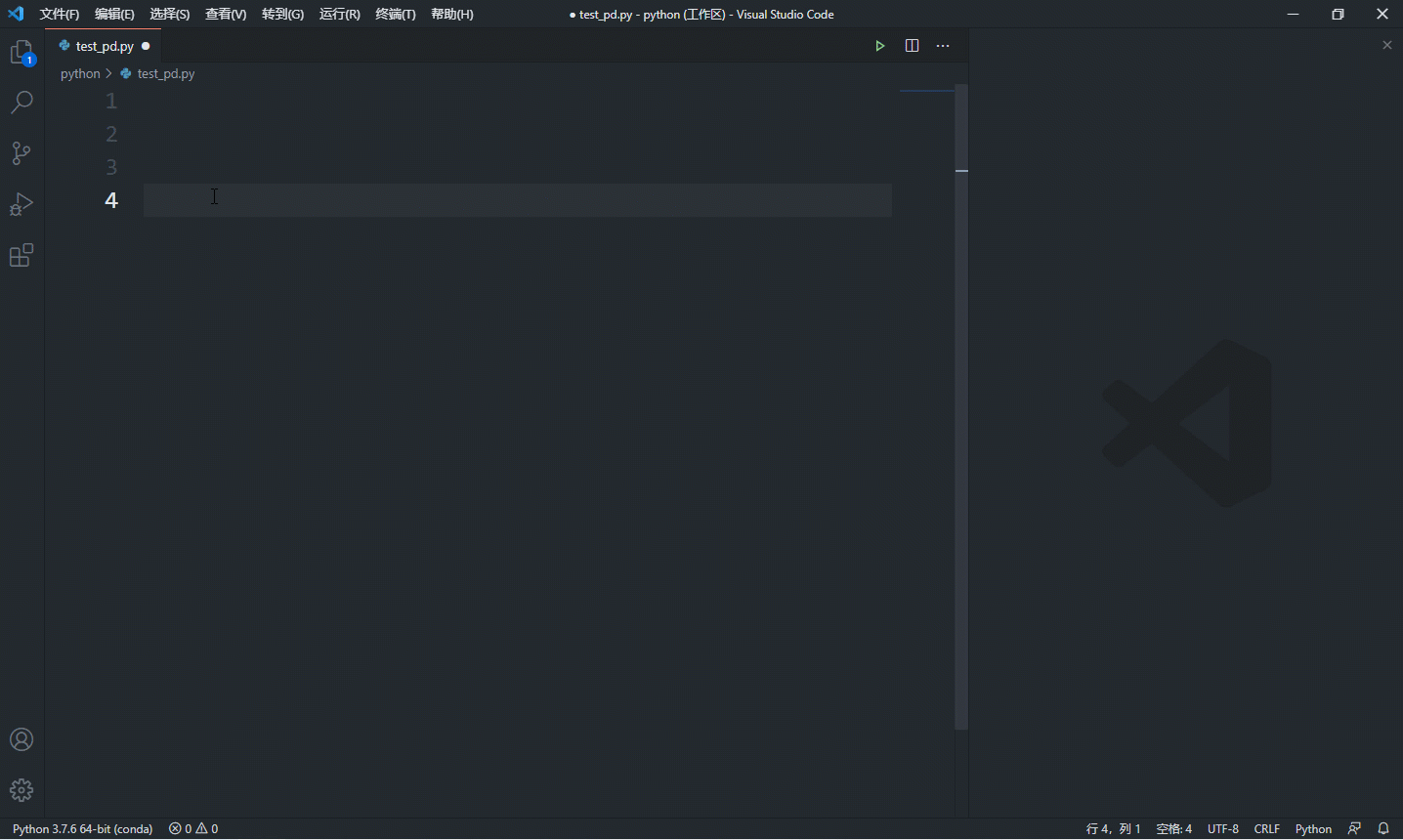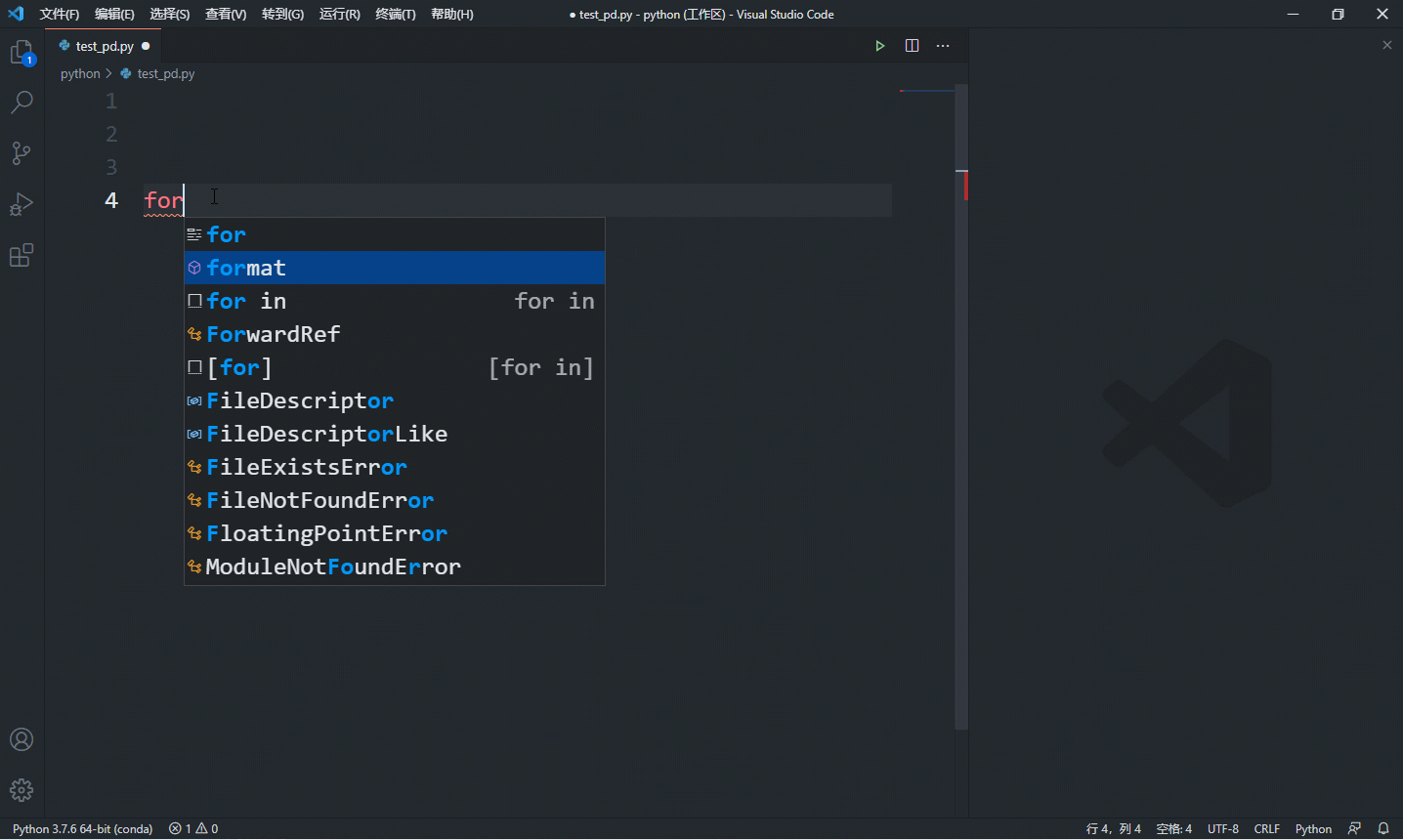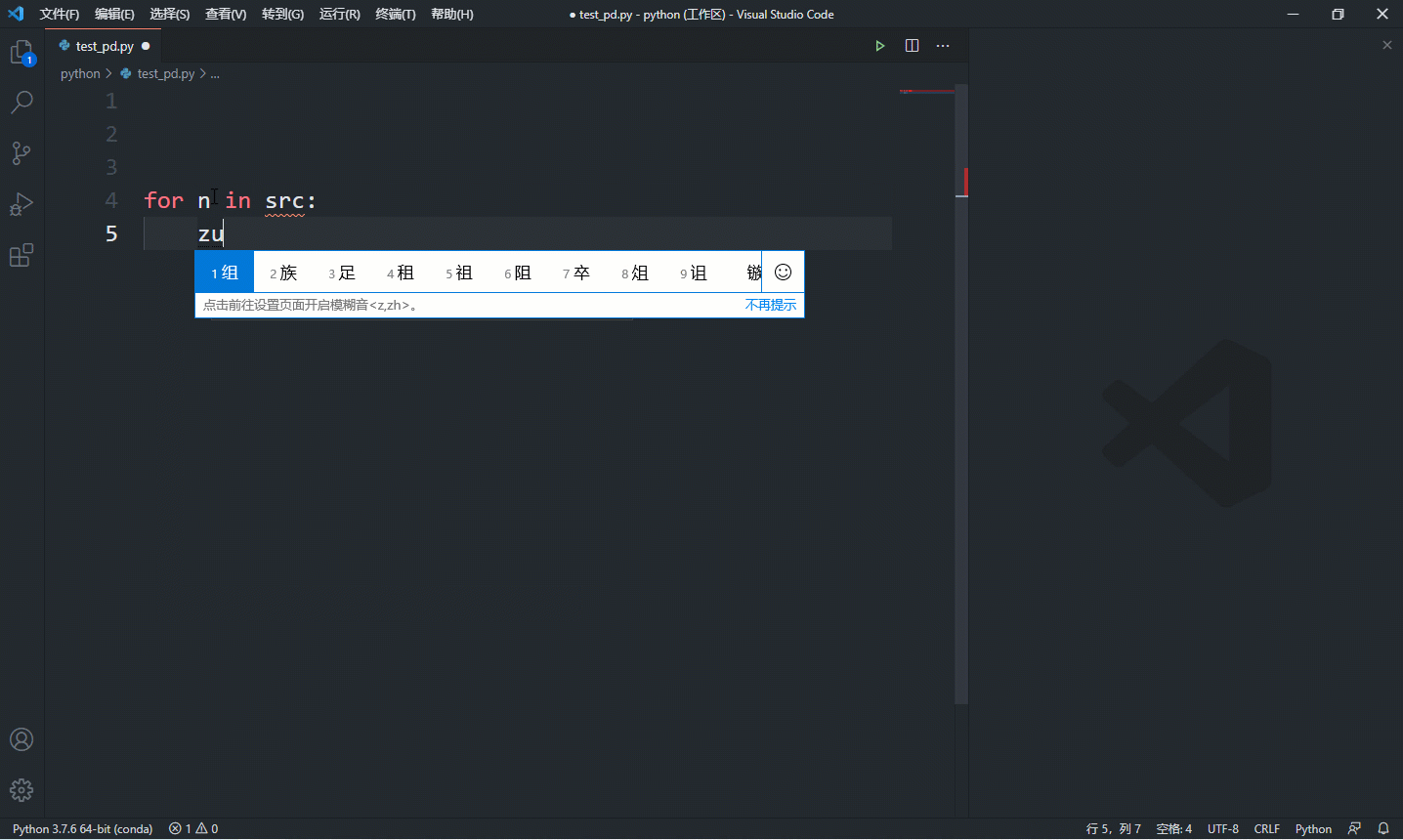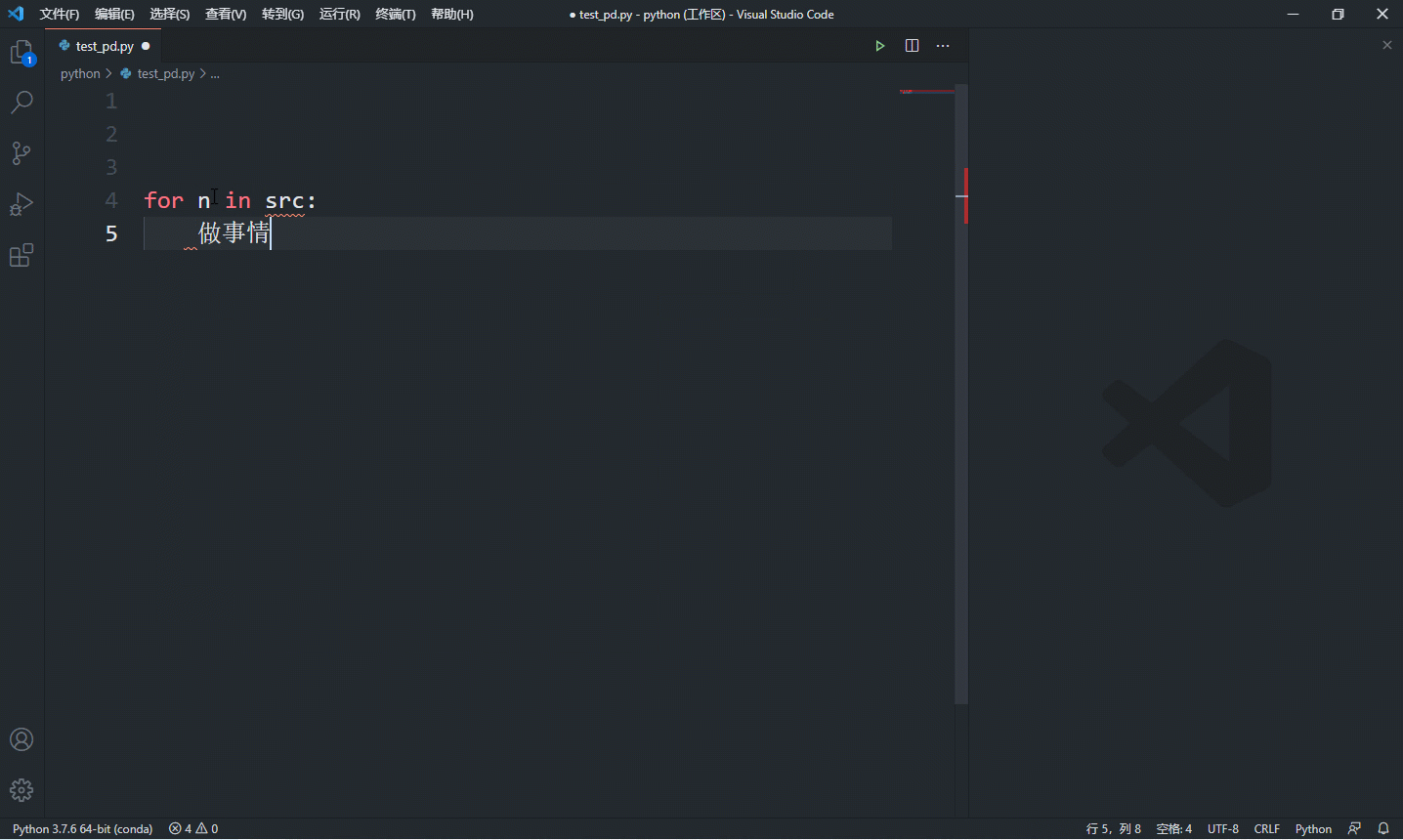
经常看到有人建议入门要亲手输入每段代码,大家一定要三思,这只能提升你键盘打字水平
有段时间我经常需要来回切换多种编程语言,但并不考验我的语法记忆水平,这就是代码段的好处
小伙伴:"那其他的语法规则呢,比如运算符优先级别这些,我总是记不住怎么办?"
其实我也从来没有去记忆啥运算符优先级别,因为在出现多种运算符时,我总是使用括号明确他们的优先级别:
小伙伴:"这样子看起来,好像很容易入门,if 和 for 语法真的这么容易学习?"
并不是,像 if 语法的学习重点不是怎么写,而是怎么构造 bool 值,这就需要你进一步了解基本的数据类型(str、int、bool这些)。
幸好这些知识点的数量非常少,对于入门来说也不需要深入了解每个类型的保存机制(比如需要多少个字节)
以上这些知识点可能只是一本入门书籍中的1到3个章节的内容
序列的处理非常重要
当你基本了解 if 和 for 的使用后,下一步就要了解序列的数据结构(列表、元组)。
此时,初学者会陷入另一个坑——列表有许多方法需要记忆!
同样地,我也不推荐入门者记忆这些方法,只需要记住最常用的1、2个操作即可。比如:
- 添加元素:append
- 移除元素:remove
同理,字符串也有许多处理方法,通常我们只需要学习少量几个方法即可
小伙伴:"?!,就这样子?"
事实上,后期你可能连上述2个操作都很少用上。因为在 Python 中更倾向于构造新的序列,而非对序列原地操作。
当你后期学会了推导式之后,你就会发现用得最多的语法就是 if 和 for
你可能疑惑,为什么序列的处理很重要?
不管你学习什么的编程语言,不管你是应用开发还是普通的办公自动化学习,真正复杂的逻辑大部分来自于序列的处理。
比如一堆文件、每个文件中又会有一堆的数据。
而简单的单个数据,往往操作也是非常直白简单。
字典要不要在这个阶段学习?我建议是可以尝试了解,如果发现自己不能理解,那就跳过。因为后期总会有他的应用场景,那时候结合场景学习会更加轻松
学习分解问题的思维
经过上面2个阶段的学习,你会发现自己充其量只能解决小学加减乘除的简单问题,稍微复杂一点的问题你就毫无头绪。
此时你就陷入了另一个陷阱——一边思考逻辑一边写代码
多数入门书籍都不会教你这一点,因为这不是 Python 的特性,但他极其重要。
编程的本质是把现实逻辑用代码表达出来
而现实中,我们要完成一件比较复杂的事情时,都是先考虑整体流程,划分出多个子流程,最后才针对每个子流程考虑细节。
我的文章少不了案例。
考虑以下的现实场景:你希望从你家里书架上(有100多本)找出某作者的书。
你可能觉得这个事情非常简单,不就是从头开始,每本书都看看作者名字,符合就拿出来?
这个思考过程实际就是从整体到细节的过程:
- 首先,你会考虑从哪里开始找,总有个搜索方向。比如从书架左上角横向扫过每一行的书
- 其次,在没有开始找之前,你就决定找出一本书后,看封面的作者名字
- 最后,符合条件要拿出来,与原来的书区别开来
注意上述每一点的思考都是在你开始操作之前就决定的,这就是整体到细节的考虑。
你不会随手拿起一本书,然后才想到底怎么找作者名字?找到又要不要拿出来?这是非常反人类直觉的做法。
而 Python 初学者却经常使用这种反人类直觉编程——写到哪,想到哪
现在换成 Python 问题。
一个文件夹下有许多文本文件,每个文件相当于一本书,里面有书名、作者名字等信息:
下面是一个反直觉的写法。本文最后会给出自定义函数的做法,你能明显感受到2种写法的思维区别。
第一步:怎么能保证取出每一个文件,没有遗漏也不会重复取出?
经过网上搜索"python 文件夹文件",可以找到多种方式,我就随手用其中一种:
- import os
- for file in os.listdir(r'目标文件夹路径'):
- # file 就是每个文件的路径
- pass
第二步:有一个文件路径,怎么读取里面的内容?
网上搜索"python 读取文件",找到:
- with open('文件路径(记得带后缀)', 'r') as f:
- lines = f.readlines()
- # lines 是一个列表,每个元素就是文件中的一行内容
这一步其实是第一步里面的后续操作,于是:
- import os
- for file in os.listdir(r'目标文件夹路径'):
- # file 就是每个文件的路径
- with open(file, 'r') as f:
- lines = f.readlines()
第三步:文件中作者行内容是有"作者:"前缀,给你这一行,怎么提出里面的作者名字?
这是普通字符串操作:
- '作者:小明'.split(':')[1]
这应该是入门必需学会的方法,当然你也可以网上搜索"python 字符串分割"
于是,现在代码成这样(顺手把书名也取出):
- import os
- for file in os.listdir(r'目标文件夹路径'):
- with open(file, 'r') as f:
- lines = f.readlines()
- # 第三步
- book = lines[0].split(':')[1]
- author = lines[1].split(':')[1]
第四步:判断书名是不是我们要找的,符合要取出来
这就用上 if 判断和基本的序列操作:
- import os
- # 第四步
- results = []
- target = '小明'
- for file in os.listdir(r'目标文件夹路径'):
- with open(file, 'r') as f:
- lines = f.readlines()
- book = lines[0].split(':')[1]
- author = lines[1].split(':')[1]
- # 第四步
- if target==author :
- results.append(book)
现在,results 这个列表就是结果了
代码看似简单,但是,假如现在储存书籍的不再是文本文件,而是一个 Excel,你能一下子知道修改哪个地方吗?
初学者往往就在这种细节中受到挫折。明明我看懂别人写的,但是解决自己问题时却懵逼了
这是因为,Python 中有一个知识点能完美匹配"整体到细节"的过程!但初学者一般不怎么会用
一定要学习自定义函数
为什么编程语言基本都有自定义函数的特性?因为这符合我们解决问题的思维逻辑。
仍然解决前面的问题:
- # 第一步:从书架上取出书
- def get_file_paths(folder):
- pass
- # 第二步:看封面,得知书名与作者
- def get_book_message(file):
- pass
- return book,author
- # 第三步:看看是否符合
- def match(author):
- return author=='小明'
怎么感觉少了最后一步,"取出符合条件的书"?
看看整体调用:
- results=[]
- for file in get_file_paths(r'目标文件夹路径'):
- book,author = get_book_message(file)
- if match(author):
- results.append(book)
- "取出符合条件的书" 的逻辑包含在整体过程中
接下来,就是逐一实现每个自定义函数就可以。解决的思路与之前反直觉一样。
但是怎么感觉现在代码量比之前更多了?
的确如此,但是,如果现在信息保存在 excel 中,你就能马上知道在哪个函数修改,并且修改的负担变少了很多
为什么?
因为函数定义带有约束,看看上面 get_book_message 的函数定义,必需传入一个文件路径,必需返回元组(书名,作者)。
而整体流程和其他的每一步的函数是不管你怎么从一个文件路径得到这个元组,过程不重要,结果最重要
怎样进阶
上面的总结(针对入门):
- 语法学习简单为主(if、for)
- 基本序列要了解(列表、元组),但其对象操作方法不用特意记忆
- 学会分解问题的思维
- 学会自定义函数
实际上,点3才是最重要,其他点只是为他服务
因此,Python 的进阶仍然是围绕点3而展开。
比如,前面的例子中,整体流程代码中仍然包含了 "取出符合条件的书" 的逻辑,这其实不太合理。那么此时你就学习新的语法知识点,让你能简化整体流程代码。
这可能需要你学习:
- lambda
- 高阶函数的定义(专有名词很吓人,实际就是能把逻辑传递给函数参数)
又比如:
- # 第二步:看封面,得知书名与作者
- def get_book_message(file):
- pass
- return book,author
这个函数只是返回书名和作者名,如果还有其他的信息,那么整体流程的代码也很麻烦。
此时,你就需要学习面向对象的知识:比如定义类(其实用命名元组也行)
我认为一切按自己的实际需求出发选择性学习是最好的,因为有使用场景学起来最轻松。


















