身为数据分析师,大家对SQL可是再熟悉不过了。大多数人对常规的sql语法都已经熟练掌握,但是我发现在工作中许多同学join用的比较多,union all只有在纵向合并表格的时候用得到。如果仅仅是这样用,那么union all 的价值就被大打折扣了,今天给大家分享一下我在工作中经常用的union all技巧,希望可以帮到大家。
分组
用户分群对于数分同学来说可以说是家常便饭,这里我们来思考一个问题,如果一个用户可以同时存在多种属性,如何将用户全部分开呢?举例来说,下面有张表记录了用户收养宠物的信息,仅有两个字段,uid,pets
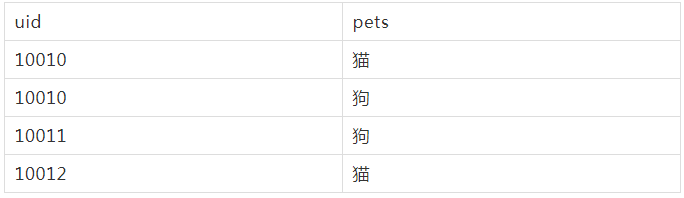
对用户分群,有些同学是这么做的:假如宠物仅有猫和狗两类,那么用户可以分为三类,仅养狗,仅养猫,既养狗又养猫
- --仅养狗
- select
- uid,'dog_only' as type from pets_table a where pets='狗'
- where not exists(select uid from pets_table b where pets='猫' and a.uid=b.uid)
- group by uid
- --仅养狗
- select
- uid,'cat_only' as type from pets_table a where pets='猫'
- where not exists(select uid from pets_table b where pets='狗' and a.uid=b.uid)
- group by uid
- --养狗又养猫
- select
- uid,'dog_cat' as type from pets_table a where pets='猫'
- where exists (select uid from pets_table b where pets='狗' and a.uid=b.uid)
- group by uid
如果除了养猫和养狗之外,还有仓鼠呢?
那么用户可以分为七类,分别为,仅养猫,仅养狗,仅养仓鼠,养猫和仓鼠,养猫和狗,养狗和仓鼠,三个都养。
首先通过上述例子我们总结一个规律
属性个数n与分组的数量m的关系满足:m=2^n-1。
可见分组的数量与属性个数之间存在指数关系,当属性个数大于三个后,如果使用上述sql进行分类将会非常复杂。有没有简单的方法呢?为了解释这个问题,我们用维恩图来表示上述案例
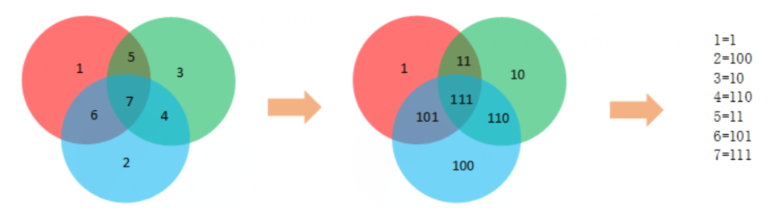
我们将图一中的七类用图二来表示,养猫标记为1(红色),养狗标记为10(绿色),养仓鼠标记为100(蓝色)。那么就可以根据叠加之后的值来对区分,叠加后的数字与组别对应关系
那么1=1;2=10;3=100;4=101;5=110;6=11;7=111
理论可行,那么在实际应用中应该怎么操作呢?
- with info
- (select
- uid,
- 1 as type
- from pets_table where pets='猫'
- union all
- select
- uid,
- 10 as type
- from pets_table where pets='猫'
- union all
- select
- uid,
- 100 as type
- from pets_table where pets='仓鼠')
- select uid,sum(distinct type) from info group by uid
经过上述处理之后,每个uid都被打上了类别标记。然后我们就可以根据标记判断用户最终所属的群组,用这种方法即使分组数量随着属性数量指数增加,但是我们的处理数据的复杂度随着属性数量增加线性增加。提高了效率,优化了逻辑。
我把它叫做量子叠加分组法,原因在于
一个量子系统可以处于不同量子态的叠加态上,当去观察它的时候,才会从多种状态坍缩到一种确定的状态
对比我们的分组模型
一个用户可能同时属于n个不同的组,当我们去sum他们并观察的时候,才能唯一确定他所在的分组
关联
什么?sql的关联表只认join?那你就是个outer了
接下来我来说一下union all怎么关联,以及union all关联的好处
假如我们是一个购物app,需要建立一张用户行为的宽表记录用户的核心行为。用户标识记作uid,商品唯一标识记作id,用户行为日志表为action,用户行为主要有三种,一,查看商品,标记detail;二,加入购物车,标记cart;三,购买,标记buy。我们需要计算的是一个uid每天三种行为的次数,具体如下:
uid detail_amunt cart_amount buy_amount
按照常规的方法,有的同学可能是这么算的
- select
- uid,
- count(distinct if(action='detail',id,null)) as detail_amunt,
- count(distinct if(action='cart',id,null)) as cart_amount,
- count(distinct if(action='buy',id,null)) as buy_amount
- from action
- group by uid
那好我们加点难度
这三个行为分别记录在三个表里面,分别为detail_table,cart_table,buy_table里面(不要告诉我可以把三张表union all起来再用上面的代码)
有些同学可能这么写
- select
- uid,
- count(distinct a.id),
- count(distinct b.id),
- count(distinct c.id)
- from
- detail_table a left outer join cart_table b
- on a.uid=b.uid
- left outer join buy_table c
- on a.uid=c.uid
- group by uid
这里有个默认的逻辑是,用户的加入购物车以及购买行为一定要先查看,否则无查看的加入购物车行为不能被计算在内。那么难度又来了,假如加入购物车它就是不需要查看呢?
有些同学是这么处理的,用今天活跃的用户作为主表再去关联后面三个行为的表就解决了
这样自然可以,这样计算需要的资源较多,逻辑并不清晰,而且把活跃且以上三个行为一个都没有的用户计算进来了。
下面我来推荐一个方式,可以一次性解决上述所有问题
- select uid,sum(detail_amunt),sum(cart_amount),sum(buy_amount)
- from
- (select
- uid,
- count(distinct if(action='detail_amunt',id,null)) as detail_amunt,
- 0 as cart_amount,
- 0 as buy_amount
- from detail_table
- group by uid
- union all
- select
- uid,
- 0 as detail_amunt,
- count(distinct if(action='cart_amount',id,null)) as cart_amount,
- 0 as buy_amount
- from cart_table
- group by uid
- union all
- select
- uid,
- 0 as detail_amunt,
- 0 as cart_amount,
- count(distinct if(action='buy_amount',id,null)) as buy_amount
- from buy_table
- group by uid)x
- group by uid
这种方式的好处在于,计算比较快,写法简单,逻辑清晰,通用性较好。究其本质其实是分别计算了三个指标,并用union all整合成了一个宽表
上述两个技巧比较通用,也能不错的简化问题,是我个人比较喜欢的方法。在你的工作中是否遇到过可以用上述方法解决的问题呢?