本文转载自微信公众号「石杉的架构笔记」,作者崔皓。转载本文请联系石杉的架构笔记公众号。
MySQL是常用的数据库存储应用,我们利用它存储信息、查询信息、处理事务。特别是为了提高可用性会用到事务一致性、主从复制、数据恢复等功能。我们在使用这些功能的时候,是否想过其背后有哪些原理和机制在支撑?今天我们聚焦redo log和binlog两个MySQL的日志机制,以及它们是如何配合提高MySQL存储可靠性的。今天会学到以下内容:
- Redo log
Redo log 解决了什么问题?
Redo log的执行流程
Redo log的写入方式
Redo log记录形式
- Binlog
a.Binlog解决了什么问题?
b.Binlog的日志格式
- Redo log 与Binlog的区别与合作
Redo log
1.Redo log 解决了什么问题?
MySQL应用中处理事务是一个重要的任务,而在事务处理的四个特性中(ACID),存在一个持久性(Durability),它表示在事务执行过程中,对数据的所有改动都必须在事务成功结束前保存至某种物理存储设备中。
换句话说,只要事务提交成功,那么对数据库做的修改就被永久保存下来了,不可能因为任何原因再回到原来的状态。那么为什么要在MySQL中考虑事务持久性的问题呢?假设这么一种场景,当数据存储的事务正在执行但是数据还没有保存的时候,数据库宕机了,那么这些没来得及存储到磁盘的数据就丢失了,如果此时有一种机制能够记录这个事务的操作,当数据库服务恢复的时候,运行记录的操作那么这些没有来得及存储的数据就能够正确保存了。
Redo log 就是通过这种手段来实现事务持久性的。上面的场景中是数据库服务器宕机,如果发生其他故障导致尚有脏页未写入磁盘的场景,也是可以通过Redo log恢复的。
1.Redo log的执行流程
了解了为什么使用redo log 以后再来看看其执行流程,如图1 所示:
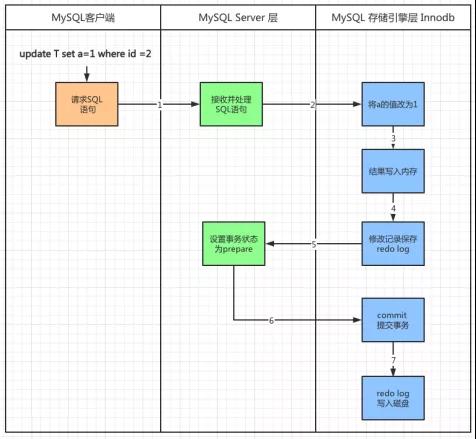
图1 redo log执行流程
该泳道图由MySQL客户端、MySQL Server 层和MySQL 存储引擎层组成,由于redo log是在Innodb存储引擎中使用的,这里假设存储引擎就是Innodb。由于MySQL Server 层主要负责SQL语句的分析、优化和执行工作,而MySQL存储引擎层主要负责存储工作,redo log 也运行在这一层。
跟随图中的序号来看看redo log 的运行流程。
- 1. 从MySQL客户端请求语句“update T set a=1 where id=2”,并发现MySQL Server 层。
- 2. 接收到SQL请求以后MySQL Server 层会对其进行分析、优化、执行等处理工作,将生成的SQL执行计划发到存储引擎层执行。
- 3. 存储引擎层将“a修改为1”的这个操作记录到内存中。
- 4. 记录到内存以后会修改redo log 的记录,会在添加一行记录,其内容是“需要在哪个数据页上做什么修改”。
- 5. 此后,将事务的状态设置为prepare ,说明已经准备好提交事务了。
- 6. 等到MySQL Server 层处理完事务以后,会将事务的状态设置为commit,也就是提交该事务。
- 7. 在收到事务提交的请求以后,redo log 会把刚才写入内存中的操作记录写入到磁盘中,从而完成整个日志的记录过程。
2Redo log的写入方式
从上面介绍的Redo log 的执行流程中不难看出,redo log在写入磁盘之前会先将内容写到内存中。因此,redo log的写入包括两部分内容:一部分是内存中的日志缓冲,称作redo log buffer;另一部分是磁盘日志文件,称作 redo log file。MySQL每执行一条DML语句,先将更新记录写入redo log buffer ,然后再写入redo log file。我们将这种先写日志,再写磁盘的方式称为 WAL(Write-Ahead Logging)技术。
如图2所示:
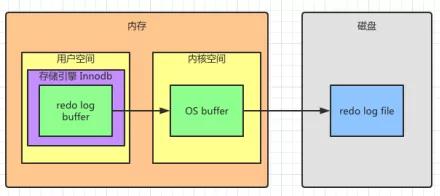
图2 redo log 写入方式
顺着箭头的方向从左往右看,日志最开始会写入位于存储引擎Innodb的redo log buffer中,这个也就是所谓的用户空间(user space),然后再将日志保存到操作系统内核空间(kernel space)的缓冲区(OS buffer)中。
最后,再从OS buffer写入到磁盘上的redo log file中,完成写入操作,这个写入磁盘的操作也称作“刷盘”。
了解了redo log的写入方式之后,我们发现主要完成的操作是redo log buffer 到磁盘的redo log file的写入过程,其中需要经过OS buffer进行中转。关于redo log buffer写入redo log file的时机,可以通过 参数innodb_flush_log_at_trx_commit 进行配置,各参数值含义如下:
参数为0的时候,称为“延迟写”。事务提交时不会将redo log buffer中日志写入到OS buffer,而是每秒写入OS buffer并调用写入到redo log file中。换句话说,这种方式每秒会发起写入磁盘的操作,假设系统崩溃,只会丢失1秒钟的数据。
参数为1 的时候,称为“实时写,实时刷”。事务每次提交都会将redo log buffer中的日志写入OS buffer并保存到redo log file中。其有点是,即使系统崩溃也不会丢失任何数据,缺点也很明显就是每次事务提交都要进行磁盘操作,性能较差。
参数为2的时候,称为“实时写,延迟刷”。每次事务提交写入到OS buffer,然后是每秒将日志写入到redo log file。这样性能会好点,缺点是在系统崩溃的时候会丢失1秒中的事务数据。
3.Redo log记录形式
redo log是通过循环写入的方式保存的。
如图3所示:
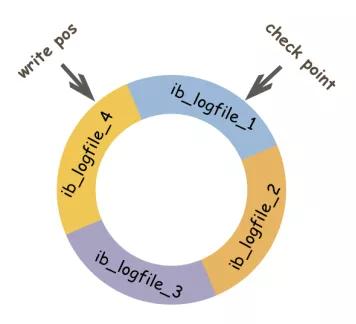
图3 redo log 循环写入(素材来源于互联网)
redo log buffer(内存中)是由首尾相连的四个文件组成的,它们分别是:ib_logfile_1、ib_logfile_2、ib_logfile_3、ib_logfile_4。
写入的方式也是从文件的头部开始写入(假设),每增加一条日志记录就往文件的尾部添加,直到把四个文件写满,再回到文件开头的地方(ib_logfile_1)继续写,继续写的时候会覆盖之前的记录。
图3中write pos表示当前写入记录位置(写入磁盘的数据页的逻辑序列位置),check point表示刷盘(写入磁盘)后对应的位置。write pos到check point之间的部分用来记录新日志,也就是留给新记录的空间。check point到write pos之间是待刷盘的记录,如果不刷盘会被新记录覆盖。
当write pos指针追上check point的时候(也就是新记录即将覆盖老记录的时刻),会推动check point向前移动,也就是催促其将记录刷到磁盘中,这样好空出位置给新记录。
当redo log buffer根据check pint刷盘以后,针对Innodb引擎而言是以页为单位进行磁盘存储,一个事务可能一个或者多个数据页,每个页面修改多个字节。当重新启动Innodb存储引擎的时候,是会进行恢复操作。因为redo log记录的是数据页的物理变化,恢复的速度比逻辑日志(binlog)要快。
在重启Innodb时,首先会检查磁盘中数据页的逻辑序列位置,如果数据页的逻辑序列位置小于日志中的位置,则会从check point开始恢复。如果宕机的时候,正处于check point的刷盘过程中,且数据页的刷盘进度超过了日志页的刷盘进度,此时会出现数据页中记录的逻辑序列位置大于日志中的逻辑序列位置,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。
Binlog
4.Binlog 解决了什么问题?
对于MySQL数据库而言增加数据的可靠性是一个永恒的话题,其中主从复制和数据恢复就是增强数据可靠性的两个重要功能。Binlog就是为实现这两个功能而设置的。
主从复制的场景中在Master 端会开启binlog ,然后将 binlog 发送到各个Slave 端,Slave 端重放binlog 从而达到Slave 端的数据和Master端的数据保持一致。在数据恢复场景,通过使用mysqlbinlog 工具以及对应的binlog 将数据恢复到指定的时间点。那么可以把binlog 解决的问题总结为两点,就是主从复制和数据恢复。
5.Binlog的日志格式
从记录方式上来看binlog通过追加的方式记录,当日志文件尺寸大于给定值后,后续的日志会记录到新的文件上。这个与 redo log 的循环记录产生鲜明的对比,同时binlog 可通过配置参数 max_binlog_size 设置每个binlog 文件的大小。
从日志格式来看,Binlog 日志有三种格式,分别为 STATMENT 、 ROW 和 MIXED 。
在 MySQL 5.7.7 之前,默认的格式是 STATEMENT , MySQL 5.7.7 之后,默认值是 ROW 。日志格式通过 binlog-format 指定。三种格式的定义和优缺点如下:
lSTATEMENT:基于SQL语句的复制(statement-based replication, SBR),记录的是修改的SQL语句。
n 优点:由于不用记录每行日志的更改,因此日志文件小,减少了日志量,节约了IO,提高了性能;
n 缺点:准确性差,对一些系统行数不能准确复制,例如:now()、uuid()。
lROW:基于行的复制(row-based replication, RBR),不记录每条SQL语句的上下文信息,只记录每行实际数据的变更 。
n 优点: 准确性强,能够准确复制数据的变更。
n 缺点: 产生的日志文件较大,从造成较大的网络IO和磁盘IO。尤其是alter table的时候会让日志暴涨。
lMIXED:基于STATMENT和ROW两种模式的混合复制( mixed-based replication, MBR ),默认使用STATEMENT模式保存,STATEMENT模式无法复制的操作使用ROW模式。
n 优点:准确性强、文件大小适中。
n 缺点:有可能发生主从不一致的现象。
在MySQL中可以通过“show binlog events” 命令查看binlog日志的事件。如代码段1 所示,这里通过上述命令查看“mysql-bin.000002”文件中的binlog 日志情况。
- mysql> show binlog events in 'mysql-bin.000002';
代码段1
如图4所示:
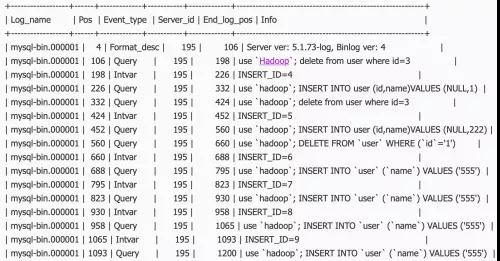
图4 显示binlog 日志内容
通过上述命令展示对应binlog 日志事件,从左到右展示如下:
- Log_name:描述存放binlog日志的文件名字。
- Pos:描述记日志的开始位置。
- Event_type:描述时间类型,例如:查询、插入等。
- Server_id:对应数据库服务器的ID。
- End_log_pos:日志结束的位置。
- Info:执行的SQL语句。
上面是查看日志的事件,这里也可以通过mysqlbinlog命令可以查看binlog的内容。如代码段2 所示,通过mysqlbinlog 命令查看mysql-bin.000002的内容。
- mysql> mysqlbinlog 'mysql-bin.000002';
代码段2
如图5所示:
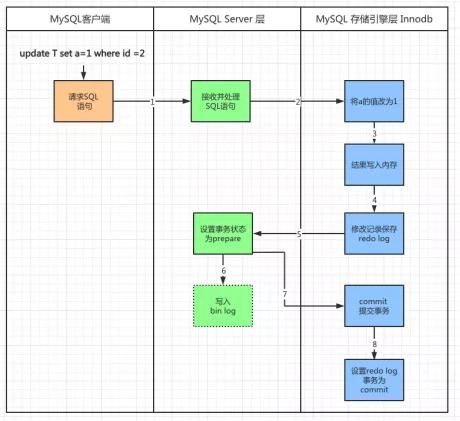
图5 binlog 日志的内容
我们将上述查看命令返回的结果截取其中一部分给大家讲解,我们从上往下看:
- “at 294”说明“事件”的起点,也就是从文件的第294字节开始。
- “120330 17:54:46”表示事件发生的时间戳信息。
- “end_log_pos 388 ”表示日志记录结束的字节位置,也就是在文件的第388 字节截止。
- "exec_time=28",表示事件执行花费的时间。
- “error_code=0”,表示错误代码为0,也就是没有错误。
- “server id 1”,表示服务器的标识id。
需要注意的是binlog的事务提交,是一次性将事务进行提交(一个事物包含一个或者多个SQL语句)。而redo log可以在事务开始之后就开始逐步写入磁盘。因此对于事务的提交,即便是较大的事务,提交(commit)都是很快的,但是在开启了binlog的情况下,对于较大事务的提交,可能会变得比较慢。因为binlog事务提交是一次性写入。
6.Redo log与Binlog区别与合作
前面介绍了redo log 和 binlog,那么这里总结一下它们之间的区别如下表格。
由 binlog 和 redo log 的区别可知:binlog 日志只用于归档,但仅仅依靠 binlog 是没有 crash-safe 能力的。但只有 redo log 也不行,因为 redo log 是 InnoDB 特有的,且日志记录落盘后会被覆盖掉。因此需要 binlog 和 redo log 二者同时记录,才能保证当数据库发生宕机重启时,数据不会丢失。
那么如何让两个日志保持一致呢?
如图5所示:

图5 redo log 和 binlog 事务保持一致
该图沿用了图1 的例子,稍微不同的是加入了一个步骤。看到绿色虚线框的部分加入了写入binlog的步骤。当事务为prepare状态的时候,在commit事务之间,会先将日志保存到binlog当中,然后再提交给 Innodb中的redo log,最后完成commit的操作。
再聚焦于redo log 和 binlog 在提交成功和失败两种情况中的状态变化。
如图6 所示:
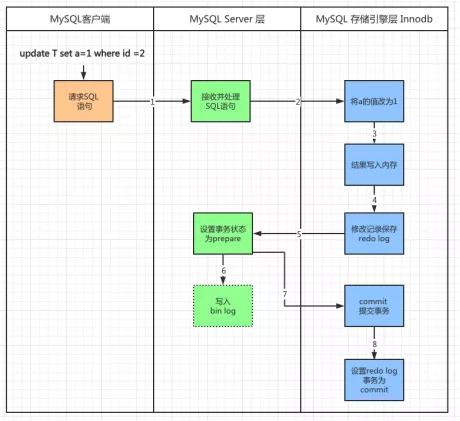
图6 redo log 和 binlog 状态变迁图(素材来源于互联网)
从上往下看,先看红色线条的部分,当写入redo log并且事务状态为prepare的时候,如果写入成功直接写入binlog,如果binlog 写入也成功,redo log 状态设置为commit。如果写入binlog的时候失败了,沿着红色箭头向上回滚此次事务。再回到最上面,看绿色箭头的部分,如果写入redo log 状态为prepare 此时写入失败,不再写入binlog,事务直接回滚。
可以看出这里为了保持两个日志的一致性,使用了两段提交。redo log和binlog是两个独立的逻辑,如果不用两阶段提交,要么就是先写完redo log再写 binlog,或者先写binlog再写 redo log。看看这两种方式会有什么问题:
- 先写redo log后写binlog。假设在redo log写完,binlog还没有写完的时候,也就是说binlog 没有事务中更新的语句。此时MySQL重启并使用binlog来恢复数据,由于之前更新的语句没有保存数据库就会少了一次更新,导致数据的不一致。
- 先写binlog后写redo log。如果在binlog写完之后服务器宕机了,由于redo log还没写,也就是数据还没有写到数据库中。但是binlog里面已经记录了,意思是把本来不应该更新的数据记录到更新里面了。此时MySQL数据库重启,就会把这条不该更新的数据更新到数据库中,导致数据的不一致。
总结
本文通过提高MySQL可靠性入手,分别介绍redo log 和binlog的实现机制,再合并讲解两者的区别与合作。Redo log部分首先提出redo log 的目的是解决事务提交的持久性,作为Innodb存储引擎特有的日志模式redo log 的执行使用了两步提交。在写入方式上面会先从redo log buffer 写入到OS buffer,最后写盘到 redo log file中。
其对应了三种写入配置,分别是延迟写、实时写实时刷和实时写延迟刷。在记录形式方面由四个文件循环写入的方式进行,通过write pos 和check point 推进写入的进度。转眼看binlog,它是为了主从复制和数据恢复而生的。有三种日志格式分别是STATEMENT、ROW、MIXED。
日志内容主要记录了开始的记录点、结束的记录点、记录发生的时间戳、记录花费的时间以及具体执行的事件操作。在介绍完两个日志以后对其区别进行了阐述,并且提出两者结合可以保证数据库宕机时,数据不丢失。介绍二者在事务处理流程中是如何合作的,并且列举了两个场景描述了redo log 和binlog 进行两段提交的必要性。