













本文转载自微信公众号「小姐姐味道」,作者姐养狗2号 。转载本文请联系小姐姐味道公众号。
这些年写Java写多了,感觉Java是越来越丑。尤其是在玩了TypeScript之后,看到Java代码总有一股想吐的感觉。这种思想的转变,从侧面上证明了,我并不是一个专一的人。
因为我是一条狗。
喜新厌旧,是我的本性,即使我把自己表现的很纯洁。
按理说,牛x的人物并不需要关注语言层面这种较低级的问题。但是,无论是什么语言,各种属性拷贝,是在工程上绕不开的问题。比如折腾人的VO、BO、DTO、DO等。
项目中的代码,有六成,是在做这些无用的转换和各种数据验证。这个比例是我瞎诌的,但也相差无几。
在Java中,有三种方式来处理这些属性拷贝:
- 直接硬编码,把代码硬怼上去
- 使用各种BeanUtils,通过反射完成赋值
- 使用类似MapStruct的工具,直接在编译期完成
其实嘛,哪一种都有利弊,有些东西虽然香,但实际用起来,还是要思量一下。个个打扮的花枝招展的,都是外在的皮囊。
本文主要介绍Mapstruct的使用,并从这香喷喷的工具中,闻一下其中变馊的味道。
1. 如何使用?
照例,需要在pom中加入依赖包,我们这里用的是1.4.1.Final版本。
- <dependency>
- <groupId>org.mapstruct</groupId>
- <artifactId>mapstruct</artifactId>
- <version>${org.mapstruct.version}</version>
- </dependency>
这还没完,还需要在pom中的build部分,增加一个插件。搞这么复杂,是因为它的原理和lombok是一样的,同样通过APT在编译器实现的。

这意味着,它的代码,在编译期就完成了。不需要反射,所以效率就和直接写get、set,是一样的。
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-compiler-plugin</artifactId>
- <version>3.8.1</version>
- <configuration>
- <source>1.8</source>
- <target>1.8</target>
- <annotationProcessorPaths>
- <path>
- <groupId>org.mapstruct</groupId>
- <artifactId>mapstruct-processor</artifactId>
- <version>${org.mapstruct.version}</version>
- </path>
- <path>
- <groupId>org.projectlombok</groupId>
- <artifactId>lombok</artifactId>
- <version>1.18.16</version>
- </path>
- <path>
- <groupId>org.projectlombok</groupId>
- <artifactId>lombok-mapstruct-binding</artifactId>
- <version>0.2.0</version>
- </path>
- </annotationProcessorPaths>
- </configuration>
- </plugin>
这时候,我们就可以使用它提供的注解,方便的进行属性拷贝了。
- @Mapper(nullValueCheckStrategy = NullValueCheckStrategy.ALWAYS)
- public interface Transform {
- Transform T = Mappers.getMapper(Transform.class);
- Member fromMemberEntity(MemberEntity entity);
- MemberEntity fromMember(Member member);
- }
上面是一段示例代码。Mapper注解,标志着这是一个类型转换工具(对象映射器),它提供了很多策略供我们选择。直接写接口文件,并不需要做一些额外的动作,mapstruct就知道你要干什么!
在传统的编程中,如果Member的属性非常的多,我们需要手工完成这个过程,代码会非常的多。
使用Mapperstruct之后,这部分重复的劳动,工具都替我们做了。
瞧瞧下面这张图!
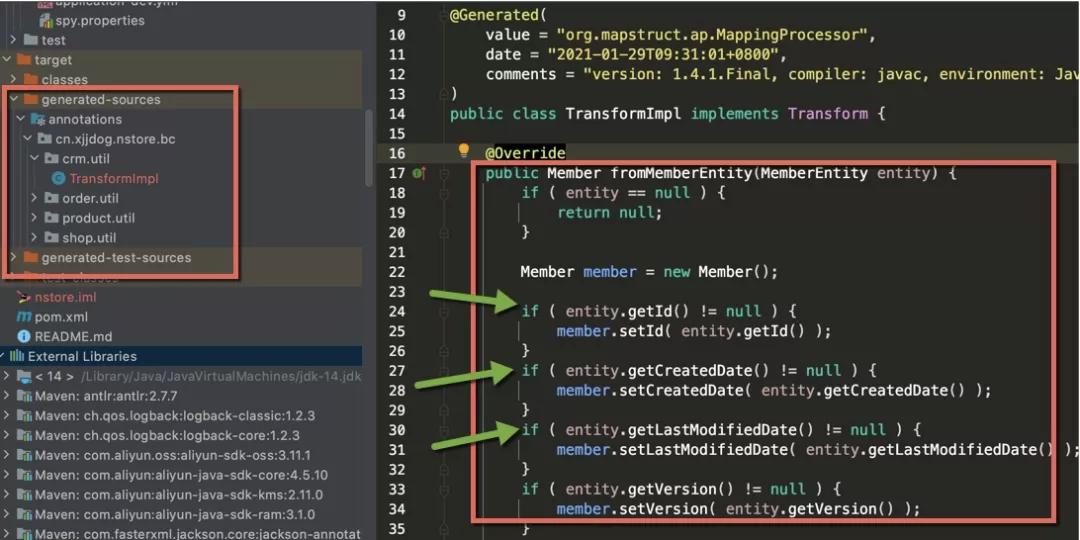
上面的图表明了,代码在target下的generated-source目录下生成,这就是我们上面添加的插件的功劳;代码的内容,其实就是一些非空判断和get、set等。相同字段名相同类型的属性,将会无差别的拷贝过去。
如果你的bean属性非常的多,这个工具会让你的代码由几百行,变成几行!
2. 与其他方式比较
那mapstruct有什么优势么?为什么不直接使用BeanUtils?它们的效果一样的啊,而且后者各种类库都有提供。
主要原因,就是效率问题。
BeanUtils是通过反射实现的,效率肯定很低;而mapstuct是基于APT实现的,没有性能损耗。
BeanUtils的属性拷贝,在判断空值和不同类型的属性时,有很多障碍,会歇菜;而mapstruct有非常灵活的策略和转化方式,自定义性比较强(后面会谈到)。
3. 复杂场景
那下面我们就来看一个复杂的场景。
如果你的bean中,只有一些普通的属性,那么使用mapstruct,就是如丝般的顺滑。但总有一些异常情况,需要使用更高级的处理方式。
假设我想要由Unit转化为ProductUnitEntity,但其中有个字段measureType它们的类型不一样,我们就可以使用Mappings注解完成这个转化。
- @Mappings({
- @Mapping(source = "measureType.value", target = "measureType")
- })
- ProductUnitEntity fromUnit(Unit v);
编译后的代码如下所示。有了source和target,就可以实现比BeanUtils更加牛x的行为。你甚至可以通过dateFormat做一些日期转化之类的。
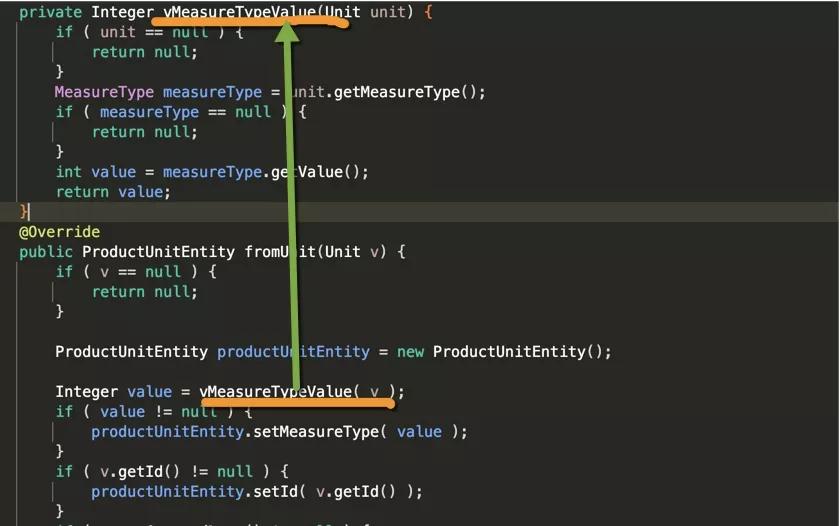
其实,上面的measureType是一个枚举类型。如何将普通的类型转化为枚举类型呢?我们只需要提供一个default方法就ok了。mapstruct会判断参数类型和返回值,所以说方法的名称可以是任何合法的值。
- default Unit.MeasureType measureTypeIntegerToDomain(Integer value) {
- for (Unit.MeasureType s : Unit.MeasureType.values()) {
- if (s.getValue() == value) {
- return s;
- }
- }
- return null;
- }
那mapstruct能实现List之间的转化么?也是可以的。下面两行代码,就能够自动的补充for循环,让你的代码更加简洁。
- List<StockKeepingUnit> fromSkuEntityList(List<StockKeepingUnitEntity> v);
- List<StockKeepingUnitEntity> fromSkuList(List<StockKeepingUnit> v);
End那么问题来了。
既然这么好的东西,那为什么现在的很多项目,都不用mapstruct,甚至连BeanUtils都不用,直接手工在那里get、set呢?
一种原因是,这些工具会大幅减少代码量。mapstruct+hibernate-validate,一个管转化,另一个管验证,简直就是以代码行数论天下的公司的噩梦。绩效会降低的!
另一种原因就是,使用这些工具,并 不利于项目的重构 。假如你在DTO里把a字段改成了b字段,mapstruct都贴心的为你忽略了这些变化。你的项目代码并不会提示错误,风险将直接带到运行时。
而使用get、set的方式,除了代码量变的非常多以外,唯一的风险就是开发人员忘记了为某个新增的字段赋值。
在这种情况下,机器干的活,并不一定比人类可靠。所以使用mapstruct有一个大的前提:你的团队,能够通过约定,不给变量乱起名字,不乱重构。如此,才能发挥它的价值。
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。我的个人微信xjjdog0,欢迎添加好友,进一步交流。

















