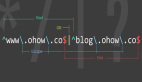
公司使用的markdown解析类库一直有一些解析上的问题,最近给fix了。而markdown解析主要是对正则表达式的使用。中间恶补了一下相关知识,在此梳理一下。
什么是正则表达式
正则表达式就是用一个“字符串”来描述一个特征,然后去验证另一个“字符串”是否符合这个特征。简单的一个例子:用字符串”a”来验证字符串s是否是”a”,形如s.match(“a”)。概括来说有以下作用:
- 验证字符串是否符合指定特征,比如验证是否是合法的邮件地址。
- 查找字符串,从一个长的文本中查找符合指定特征的字符串,比查找固定字符串更加灵活。
- 替换字符串,比普通的基于字符串的替换更灵活。
基本规则
普通字符
字母、数字、汉字、下划线、以及后续没有特殊定义的标点符号,都是”普通字符”。表达式中的普通字符,在匹配一个字符串的时候,匹配与之相同的一个字符。如:表达式 “a”,在匹配字符串 “abcde” 时,匹配到的内容是:“a”。
转义字符
一些不便书写的字符,采用在前面加 “\” 的方法。常见的如:
- \r: 回车
- \n: 换行符
- \t: 制表符
- \: “\” 本身
此外,还有其他再正则中有特殊用处的标点符号,在前面加 “\”后,代表该符号本身。如:^, “ 字符,需要写成 “\^” 和 “$”。如
- \^: 匹配^符号本身
- \$: 匹配$符号本身
- \.: 匹配小数点. 本身
其匹配规则和普通字符串是一样的,如“\^”匹配“a^bc”中的“^”。
‘多种字符’匹配
- \d:任意一个数字,0~9 中的任意一个
- \w:任意一个字母或数字或下划线,也就是 A~Z,a~z,0~9,_ 中任意一个
- \s:包括空格、制表符、换页符等空白字符的其中任意一个
- .:小数点可以匹配除了换行符以外的任意一个字符
如:表达式 “\dtest\d”匹配”1test2”。
除了正则自带的“多种字符”匹配外,还可以通过中括号[]来自定义。
- 使用[ ]包含一系列字符,能够匹配其中任意一个字符。
- 用 [^ ]包含一系列字符,则能够匹配其中字符之外的任意一个字符。
如:[123]匹配 “1”或”2”或“3”;[^abc]匹配 “a”、”b”、”c” 之外的任意一个字符。
这里需要注意的是,在使用[]时,只有会改变字符组含义的才需要转义,
- 反斜线必须转义
- 方括号必须转义
- 「^」在首和「-」在中必须转义
其他情况即使是特殊字符也不需要转义,如:
- [aeiou]
- [$.*+?{}()|]
- [abc^123-]
匹配次数
“次数修饰”放在”被修饰的正则表达式”后边,可以匹配多次。如:
- {n}: 表达式重复n次,比如:“\d{2}” 相当于 “\d\d”。
- {m,n}:表达式至少重复m次,最多重复n次,比如:“a{1,3}”可以匹配 “a”或”aa”或”aaa”。
- {m,}: 表达式至少重复m次,比如:“\d{2,}”可以匹配 “12”,“123”,“12345678”。
- ?: 匹配表达式0次或者1次,相当于 {0,1},比如:“a[b]?”可以匹配”a”,“ab”。
- +: 表达式至少出现1次,相当于 {1,},比如:“a+”可以匹配”a”,“aa”,“aaa”。
- *: 表达式不出现或出现任意次,相当于 {0,},比如:”ab“可以匹配 “a”、”ab”、”abb”。
特殊符号
- ^: 与字符串开始的地方匹配,不匹配任何字符,这里如果使用(?m)模式,则匹配每一行的开始。如:“^aaa”无法匹配 “xxxaaaxxx”,可以匹配”aaaxxx”。
- $: 与字符串结束的地方匹配,不匹配任何字符,这里如果使用(?m)模式,则匹配每一行的结束。如:“aaa$”无法匹配“xxxaaaxxx”, 可以匹配“xxxaaa”。
- \b:匹配一个单词边界,也就是单词和空格之间的位置,不匹配任何字符。它与 “^”、”$“ 类似,本身不匹配任何字符,但是它要求它在匹配结果中所处位置的左右两边,其中一边是 “\w” 范围,另一边是 非“\w” 的范围。。如:“.\b.”匹配“@@abc”的“@a”。
此外,还有一些符号可以影响表达式内部的子表达式之间的关系:
- |: 左右两边表达式之间“或”关系,匹配左边或者右边。
- (): 在被修饰匹配次数的时候,括号中的表达式可以作为整体被修饰;取匹配结果的时候,括号中的表达式匹配到的内容可以被单独得到。如:”(ab\s*)+“匹配”hi, ab ab ab”中的“ab ab ab”。
高级规则
贪婪与非贪婪匹配
在使用修饰匹配次数的特殊符号时,有几种表示方法可以使同一个表达式能够匹配不同的次数,比如:“{m,n}”, “{m,}”, “?”, “*”, “+”,具体匹配的次数随被匹配的字符串而定。这种重复匹配不定次数的表达式在匹配过程中,总是尽可能多的匹配。
比如,文本 “axxxaxxxa”,”(a)(\w+)“,其中”\w+“会匹配”xxxaxxxa”,”(a)(\w+)(a)“则会匹配”xxxaxxx”。由此可见,”\w+“ 在匹配的时候,总是尽可能多的匹配符合它规则的字符。
虽然第二个举例中,它没有匹配最后一个 “a”,但那也是为了让整个表达式能够匹配成功。同样的,带 ”“ 和 ”{m,n}“ 的表达式都是尽可能地多匹配,带 ”?“ 的表达式在可匹配可不匹配的时候,也是尽可能的匹配。这种匹配原则就叫作”贪婪”模式。
非贪婪模式则是指的在修饰匹配次数的特殊符号后再加上一个 “?” 号,可以使匹配次数不定的表达式尽可能少的匹配,使可匹配可不匹配的表达式,尽可能的不匹配。
这种匹配原则也叫作 “勉强” 模式。如果少匹配就会导致整个表达式匹配失败的时候,与贪婪模式类似,非贪婪模式会最小限度的再匹配一些,以使整个表达式匹配成功。如,文本 “axxxaxxxa” ,“(a)(\w+?)”,其中”\w+“只会匹配一个“x”。
反向引用
表达式在匹配时,表达式引擎会将小括号 “()” 包含的表达式所匹配到的字符串记录下来。在获取匹配结果的时候,小括号包含的表达式所匹配到的字符串可以单独获取。当用某种边界来查找,而所要获取的内容又不包含边界时,必须使用小括号来指定所要的范围。如:“<div>(.*?)</div>“即获取div标签内部的内容。
这里小括号包含的正则表达式所匹配到的字符串不仅仅是在匹配结束后才可以使用,在匹配过程中也可以使用。表达式后边的部分,可以引用前面括号内的子匹配已经匹配到的字符串。引用方法是 “\” 加上一个数字。”\1” 引用第1对括号内匹配到的字符串,”\2” 引用第2对括号内匹配到的字符串,以此类推,而如果一对括号内包含另一对括号,则外层的括号先排序号。换句话说,哪一对的左括号 “(” 在前,那这一对就先排序号。
例如:表达式 “(‘|’)(.*?)(\1)“ 在匹配 ” ‘Hello’, “World” “ 时,匹配结果是:成功;匹配到的内容是:” ‘Hello’ “。再次匹配下一个时,可以匹配到 ” “World” “。
预搜索
如前面所讲”^“、”$“、”\b”字符有一个共同点,就是:它们本身不匹配任何字符,只是对 “字符串的两头” 或者 “字符之间的缝隙” 附加了一个条件。同样的,正则中提供了其他基于此原理的机制,来实现预搜索。
- 正向预搜索:”(?=xxxxx)“,”(?!xxxxx)”
格式:”(?=xxxxx)“,在被匹配的字符串中,它对所处的 “缝隙” 或者 “两头” 附加的条件是:所在缝隙的右侧,必须能够匹配上xxxxx这部分的表达式,不影响后边的表达式去真正匹配这个缝隙 之后的字符。如:“Mac (?=book|air)” 在匹配 “Mac pro, Mac air” 时,将只匹配 “Mac air” 中的 “Mac”。
格式:“(?!xxxxx)”,所在缝隙的右侧,必须不能匹配 xxxxx 这部分表达式。如:“hello(?!\w)” 在匹配字符串 “hello,helloworld”时,匹配 hello”。这里使用 “(?!\w)” 和使用 “\b” 效果一样。
- 反向预搜索:“(?<=xxxxx)”,“(?<!xxxxx)”
和正向预搜索类似,反向预搜索要求的条件是:所在缝隙的 “左侧”,两种格式分别要求必须能够匹配和必须不能够匹配指定表达式,而不是去判断右侧。与 “正向预搜索” 一样的是:它们都 是对所在缝隙的一种附加条件,本身都不匹配任何字符。
其他通用规则
- 可以使用 “\xXX” 和 “\uXXXX” 表示一个字符(”X” 表示一个十六进制数)
- \xXX: 编号在 0-255 范围的字符,如:空格可以使用 “\x20” 表示
- \uXXXX: 任何字符可以使用 “\u” 再加上其编号的4位十六进制数表示,比如:“\u4E2D”
- 在表达式 “\s”,”\d”,”\w”,”\b” 表示特殊意义的同时,对应的大写字母表示相反的意义
- \S: 匹配所有非空白字符
- \D: 匹配所有的非数字字符
- \W: 匹配所有的字母、数字、下划线以外的字符
- \B: 匹配非单词边界,即左右两边都是 “\w” 范围或者左右两边都不是 “\w” 范围时的字符缝隙
- 括号“()”内的子表达式,如果希望匹配结果不进行记录供以后使用,可以使用 “(?:xxxxx)”格式。如:表达式 “(?:(\w)\1)+” 匹配 “a bbccdd efg” 时,结果是 “bbccdd”。括号 “(?:)” 范围的匹配结果不进行记录,因此 “(\w)” 使用 “\1” 来引用。
- 常用的表达式属性设置包括:Ignorecase、Singleline、Multiline、Global
- Ignorecase: 默认情况下,表达式中的字母是要区分大小写的。配置为 Ignorecase 可使匹配时不区分大小写。有的表达式引擎,把 “大小写” 概念延伸至 UNICODE 范围的大小写。
- Singleline: 默认情况下,小数点 “.” 匹配除了换行符(\n)以外的字符。配置为Singleline可使小数点可匹配包括换行符在内的所有字符。
- Multiline: 默认情况下,表达式 “^” 和 “$” 只匹配字符串的开始1和结尾4位置。如:1xxxxxxxxx2\n 3xxxxxxxxx4
配置为 Multiline 可以使 “^” 匹配1外,还可以匹配换行符之后,下一行开始前3的位置,”$“ 匹配4外,还可以匹配换行符之前,一行结束2的位置。使用(?m)可以设置为Multiline模式。如”(?m)^\n +“。
- Global: 主要在将表达式用来替换时起作用,配置为Global表示替换所有的匹配。
提示
- 如果要求表达式所匹配的内容是整个字符串,而不是其中的一部分,可以在表达式的首尾使用 “^” 和 ““ 要求整个字符串只有数字。
- 如果要求匹配的内容是一个完整的单词,而不会是单词的一部分,那么在表达式首尾使用 “\b”,如:使用 “\b(if|while|…)\b” 来匹配程序中的关键字。
- 表达式不要匹配空字符串。否则会一直得到匹配成功,而结果什么都没有匹配到。
- 能匹配空字符串的子匹配不要循环无限次。如果括号内的子表达式中的每一部分都可以匹配0次,而这个括号整体又可以匹配无限次,那么匹配过程中可能死循环。
- “|” 的左右两边,对某个字符应该只有一边可以匹配,以防止”|“两边的表达式因为交换位置而有所不同。
- 要合理选择贪婪模式与非贪婪模式,如. 与 .?的区别使用。