这几年随着AI的浪潮席卷而来,各行各业陆续上演着AI取代人类工作的戏码,好像凡事只要套上AI再困难的事情都能解决,所以究竟AI到底是什么?今天就让我用一篇文章带你快速了解这人类长久以来的梦想技术——AI。
一个有趣的问题和游戏
AI全名Artificial Intelligence,通常翻译为人工智慧或人工智能,是人类长久以来的梦想技术,早在1950年天才斜杠科学家艾伦图灵就在他的论文《计算机与智能》中第一次提到一个有趣的问题“机器能思考吗?”从此开启了AI这个新领域,也引发了人们对AI的无限想象。
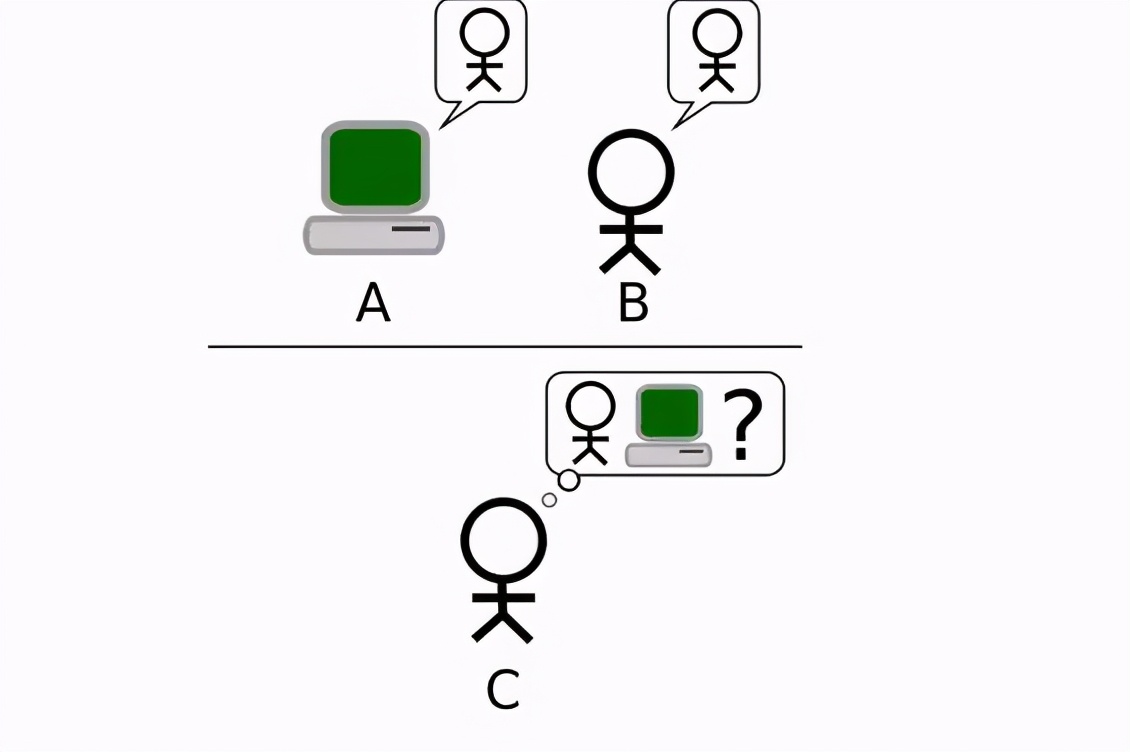
根据图灵的想法,要判断一台机器能不能思考,必须通过一个所谓的模仿游戏,由于这个游戏太过经典而被后人称为图灵测试,在这个测试当中由一个发问人C同时对不同房间内的机器A与人类B持续发问,只要C无法分辨AB谁是计算机谁是人类,我们就可以宣称房间内的机器是一台能思考的机器。
从穷举到分类
从那之后人们花了很长一段时间研发,试图制造出能通过图灵测试的机器或算法,在1997年,当时最先进的IBM深蓝计算机击败西洋棋世界冠军,尽管看似很厉害,殊不知这背后也只是让计算机穷举所有可能性,从中挑选最有利的步数去走而已,说穿了就跟GPS导航系统从已知的所有地图路径当中选择最佳路径没什么两样。
然而面对无限多种可能性的现实世界,这样的暴力穷举法显然无法套用到大多数更为复杂的现实情况,要把AI应用在日常生活当中,我们还是需要寻找更有效率的做法,而人类累积智慧的方式就是一个很好的参考方向。
人类的智慧,来自于经验,也就是不断地学习与记取教训,在一次次的尝试错误当中调整自我对外界的认知,如此一来当下一次遇到类似的状况我们就能轻易利用过往的经验来判断与应对未知的未来,同时,为了大幅减少所需记忆和处理的内容,人们也很擅长把类似的东西分类贴标签,把大量的信息归纳为少少的几类,套用同样的概念我们有没有可能把经验也就是历史资料喂给机器去学习从而自动找出事件特征与结果之间的关联模型,而变成一个能预测未来数值或者自动分类与决策的程序。
自动分类的方法
关于预测数值一个很直觉的想法就是找出事件特征与结果之间的数学线性关系,举例来说,假设在某个地段有一间10平米的房子以10万成交,另一间20平米的房子以20万成交,根据这样的信息我们就能合理推断出成交价与坪数之间大约就是每平米10万的关系,而当成交信息愈来愈多时,我们也能利用梯度下降之类的技巧找出一条最符合所有资料的回归线,进而获得一个用梯度下降数来预测房价的模型,这就是所谓的线性回归法。
关于自动分类则有许多方法,在此我们列举几个有名的算法来感受一下:
面对非此即彼的分类问题我们也可以把特征与结果之间的关联投射回归到一个0与1的逻辑曲线上,0代表其中一类,1代表另外一类,如此就利用类似的做法得到一个把任意数值对应到适当分类的模型,这就是所谓的逻辑回归法。
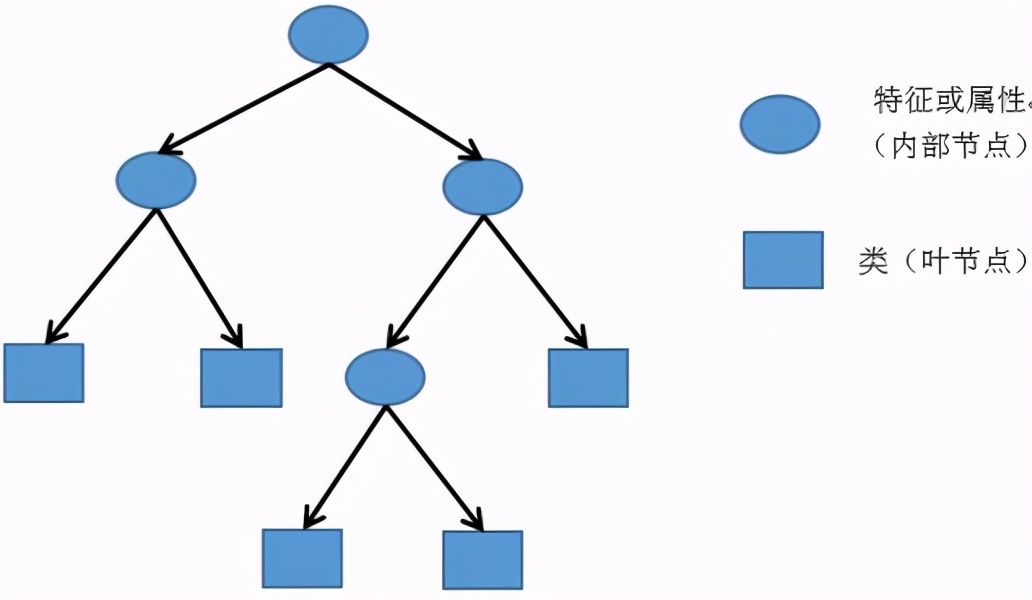
决策树是利用特征与分类结果之间的关系,由历史资料来建构出一棵充满着“如果这样就那样”的决策树,成为一个让不同的特征落入对应的适当分类的模型。
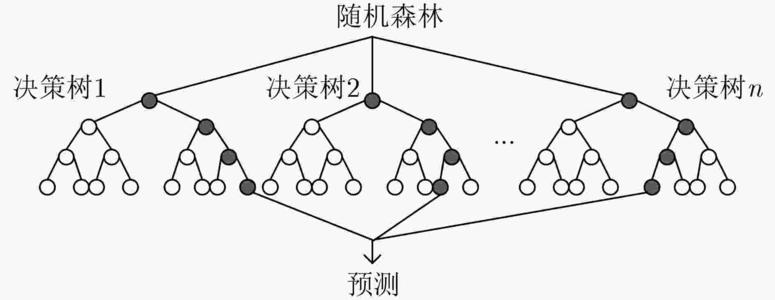
面对同样的问题为了避免单一特征的重要性被过度放大而造成偏差,如果随机挑选部分特征来建构多棵决策树,最后再用投票的方式来决胜负,将会得出比单一决策树更全面更正确的答案这就是随机森林法。
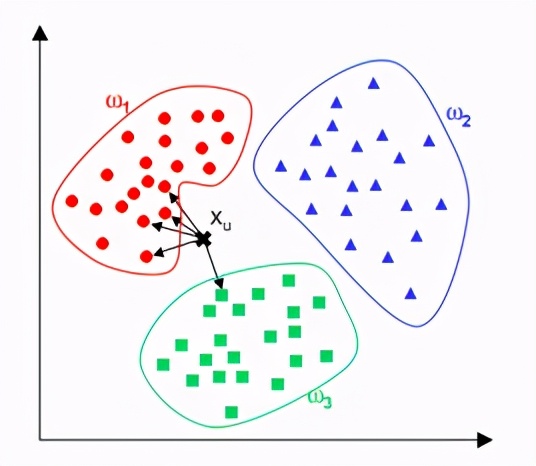
最近邻居法简称KNN,是在现有历史资料的基础上对于想预测的新资料直接比对特征最接近的K笔历史资料看他们分别属于哪个分类,再以投票来决定新资料的所属分类。
支持向量机简称SVM,试着在不同分类群体之间找出一条分隔线,使边界距离最近的资料点越远越好,以此来达到分类的目的。
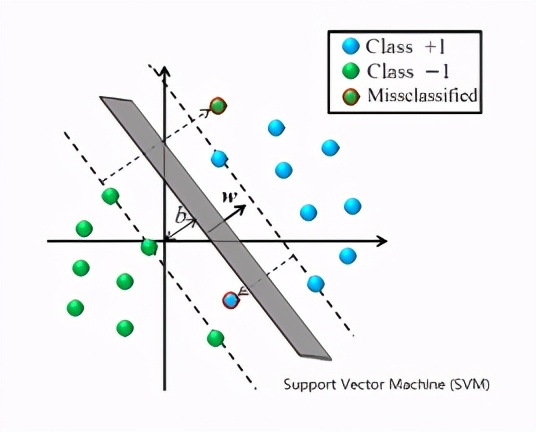
以上都是在历史资料都有标准答案的情形下,试着找出符合特征与结果之间关联性的模型,如此一来新资料就能套用相同的模型而得出适当的预测结果,那么如果我们手头上的资料从来没被分类过,还有办法自动将他们分群吗?有的:
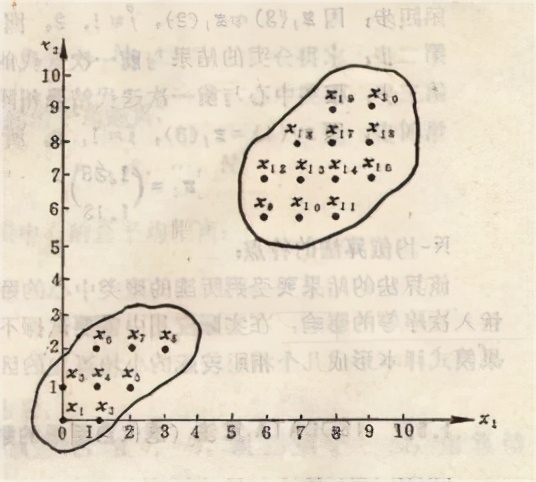
K-平均算法,先从所有资料当中随机数选择K个中心点,我们就能把个别资料依照最近的中心点分成K群,将每一群的平均值当成新的K个中心点再分成K群,以此类推最终资料将收敛至K个彼此相近的群体,以上都是在有历史资料的情形下利用资料来建构模型的算法,那么如果没有历史资料呢?
强化学习
强化学习简称RL,概念上是在没有历史资料的情况下把模型直接丢到使用环境当中,透过一连串的动作来观察环境状态同时接受来自环境的奖励或惩罚反馈来动态调整模型,如此一来在经过训练之后模型就能自动做出能获得最多奖励的动作。
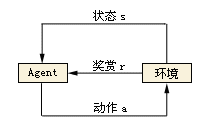
面对这么多琳琅满目的机器学习算法我们首先面临的难题就是该套用哪一种算法,关于算法的挑选通常我们会依照用来训练的历史资料有没有标准答案将算法分为两大类,监督式学习或者非监督式学习,然后再依能达成的效果细分下去,至于没有历史资料的强化学习则独立于这两大类自成一格。
此外我们也需要考虑每个算法的特性与前提假设,除此之外,还有许多杂七杂八的因素,比如资料量的大小、模型效能与准确度之间的取舍等等,甚至有人将算法的选择做成SOP让人比较有方向可循,即便如此这样子根据不同类型的问题见招拆招的方式似乎也只适用于这些相对单纯的应用场景,难以套用到更高层次更复杂的应用上,难道机器学习就只能这样了吗?
AI进阶——深度学习
在发展机器学习的同时擅长模仿的人类也把脑筋动到了模仿自己的大脑神经元上,人脑虽然只由简单的脑神经元组成,却能透过数百到数千亿个神经元之间的相互连结来产生智慧,那么我们能不能用相同的概念让机器去模拟这种普适性的一招打天下的机制而产生智慧呢?
这个想法开启了类神经网络这个领域进而演变为后来的深度学习,一个大脑神经元有许多树突接收来自其他神经元的动作电位,这些外来动作电位在细胞内进行汇整,只要电位超过一个阀值就会触发连锁反应,将这个神经元的动作电位讯息透过轴突传递给后续的神经元。
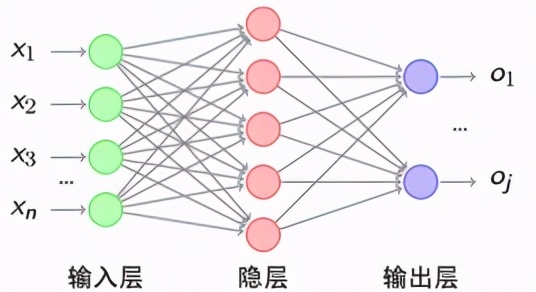
同理我们可以把大脑神经元的机制以数位逻辑的方式来模拟,我们称之为感知器,其中包含m笔输入*一个偏置,经过权重相乘并加总之后再通过一个激活函数来模拟大脑神经元的电位阈值机制,最终输出这个节点被激活的程度,传递至下一层的感知器。
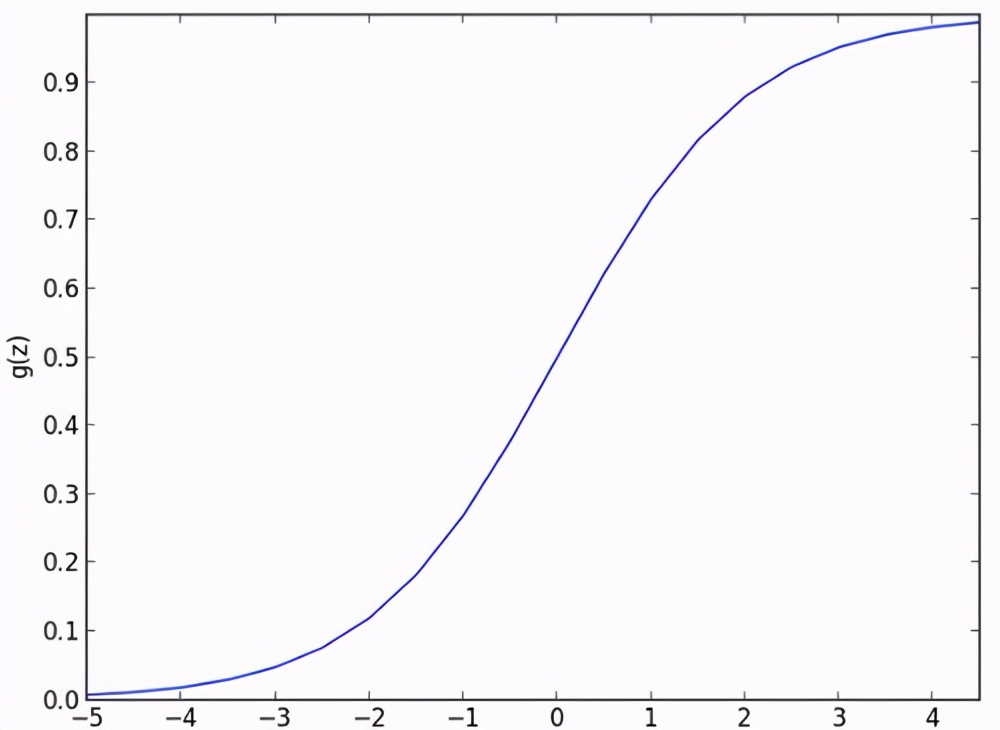
由于现实中要解决的难题大多不会有简单的线性解,我们通常会选用非线性函数的激活函数,象是介于0与1之间的s形函数,介于-1与1之间的双曲正切函数,最常被使用的线性整流函数或者其他变形。
而一旦我们把很多个感知器分层相互连接起来就形成一个深度学习的模型架构,要训练这个模型就把资料一笔一笔喂进去先进行正向传播,将得出的输出结果与标准答案带入损失函数,算出两者之间的差异再以梯度下降之类的最佳化函数进行反向传播,以减少差异为目标来调整每一个感知器里的权重,只要资料量够多模型输出与标准答案之间的差异就会在资料一笔一笔正向反向流入模型的自我修正当中逐渐收敛减小,一旦经由模型得出的答案与标准答案的差异小到某个可以接受的程度,就表示这个模型是训练好的可用的模型。
这样的概念看似简单但要实现出来则需要大量的资料大量的运算能力以及够简单好用的软件,也因此在2012年之后当这三个条件都满足了深度学习才终于开花结果开始有了爆炸性的成长。
实际问题的解决
在计算机视觉领域我们可以使用卷积神经网络CNN,先用小范围的滤镜来取得影像的边缘、形状等等特征,再把这些富有意义的特征连接到前面提到的深度学习模型,如此就能有效识别图片或影像中的物体,透过这样的方式计算机在影像识别的正确率上已经超越人类并持续进步当中。
在模仿影像或艺术风格方面则可以使用生成对抗网络GAN,透过两个深度学习模型相互抗衡由立志要成为模仿大师的生成模型产生假资料交由判别模型来判断资料真假,一旦生成模型产生出来的假资料让判别模型分不清真假就成功了,坊间一些变脸应用的app或是AI生成的画作都是GAN的相关应用。
针对声音或文字等等自然语言处理NLP,这类有顺序性资料的处理传统上可以使用递归神经网络RNN把每次训练的模型状态传递至下一次训练,以达到有顺序性的短期记忆的功效,进阶版本的长短期记忆神经网络LSTM则用于改善RNN的长期记忆递减效应,针对类似的问题后来有人提出另一套更有效率的解法称为Transformer,概念上是使用注意力的机制让模型直接针对重点部分进行处理,这样的机制不只适用于自然语言处理,套用在计算机视觉领域上也有不错的成果。
2020年拥有1750亿模型参数的超巨大模型GPT-3已经能做到自动生成文章与程序码或回答问题质量甚至还不输人类,未来随着模型参数个数再持续指数型成长这类模型的实际应用成效更是令人期待,而除了前面说的计算机视觉与自然语言处理这两大领域之外,深度学习在各个领域也都有很惊人的成果。
2017年在不可能暴力穷举的围棋领域中结合深度学习与增强学习的AlphaGo以3:0击败世界第一围棋士柯洁震惊全世界,等同宣告AI已经能透过快速自我学习在特定领域超越人类数千年以来的智慧累积,2020年AlphaGo的研发团队DeepMind再度运用深度学习破解了困扰着生物学50年的蛋白质分子折叠问题
这将更实际地帮助人类理解疾病机制促进新药开发帮助农业生产进而运用蛋白质来改善地球生态环境,更贴近生活的自动驾驶的发展更是不在话下,当前的自动驾驶技术随着累积里程数持续增加而趋于成熟,肇事率也早已远低于人类,同时AI在医学领域某些科别的诊断正确率也已经达到优于人类的水平,至于无人商店与中国天网则早已不是那么新奇的话题了。
结语
这时,再回头来看1950年图灵的问题,机器能思考吗?我们可能还是无法给出一个明确的答案,然而,当下的人类却已经比当年拥有更多的技术累积成果更接近这个梦想并持续前进当中,当前的AI技术就像一个学习成长中的小孩,能看、能听、能说,以及能针对特定问题做出精准、甚至跳脱框架、超越人类过往认知能力的判断,然而一旦遇到复杂的哲学、情感、伦理道德等议题就还远远无法胜任。
总体而言人与机器各有所长,人类擅长思考与创新然而体力有限,也偶尔会犯点错误,机器则擅长记忆与运算,能针对特定问题给出稳定且高质量的答案而且24小时全年无休,因此在这波AI浪潮下理想策略应该是人与机器充分合作各取所长,人们可以把一些比较低阶、重复性高、琐碎、无趣的工作逐步外包给机器,与此同时释出的人力将可以投入更多探索、研究、富有创造性、也较有趣的工作当中,如此一来人们将更有时间与精力去实现梦想去思考人生的意义,也更能专注在解决重要的问题上进而提升整体人类的层次。