












本文转载自微信公众号「DBA闲思杂想录」,作者潇湘隐者。转载本文请联系DBA闲思杂想录公众号。
这篇文章分享一下如何通过使用Zabbix与DPA工具(SolarWinds的Database Performance Analyzer)结合来分析、定位SQL Server的tempdb数据库大小暴增的问题。个人经验,没有完美的监控工具,所谓尺有所长,寸有所短。监控方案不要全部依赖一个工具,最好是多个监控工具搭配与结合,长短互补。多方面、多层次监控。
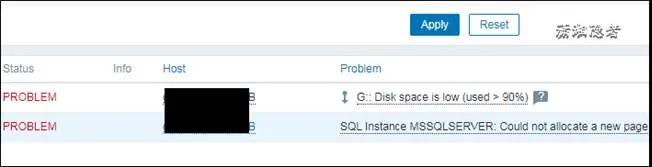
如下所示,Zabbix监控发出了告警,磁盘空间告警和数据库无法分配新的页面告警,如下所示
- G:: Disk space is low (used > 90%)
- SQL Instance MSSQLSERVER: Could not allocate a new page
如下截图所示,可以看到G盘(此盘单独存放tempdb的数据文件)在短短一小时内暴增了100多G。
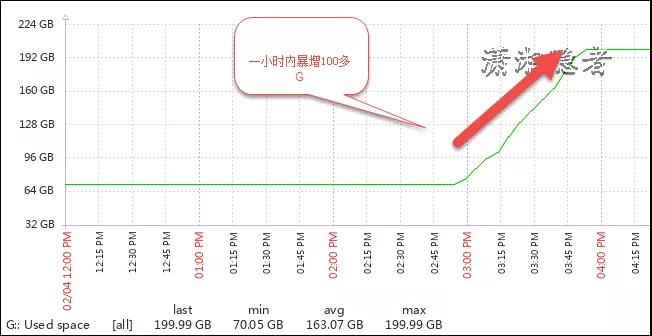
注意:其实是2点55左右开始的,在接近4点时结束,主要发生在3:00-4:00这个时间段,所以我们下面主要分析这个时间段内的数据。
Zabbix发出告警的同时,其实DPA也出现告警了,但是它提示这个时间段的性能出现严重下降,等待事件的累积时间彪增,指标从绿色变成了红色。但是当时个人正在处理另外一个问题,没有留意到告警信息,错过了最佳时机,等到发现问题的时候,已经无法抓取问题SQL,但是DPA工具抓取、捕获了相关SQL以及一些指标数据。
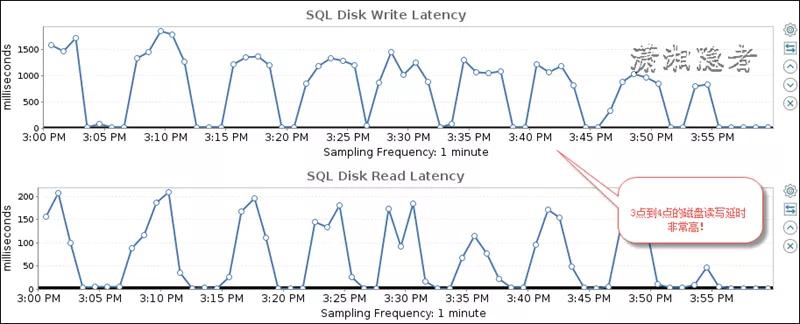
首先,我们分析这个时间段的各项指标数据,做下钻分析,发现这个时间段内的磁盘读写延时非常高,如下截图所示
加入Total I/O Wait Time等分析指标,如下所示,默认情况下,只显示部分指标数据,如果你需要观察其它一些指标数据,需要做切换。如下截图所示
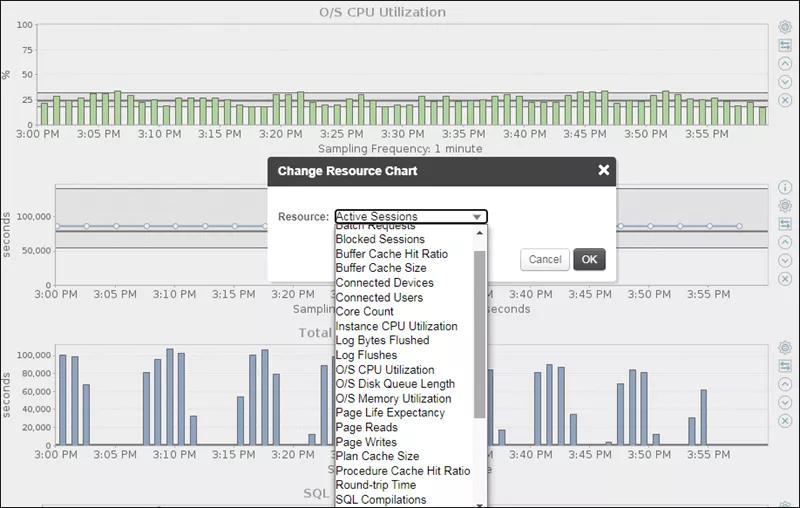
如下所示,Total I/O Wait Time也高得离谱。
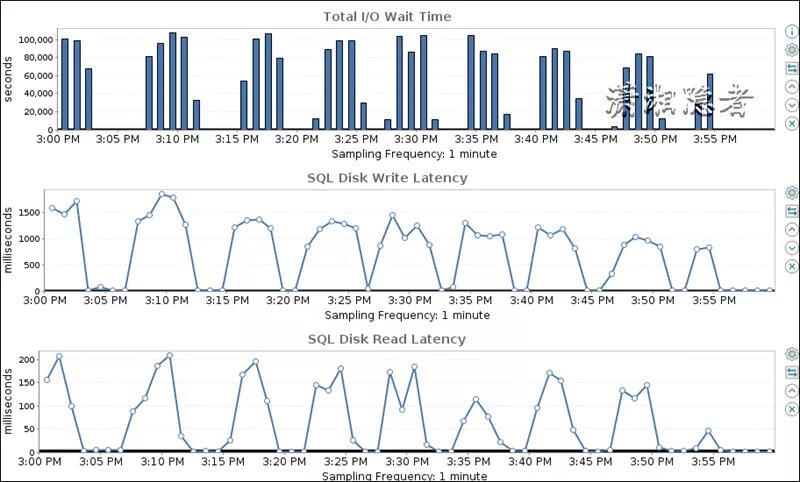
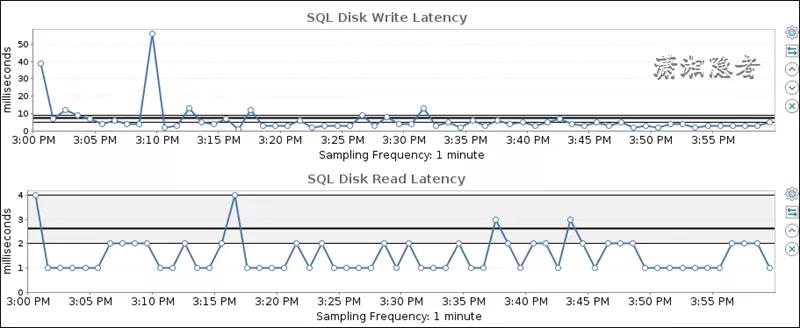
其实通过环比、同比分析发现,我们就会发现其实正常情况下,数据库的读写时延基本都在10毫秒以下。如下其中一张截图所示:
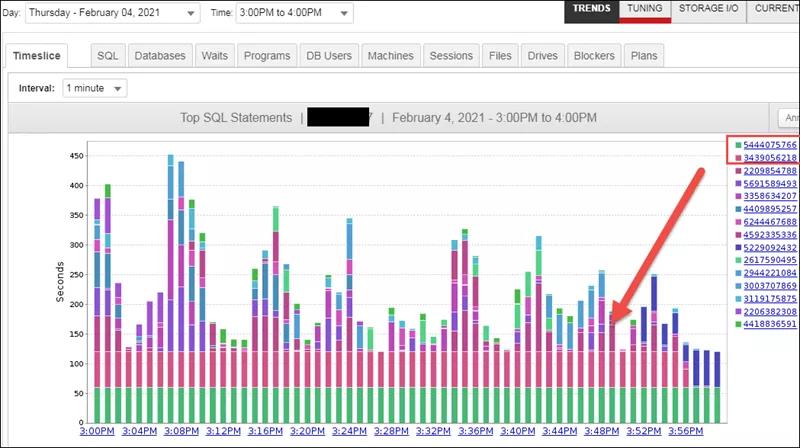
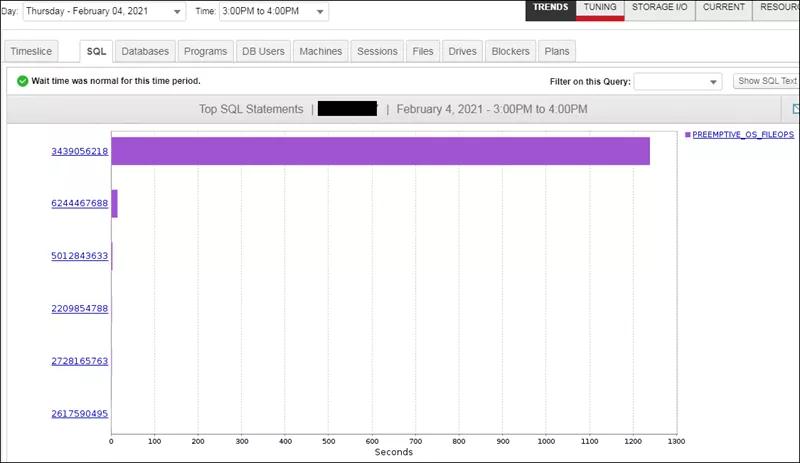
按时间划片,我们观察到3点到4点间,等待时间最多的是下面两个SQL(SQL Hash值为5444075766和3439056218的SQL语句),如下截图所示:
经过下钻分析,我们排除掉Hash值为5444075766的SQL,着重分析SQL Hash值为3439056218的SQL语句,如下截图所示,发现这个SQL语句出现了大量的等待事件(如下所示),从这些等待事件分析,主要是Memory/CPU等待事件(后面分析会让你会知道为什么Memory/CPU等待事件占了大头)和PREEMPTIVE_OS_FILEOPS等待事件,基于经验判断,估计这个SQL是罪魁祸首的可能性非常大,因为大量PREEMPTIVE等待事件,以及PREEMPTIVE_OS_FILEOPS等待非常高,一般出现大量的PREEMPTIVE_OS_FILEOPS等待事件,很有可能出现大量的IO操作,在这里就极有可能是tempdb空间的分配和占用。当然这个不是绝对的。不能作为因果推理。
- PREEMPTIVE_OS_GETDISKFREESPACE
- PREEMPTIVE_OS_FILEOPS
- PREEMPTIVE_OS_WRITEFILEGATHER
- Memory/CPU
- PAGEIOLATCH_UP
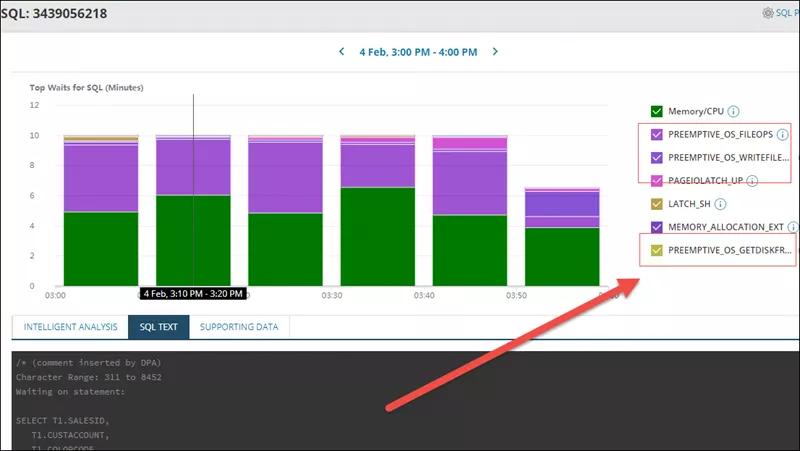
PREEMPTIVE_OS_FILEOPS等待事件,它产生在当线程调用与文件系统相关的多个Windows 函数之一时,此等待类型是一种通用等待。然后我们从“Waits”这个维度下钻分析,发现这个等待事件下,也主要是SQL Hash值为3439056218的SQL语句。其它语句产生这个等待事件微乎及微。这个现象也增加了我们初步判断的正确性。
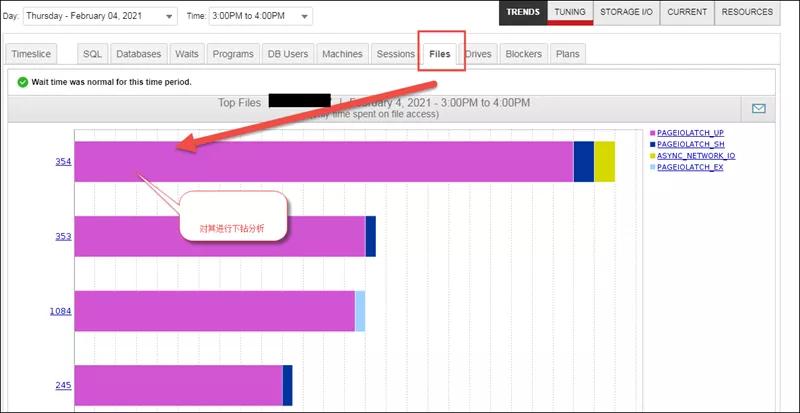
从其它维度(Files)下钻分析,发现也是SQL Hash值为3439056218的SQL语句
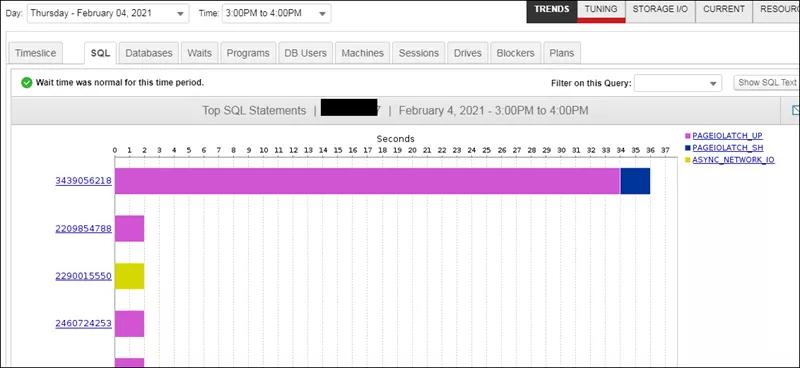
然后仔细分析发现这个SQL,发现SQL里面使用CROSS JOIN关联一个表和视图,但是WHERE语句中两者居然没有关联条件,也就是说这个SQL变成了一个笛卡尔积。再加上SQL中还有排序等操作,所以这个SQL要消耗大量的tempdb的空间。由于笛卡尔积,所以才出现Memory/CPU等待是大头的现象。至此,分析结束。正向分析和反向印证了这个SQL确实是导致tempdb暴增的原因。











