












大数据文摘出品
作者:Caleb
说到社交媒体的算法推荐,还真是让人欢喜让人忧。
事情是这样的。
当时,我的一个朋友John正在申请麦吉尔大学的生物学博士,我也正在钻研生物化学领域。我们因为在同一家制药厂实习迅速热络起来,经常还在我家地下室打球、录制视频等。
但是一年后我发现,John变了。他开始狂热地信仰宗教,总是和我争论宗教知识应该是世界上唯一的科学,也是从那个时候开始,John把名字改成了Yahya,留起了胡子,说话也带上了明显的口音。
同时,John的Facebook账号上开始涌现出大量的激进内容,其中一些视频内还对美国和加拿大的所谓“异教徒”怀有明显的仇恨与恶意。
最后一次与John交谈的时候,我已经知道特勤局已经对他进行了长达数月的调查。
结合我在谷歌和DeepMind的实习经历,以及我在算法推荐系统领域的学习,John的事件让我开始思考如今风头正盛的基于推荐算法的社交媒体。
在John这件事上,可以肯定的是,John逐渐激进的事实与Facebook的推荐算法有着密切的关系。但是,还无法确定的是,是怎样的算法推荐让John开始转变信仰,当John的Facebook发帖变得越来越极端的时候,此时的新闻推送是根据怎样的算法得出的?
当我们尝尽了基于算法推荐的社交媒体的种种甜头之后,如今,严重的负面效应开始显现。这在最近美国所发生的一连串事件中都能得到印证,尤其是当平台自动为你推荐一些激进内容或者是发布一些激进组织的相关信息时。
于是我也开始思考,当我在推特或者其他新闻推送中点开一些激进视频时,我是否也在无形之中对其成型起到了推波助澜的作用?
在社交媒体中使用机器学习的风险
随着智能手机的普及,我们逐渐习惯于把虚拟助手、社交媒体等作为新闻来源来帮助我们了解这个世界。久而久之,平台的倾向性也会影响我们自身的倾向,甚至是行为。
这些推荐机制的原理都是来源于机器学习。
机器学习算法就是一组指令,帮助机器从数据模式中进行学习,这些模式还能帮助人们进行决策。比如,新闻源就可以通过被称为推荐系统的机器学习来创建。这在广告领域的应用可能更为广泛,广告商想知道的是,用户最可能点击什么样的广告,从而更大程度地进行资源分配。
但在这种好处背后是难以撼动的激励机制和权力结构,Facebook、苹果和谷歌等公司仍然忙于利用会员制和广告费来赚取收入,对于“房间里的大象”,所有人都选择了视而不见。
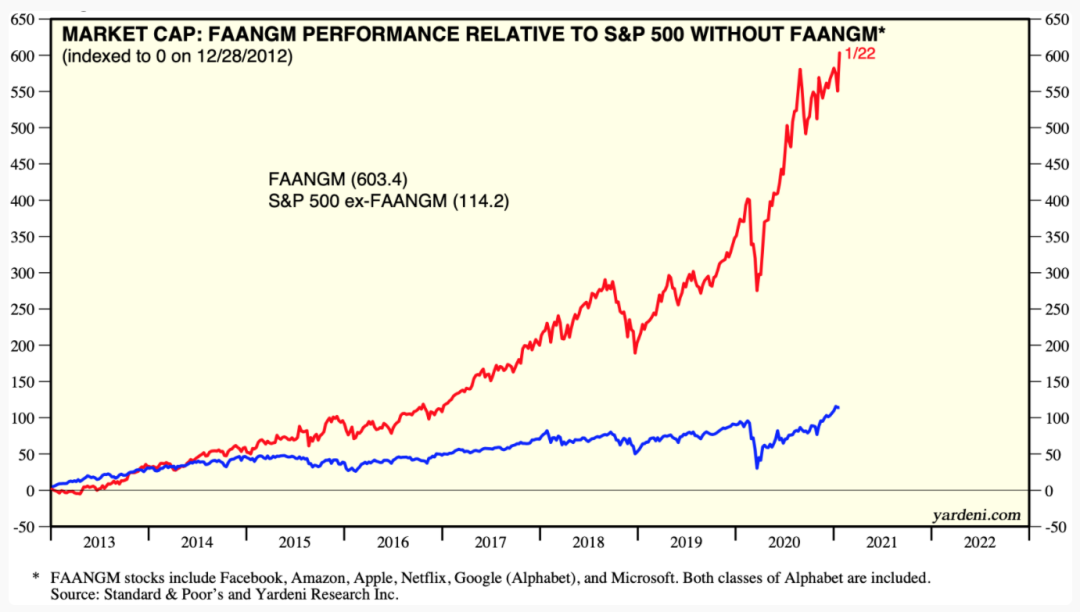
2020年,六家FAANGM公司(Facebook,亚马逊、苹果、Netflix、谷歌和微软)的商业模式组成一个季度标普指数和负责的大部分收益,这些公司的员工平均年薪为339,574美元。
当这种现象成为普遍的时候,社交媒体便能够利用机器学习来放大现有的不平等,以及针对易受错误信息影响的人群发布更带有偏激性的内容。
最大的证据便是Facebook成立了一支反恐团队,但具有讽刺意味的是,其本身依赖于机器学习,也不乏相同的商业动机。换句话说,当屏蔽的内容越多,被禁的人就越多,公司的收入就会减少。
目前,Facebook已经承认其对缅甸的报道具有倾向性。同样,推特、YouTube和Facebook也在近期美国的政治事件中发挥了作用,Facebook的举报人承认,全球政治操纵能力部分是通过机器学习来创建的,这可能会增加地缘政治风险。
针对如John般这样可能因为自己的经历而受到社交媒体影响的人,我们更需要在社会层面上,与相对自由的道德和法律专家以及机器学习研究专家进行更具有针对性的讨论。
如何减轻机器学习的社会风险
令人好奇的是,在算法社交媒体的有害影响已被记录在案的前提下,有哪些法律途径可以管理以机器学习为动力的企业。例如,在个人层面上,我们都会易受影响于某类新闻,这是受到法律保护,不能被歧视。也就是说,社交媒体利用我们的这些“弱点”进行攻击其实是非法的。
那么问题来了,哪些途径可以帮助保留机器学习的收益,同时保护弱势群体免受有害影响?
假设科学家找到确凿的证据,根据种族、性别或收入,有些人更容易沉迷于机器学习所推荐的内容,那么我们能否称,歧视是发生了,从而降低公司的市值?毕竟,社交媒体沉迷对公司而言意味着更深的用户粘度和参与度,但是在业务指标上好看的数字可能并不会使受其影响的人们变得更好。
除此之外,更直接的一种方式是降低广告收入。建造AI的实验室正面临亏损,这意味着当营收下降到一定程度时,他们将首先离开。
同时,支撑谷歌、Facebook和其他大公司业务的机器学习工具顺应的开源的趋势,正变得更加易于访问。随着广告收入持续下降,算法偏见将会成为主流公众知识。
收入持续下降、用户隐私意识觉醒和开放源代码都可以成为推动社交媒体往良性发展的动力,而不是通过数据来利用用户。学术实验室还可以通过领导透明、开放源码的努力来发挥作用,以帮助了解机器学习系统中的利益相关者如何为研究造福整个社会。
但是,当我们等待并希望有关掌权者创造变革时,作为个人,我们可以做很多事情,以了解和学习如何管理生活中许多方面的机器学习算法带来的风险。
个人应该怎么做
正如上文所言,这些策略本身其实是告诉自己,代表自身及他人倡导与收集N=1数据,届时可能会对大型社交平台的动机产生更深刻的认识。
与受影响的人开始对话:参与工作环境。如果你正在构建机器学习工具,请实际使用它们。需要考虑到,这份工具可能会影响谁,并与这些人交谈。交谈中可以简单描述所做的工作,以及驱动该技术的数据和商业利益。
例如,我从描述我的机器学习和心理健康研究中获得了强烈的负面反馈,从而塑造了该研究并帮助改正了课程。与我们的朋友,家人和社区的这种非正式的民族志田野调查被低估了,并提供了一种低风险、高影响力的方式来告知我们学习的内容:与谁以及为谁学习。
注意到人们在工业界和学术界研究的是不同事物。工业往往是一条单向道,警惕金笼效应,即那些赚很多钱的人可能会不愿考虑或讨论机器学习的风险,或者可能由于担心被解雇而避免对其进行研究。
例如,算法公平性的领域得到关注是因为微软禁止其研究人员对歧视性广告的研究。类似的,谷歌人工智能与道德团队因为在论文中强调了谷歌搜索模式的缺陷而被解雇。此类事件对相关人员而言代价高昂,这就是为什么在商业利益凌驾于公众利益和学术自由之上的罕见情况下,他们能够大声疾呼,举报或以其他方式告知公众时,需要得到额外支持的原因。
阻止定位并清除隐私设置。如果要让80亿人选择通过利用私人数据来个性化广告,那么激励错误信息的商业模式将很难发展。使用uBlock或其他浏览器扩展程序可以阻止所有新闻提要或HTML元素以及在YouTube等上使用机器学习创建的内容;在Facebook上取消关注所有人以清除新闻源。
通过启用自动删除位置、网络和语音记录的历史记录来删除数据。我为私人利益牺牲的数据越少,我注意到的认知负荷就越少,这也许是因为对涉及我的数据的预期场景,可能应用的机器学习系统以及系统在世界范围内产生的第二级和第三级影响的担忧减少了。
希望通过本文为大家提供一个解决问题的思路,找到问题可能出现的地方,问题是如何发展起来的,以及我们应该采取怎样的方法来解决。
当然,回到本文主题上,无论是对于激进态度本身,还是错误信息,我们都应该随时保持警惕,以阻止那些无法很好地管理机器学习而做出不明智决定的商业动机。
相关报道:
https://www.reddit.com/r/MachineLearning/comments/l8n1ic/discussion_how_much_responsibility_do_people_who/
https://jaan.io/my-friend-radicalized-this-made-me-rethink-how-i-build-AI
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】






















