最近在进一步优化随机恢复的成功率问题,本来预计是2周内能够快速结束,从1个9的恢复能力快速提升到2个9,结果这个Flag立下了,但是最终的结果和付出的努力远比想象中要高。
其实有很多同学不大理解为什么2个9那么难,整体来说,数据备份是基于一次全量永远增量的模式,数据量会不断增长,所以数据是动态变化的,另外如何恢复数据的需求是动态的,比如我可以随机指定1个时间,比如这一次是2:00,下一次可能是3:20,不确定的时间就会给已有的服务带来新的潜在不确定性,此外绝大多数的问题是在数据库启动期间发生,通常会和存储容量,插件配置,参数配置相关,如果报错,尽管手工修复也可以搞定,只要启动报错,我们也会按照失败来计算,所以验收标准算是比较简单清晰的。
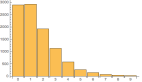
最近经过一段时间的沉淀,发现成功率竟然从93%下降到了88%,
为了保证恢复任务的可执行性,目前是采用了crontab的模式,如下:
- 30 7-23/3 * * * /usr/bin/python /root/crontab_tasks/random_recover.py >> /root/crontab_tasks/log/random_recover.log &
- 00 6-22/3 * * * /usr/bin/python /root/crontab_tasks/random_recover.py >> /root/crontab_tasks/log/random_recover.log &
为了提高恢复的吞吐量和效率,目前是使用了3台恢复机器来实现基于IDC的动态调度。
基于之前的失败数据,我的第一轮测试选取了23个样本,恢复的过程相对比较快,指定恢复到dn1这台恢复机器后,恢复成功率达到了100%,有点让我惊呆。
然后我重新选择了dn2,再次恢复了同样的23个样本实例,这一次,竟然失败了3个,而专门再次恢复,就没有问题了,着实让我有些意外
通过这样的测试,我做了进一步的分析,发现问题主要出现在binlog的回放方面,所以可以初步断定,在binlog的有效性方面还是存在潜在的问题,目前的随机时间范围是在3-24小时之内,所以我先刻意调整了时间范围,把它先缩短。
对于任务的调度时间,我进一步分析,发现还是由潜在的风险的,目前的测试基数还是比较小,按照每3小时执行1次,2个定时任务触发的模式,一天差不多会有12个左右的任务。
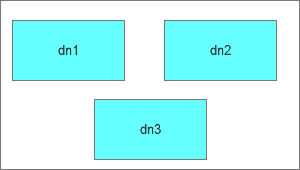
这种调度模式的缺点就是对于任务的执行没有弹性,如果数据恢复时间超过1个小时,基本上就是失败了。另外就是dn1,dn2,dn3的任务选择也是随机的,带来的隐患就是如果dn1被选定恢复,很可能下次还是会随机为dn1继续恢复,就会导致dn2,dn3都始终处于闲置状态。
一种较为理想的方式是,可以定制恢复的基数,比如目前是12次,基本是每隔小时都会触发一次,如果我们需要恢复20次,那么平摊到每台恢复机器的调用次数差不多是7次,相对来说还是比较宽松的,如果按照强调度模式,那么可以支撑的基数最大是48次左右。
如果跟进一步,我们做成即时响应模式,即dn1恢复之后马上触发下一波的恢复任务,那么这个基数的提升会直接乘以3,还是比较强悍的。
所以马上要做的改进就是把这3台恢复机器用活,让他们不要始终处于闲置状态。否则就是下面的状态。
本文转载自微信公众号「杨建荣的学习笔记」,可以通过以下二维码关注。转载本文请联系杨建荣的学习笔记公众号。