













今天,我们来说说,拿到一段通过零宽字符隐藏了信息的字符串,我们怎么阅读被隐藏的信息。
例如下面这个字符串:
一日一技是一个每天更新的栏目,希望做到在每天几分钟让你获得提高。
人眼能够正确阅读,但如果我们把它粘贴到 Jupyter里面,大家就能发现零宽字符的踪迹,如下图所示:

在上一篇文章中,我们提到可以使用零宽字符8204代替1,8205代替0,那么,现在我们只需要使用字符串的.replace()方法,就能反向替换回来,如下图所示:

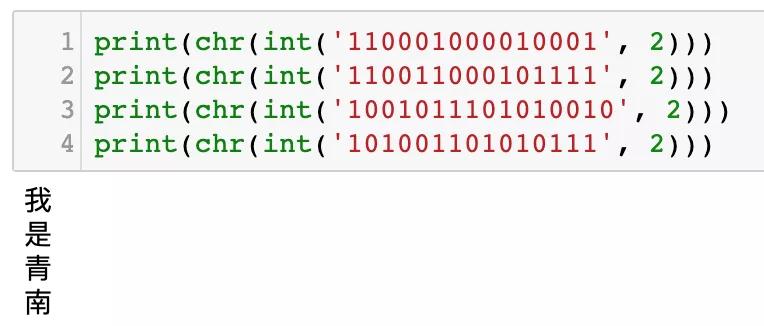
有了这些二进制数以后,我们就能把他们先转成十进制数,然后再转成汉字,如下图所示:
现在,我们想把这个过程自动化。实现一段代码,依次遍历字符串中的每一个字符,发现连续由8204和8205构成的字符串,就把它存起来,直到遇到一个普通字符。拿到每一串由零宽字符构成的字符串以后,把它们分别先替换成字符串形式的二进制数,然后使用int函数转成十进制数,再使用chr函数转成普通的字符。
这个逻辑的代码实现如下图所示:
- sentence = ' 一日一技是一个每天更新的栏目,希望做到在每天几分钟让你获得提高。'
- char_1 = chr(8204)
- char_0 = chr(8205)
- hide_word_start = False
- hide_word = ''
- hide_word_list = []
- for char in sentence:
- if char not in [char_1, char_0]:
- if not hide_word_start:
- continue
- else:
- hide_word_list.append(hide_word)
- hide_word = ''
- hide_word_start = False
- else:
- hide_word += char
- if not hide_word_start:
- hide_word_start = True
- code_book = {}
- for word in hide_word_list:
- if word in code_book:
- continue
- word_in_1_0 = word.replace(chr(8204), '1').replace(chr(8205), '0')
- real_word = chr(int(word_in_1_0, 2))
- code_book[word] = real_word
- for hide_word, real_word in code_book.items():
- sentence = sentence.replace(hide_word, real_word)
- print(sentence)
运行效果如下图所示:

本文转载自微信公众号「未闻Code」,可以通过以下二维码关注。转载本文请联系未闻Code公众号。
















