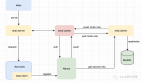
什么是前端智能推理引擎
在前端智能推理引擎之前,我们先来说一下什么是 ”端智能” 。
端智能(On-Device Machine Learning)是指把机器学习的应用放在端侧做。这里的“端侧”,是相对于云服务而言的。它可以是手机,也可以是 IOT 设备等。
传统的机器学习,由于模型大小、机器算力的问题,很多是放在服务端做的。比如 Amazon AWS 有“Amazon Rekognition Service”,Google 有 “Google Cloud Vision Service”。而随着以手机为代表的端侧设备算力的提高,以及模型设计本身的演进,大小更小、能力更强的模型逐渐能够部署到端上运行。
相比云端部署的方式,APP端拥有更直接的用户特征,同时具备如下优势:
-
实时性高, 端侧处理可节省数据的网络传输时间。
-
节省资源, 充分利用端侧算力和存储空间。
-
隐私性好, 产生数据到消费数据都在端侧完成,避免传输引起的隐私泄露风险 。
这些是端智能的优势,但它不是万金油,仍然存在一些局限性:
-
设备资源有限, 端侧算力、存储是有限的,不能做大规模高强度的持续计算。
-
算法规模小, 端侧算力小,而且单用户的数据,在算法上并不能做到最优。
-
用户数据有限, 端侧数据不适合长期存储,同时可用数据有限。
同理,前端智能是指将机器学习的应用放到前端上(web、h5、小程序等).
所以,什么是前端智能推理引擎呢?
如下图:

前端智能推理引擎实际上就是利用前端上算力去执行模型的那个东西。
业界现有的前端推理引擎
这里列出三个常见的推理引擎
-
tensorflow.js (下面简称为tfjs)
-
ONNX.js
-
WebDNN
对于一个端上推理引擎来说,最重要的是什么?当然是性能了!性能越好,也代表在端上的应用场景也会越多,下面我们来看下这三个推理引擎的性能对比:
(下面数据使用模型为MobileNetV2分类模型)
cpu(js计算)

可以看到,在纯JS环境下进行计算,仅仅做一次分类都要1500ms以上。设想一下如果一个相机需要实时对拍摄的物体做分类预测(比如预测拍摄的对象是猫还是狗),那么每预测一次需要1500ms,这样的性能是无法忍受的。
WASM

在WASM环境下,性能最佳的ONNX.js达到了135ms的性能,也就是7fps左右,已经到了勉强能用的程度了。而tfjs却是糟糕的1501ms。这里是因为onnx.js利用了worker进行多线程加速,所以性能最好。
WebGL(GPU)

最后是GPU环境,可以看到tfjs和ONNXjs的性能都达到了比较好的性能水平,而WebDNN表现较为糟糕。
除了上面这三种引擎,目前国内还有百度的paddle.js以及淘宝的mnn.js等,这里不做讨论。
当然,在选择一个合适的推理引擎时,除了性能以外,还有生态、引擎维护情况等等一系列的考虑。从综合的方面来说,tfjs是当下市场上最适合的前端推理引擎。因为tfjs可以依靠tensorflow的强大的生态、google官方团队的全职维护等。相比之下ONNX框架比较小众,且ONNXjs已经有近一年没有维护了。WebDNN性能及生态都没有任何竞争力。
前端上的高性能计算方案
从上一章节其实能看到,在前端上做高性能计算一般比较普遍的就是WASM和基于WebGL的GPU计算,当然也有asm.js这里不做讨论。
WASM
WASM大家应该是比较熟悉的,这里只做下简短的介绍:
WebAssembly是一种运行在现代网络浏览器中的新型代码,并且提供新的性能特性和效果。它设计的目的不是为了手写代码而是为诸如C、C++和Rust等低级源语言提供一个高效的编译目标。
对于网络平台而言,这具有巨大的意义——这为客户端app提供了一种在网络平台以接近本地速度的方式运行多种语言编写的代码的方式;在这之前,客户端app是不可能做到的。
而且,你在不知道如何编写WebAssembly代码的情况下就可以使用它。WebAssembly的模块可以被导入的到一个网络app(或Node.js)中,并且暴露出供JavaScript使用的WebAssembly函数。JavaScript框架不但可以使用WebAssembly获得巨大性能优势和新特性,而且还能使得各种功能保持对网络开发者的易用性。 --《摘自 MDNWebAssembly概念 》
WebGL
啥?WebGL不是做图形渲染的吗?不是做3D的吗?为啥能做高性能计算?
可能一些同学听说过gpgpu.js这个库,这个库就是利用webgl做通用计算的,具体的原理是怎么样的呢?(为了能够继续往下阅读,请先快速浏览下这篇文章):《 利用WebGL2 实现Web前端的GPU计算 》。
将推理引擎的性能进行极致优化
好了,目前我们知道在前端上的两种高性能计算方式了,那么如果现有的框架(tfjs、onnxjs)性能上就是不满足我们的需求怎么办呢?怎么样才能进一步提升引擎性能,并落地生产环境呢?
答案是:手撕源码,优化性能。对,就是这么简单粗暴。以tfjs为例(其他的框架原理上是一致的),下面给大家介绍下如何用不同的姿势去优化引擎性能。
在去年年初时候,我们团队和google的tfjs团队做了一次深入交流,google那边明确表示tfjs后面的发展方向以WASM计算为主、webgl计算不做新的feature以维护为主。 但是现阶段各浏览器、小程序对WASM 的支持并不完整(例如SIMD、Multi-Thread等特性),所以 WASM暂时无法在生产环境落地。 所以,现阶段还是需要依赖webgl的计算能力。糟糕的是,此时tfjs的webgl性能在移动端上表现依旧差强人意,尤其在中低端机上的性能完全达不到我们的业务要求。没办法,只能自己硬着头皮进去优化引擎。所以以下的内容都是针对于webgl计算进行介绍。
优化 WebGL 高性能计算的n种姿势
姿势一:计算向量化
计算向量化是指,利用glsl的vec2/vec4/matrix数据类型进行计算,因为对于GPU来说,最大的优势就是计算并行化,通过向量去计算能够尽可能地达到并行化的效果。
例如一次矩阵乘法:
c = a1 * b1 + a2 * b2 + a3 * b3 + a4 * b4;
可以改为
c = dot(vec4(a1, a2, a3, a4), vec4(b1,b2,b3,b4));
向量化的同时也要配合内存布局的优化;
姿势二:内存布局优化
如果读了上面《 利用WebGL2 实现Web前端的GPU计算 》这篇文章的同学应该了解到,在GPU内所有的数据存储都是通过Texture的,而Texture本身是一个 长n * 宽m * 通道(rgba)4 的东西,如果我们要存一个3 * 224 * 224 * 150的四维矩阵进去要怎么办呢?肯定会涉及到矩阵的编码,即以一定的格式把高维矩阵存进特性形状的Texture内,而Texture的数据排布又会影响计算过程中的读存性能。例如,举一个较简单的例子:

如果是常规内存排布的话,计算一次需要按行或者案列遍历矩阵一次,而GPU的cache是tile类型的,即n*n类型的缓存,根据不同芯片n有所不同。所以这种遍历方式会频繁造成cache miss,从而成为性能的瓶颈。所以,我们就要通过内存排布的方式进行性能优化。类似下图:

姿势三:图优化
由于一个模型是一个一个的算子组成的,而在GPU内每个算子被设计成一个webgl program,每次切换program的时候会造成较多的性能损耗。所以如果有一种手段能够减少模型的program数量,对性能的提升也是十分可观的。如下图:

我们将一些可以融合的节点在图结构上进行融合(nOP -> 1OP),基于新的计算结点实现新的OP。这样一来大大减少了OP的数量,进而减少了Program的数量,所以提升了推理性能。在低端手机上效果尤为明显。
姿势四:混合精度计算
以上所有的计算都是基于常规浮点数计算,也就是float32单精度浮点数计算。那么,在GPU内是否能实现混合精度的计算呢?例如float16、float32、uint8混合精度的计算。答案是可以的,在GPU内实现混合精度计算的价值是在于提升GPU的bandwidth。由于webgl的texture每一个像素点包含rgba四个通道,而每个通道最高为32位,我们可以在32位内尽可能存储更多的数据。如果精度为float16,那么可以存储两个float16,bandwidth就是之前的2倍,同理uint8的bandwidth是之前的4倍。这个性能的提升就是巨大的。还是上图说话吧:

姿势n:...
优化的手段还有很多,这里就不一一列举了。
引擎落地的场景
目前,基于我们深度优化的引擎已经落地蚂蚁集团及阿里经济体多个应用场景,比较典型的就是文章开头演示的宠物识别,还有卡证识别、碎屏相机等等等场景。
业界的有之前比较火的虚拟试妆小程序等。
读到这篇文章的朋友们也可以打开你们的脑洞,挖掘出更多更好玩的智能场景。
未来展望
随着市面是机型的更新换代及引擎的深入优化,我相信tfjs会在更多富交互的场景上大放异彩,例如拥有AI能力的前端游戏、AR、VR等等场景。现在我们要做的就是静下心来,站在巨人的肩膀上持续打磨我们的引擎,愿等花开。