近年来,各大学术顶会的论文投稿量暴增,这使得论文评审的工作量大大增加。那么,有没有可能自动生成论文的评审结果呢?最近,CMU 研究者对此展开了探索,创建了一个自动论文评审系统,上传 PDF 论文即可自动生成评审结果,这或许会为论文评审带来一些改变。
科学技术的快速发展伴随着同行评审科学出版物的指数级增长。与此同时,论文的评审是一个耗时耗力的过程,必须由相应领域的专家来完成。这样一来,为不断增长的论文提供高质量的评审成为一大挑战。那么,有没有可能自动生成论文评审呢?
在近日发表的一篇论文中,来自 CMU 的研究者创建了一个自动生成论文评审结果的 Demo 网站 ReviewAdvisor ,只需要上传 PDF 论文,即可自动生成评审结果。
论文链接:https://arxiv.org/pdf/2102.00176.pdf
在论文中,研究者探讨了使用 SOTA 自然语言处理(NLP)模型生成学术论文同行评审结果的可能性。其中,最困难的部分首先是如何定义「好的」评审结果,因此该研究先讨论了评审结果的度量指标。然后,就是数据问题。研究者收集了机器学习领域的论文集合,使用每个评审涵盖的不同方面(aspect)内容对论文进行注释,并训练目标摘要模型,以生成评审结果。
实验结果表明,与人类专家给出的评审结果相比,系统生成的评审往往涉及到论文的更多方面。但是,生成的评审文本除了对论文核心理念的解释之外,其他方面的解读逻辑性都不强,而关于核心理念的评审则大多是正确的。最后,研究者总结了构建表现良好的论文评审生成系统面临的八个挑战以及可能的解决方案。
不过,研究者发现,人类专家评审和系统自动评审都表现出了不同程度的偏见,并且与人类专家评审相比,系统生成的评审结果具有更强的偏见性。
上面这段话来自该论文的第一部分「TL;QR」,有趣的是,这部分内容正是由其开发的系统生成的。

ReviewAdvisor 系统试用
试用该系统时,用户需要在浏览器中允许所有 Cookie,否则系统无法正常工作。研究者使用 sciparser 工具从 PDF 论文中提取信息,所以如果上传的论文采用的是不熟悉的模板,则系统也可能不工作。目前 ReviewAdvisor 支持 ICML、Neurips、ICLR、ACL、EMNLP、AAAI 等计算机科学顶会或期刊的论文。
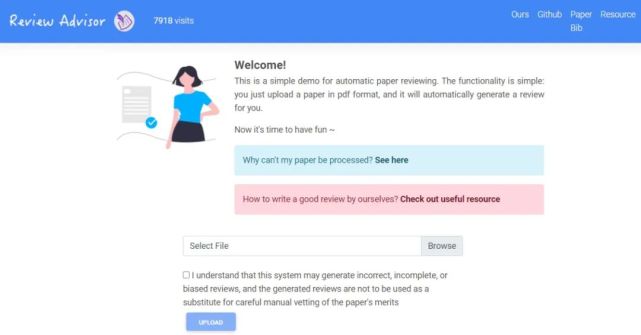
这个自动论文评审系统效果究竟如何呢?机器之心尝试上传了该研究所用的示例论文《Attention Is All You Need》。

Abstract+CE (with aspect) 又可细分为摘要、清晰度、原创性、可靠性、Substance 和对比 6 个方面。
下图展示了对示例论文《Attention is All You Need》原创性与鲁棒性的评审意见,其中关于原创性的评审意见为「使用自注意力的 idea 非常有趣且新颖」(下图左黄色部分),关于可靠性的评审意见则是「该论文未解释清楚 transformer 模型为什么优于其他基准模型」(下图右绿色部分)。

看起来,效果还不错。但是,机器之心在上传其他论文时,系统并未及时生成评审,或者上传多次后才生成评审结果。研究者表示,由于系统采用的计算机服务器是二作 Pengfei Liu 自己建立的,所以会出现内存不足的情况。这可能是无法及时生成论文评审结果的原因之一。
此外,研究者强调,ReviewAdvisor 系统可能会生成不正确、不完整或者带有偏见的评审结果,这些评审结果不能代替人类专家的评审结果。
优秀同行评审有哪些标准?
该研究首先总结了评估同行评审结果的常用标准:
- 决断性(Decisiveness):好的同行评审应该立场明确,对是否接收论文提出明确建议;
- 全面性(Comprehensiveness):好的同行评审应该有条理,首先简要总结论文贡献,然后从不同方面评估论文质量;
- 正当性(Justification):好的同行评审应该有理有据,尤其是在指出论文缺点时要明确理由;
- 准确性(Accuracy):好的同行评审应该确保事实正确;
- 友好(Kindness):好的同行评审应该措辞礼貌善意。
数据集
该研究介绍了如何构建具有更细粒度的元数据的评审数据集,该数据集 Aspect-enhanced Peer Review (ASAP-Review) 可用于系统训练和多角度的评审评估。
数据收集
研究者通过 OpenReview 爬取了 2017-2020 年间的 ICLR 论文,通过 NeurIPS 论文集爬取了 2016-2019 年间的 NeurIPS 论文。对于每篇论文,研究者都保留了尽可能多的元数据信息,包括如下:
- 参考评审,由委员会成员撰写;
- 元评审,通常由领域主席(高级委员会成员)撰写;
- 论文接收结果,即论文最终被「接收」还是「拒稿」;
- 其他信息,包括 url、标题、作者等。
该研究使用 Allenai Science-parse 解析每篇论文的 pdf,并保留结构化的文本信息(例如标题、作者、章节内容和参考文献)。下表 2 显示了 ASAP-Review 数据集的基本统计信息:
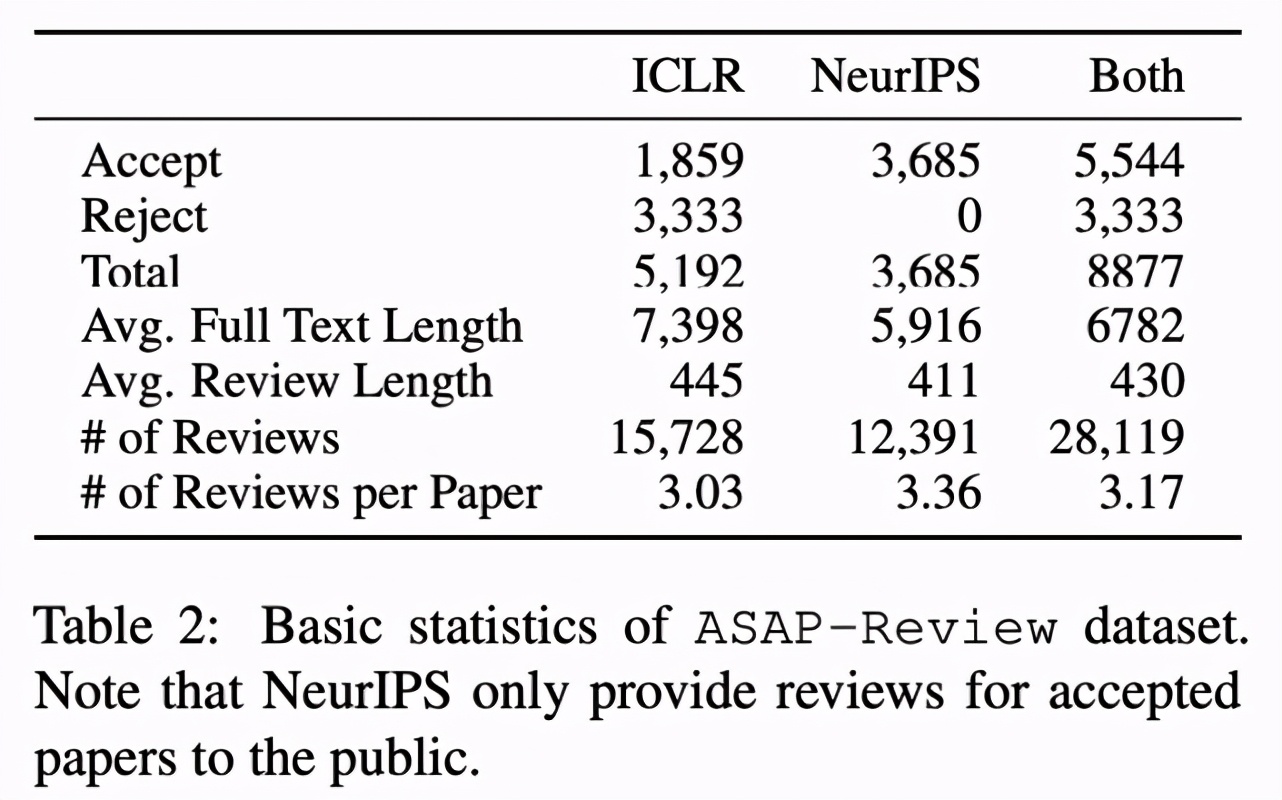
Aspect-enhanced Review 数据集
尽管评审呈现出下图 3 所示的内部结构:评审通常以摘要开始,然后分方面列出不同观点,并给出证据。实际上,这种有用的结构化信息并不能直接获取。考虑到评审中各方面的细粒度信息在评估中起着至关重要的作用,该研究对评审进行了方面注释(aspect annotation)。为此,该研究首先介绍方面类型(aspect typology),然后进行人工注释。

该研究定义的类型包含以下 8 个方面,遵循 ACL 审核指南,并做了一些小改动:
- 摘要 (SUM)
- 动机 / 影响(MOT)
- 原创性(ORI)
- 可靠性 / 正确性(SOU)
- Substance(SUB)
- 可复现性(REP)
- 有意义的对比(CMP)
- 清晰度(CLA)
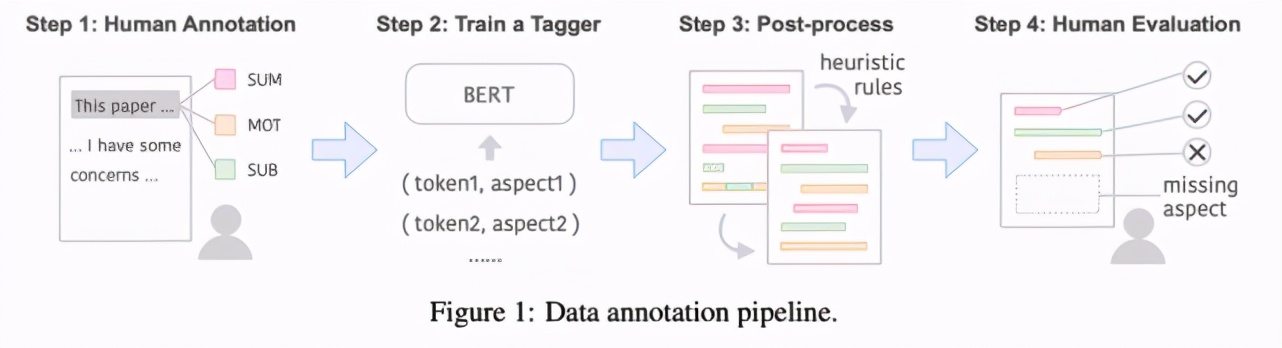
总体而言,数据注释涉及 4 个步骤,如下图 1 所示:
ReviewAdvisor 如何生成科学评审结果?
首先我们来看什么是「科学评审生成」任务。该任务可以被概念化地理解为基于 aspect 的科学论文摘要任务,但存在一些重要的区别。例如,大部分当前的工作要么从「作者视角」总结论文(即仅使用作者所写的内容构建摘要),要么从「读者视角」进行总结,即认为论文摘要应考虑研究社区成员的视角。
而 CMU 研究者在这项工作中将科学论文摘要的视角从「作者」或「读者」扩展到了「评审」,并认为好的科学论文摘要不仅应反映论文的核心 idea,还要包含领域专家从不同方面做出的重要评价,而这需要源论文以外的知识。
这一想法的好处在于:1)帮助作者发现论文中的缺陷,使之更强;2)帮助评审者缓解一部分评审负担;3)帮助读者快速掌握论文主要思想,并了解「领域专家」(即该研究创建的系统)对论文的评价。如下图 3 所示:

系统设计
该研究创建的评审数据集包含的训练样本少于其他基准摘要数据集,不过近期语境化预训练模型的少样本(few-shot)学习能力使得基于该数据集训练评审生成系统成为可能。该研究使用 BART 作为预训练模型,该模型在多个生成任务上展现出卓越的性能。
然而,即使有了 BART 的加持,如何使用它处理长文本仍是一大挑战。经过多次试验后,研究者选择了一种两阶段方法。
利用两阶段系统处理长文本
该研究利用「提取 - 生成」(extract-then-generate)机制,将文本生成分解为两步。具体而言,首先进行内容选择,即从源论文中提取显著文本片段,然后基于这些文本生成摘要。
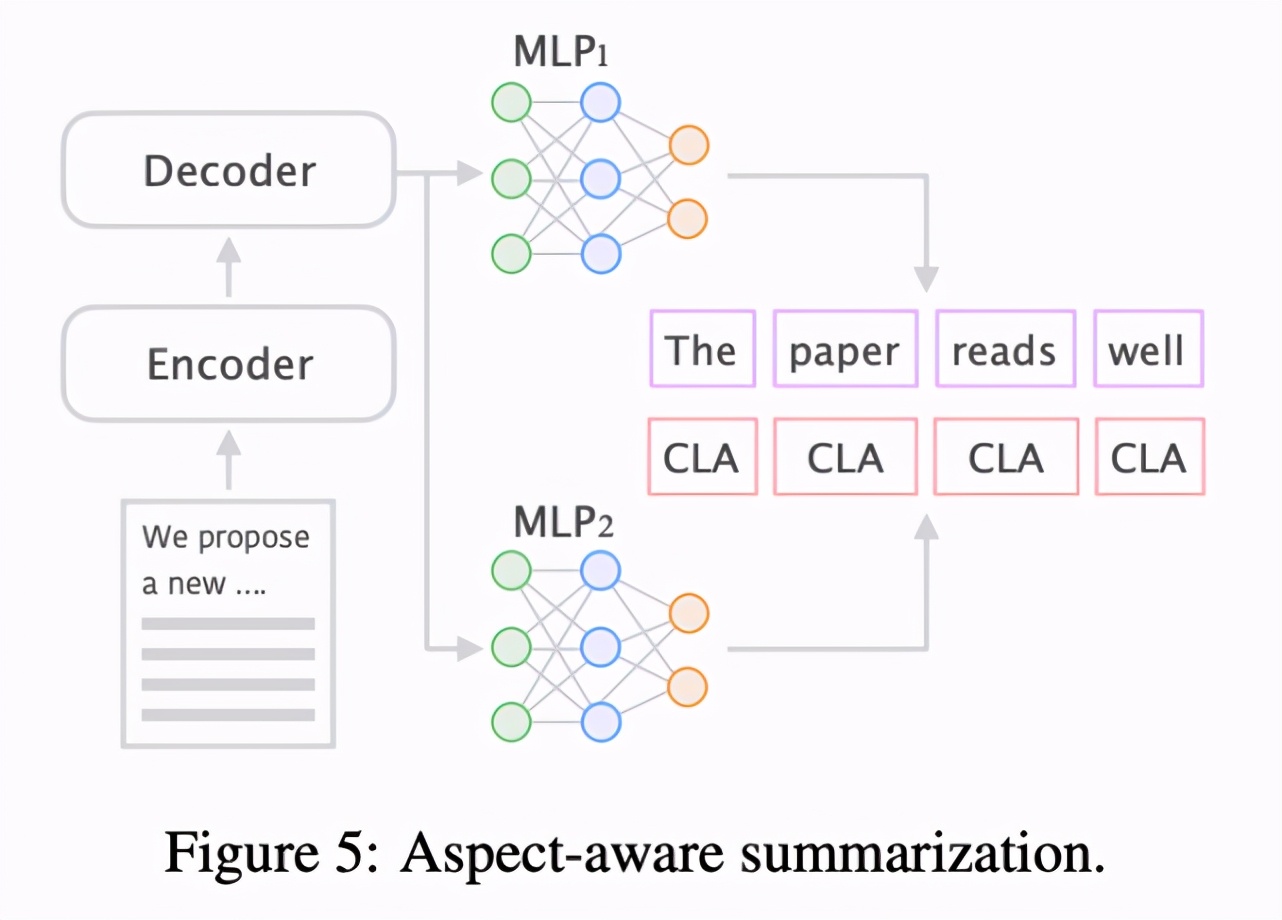
aspect 感知的摘要(aspect-aware Summarization)
通常在 extract-then-generate 机制中,可以直接使用提取内容,并构建用于生成文本的序列到序列模型。为了生成具备更多样化方面的评审结果,以及透过其内部结构解释评审结果,该研究更进一步提出了 extract-then-generate-and-predict 生成框架。
具体而言,研究者使用其标注 aspect 作为额外信息,设计了一个预测生成文本(评审)aspect 的辅助任务,参见下图 5:
实验
研究者通过以下两个问题,来评估该系统的效果。
该系统擅长什么?不擅长什么?
基于该研究定义的评估度量指标,研究者对参考评审和生成评审进行了自动评估和人工评估,来分析自动评审生成系统在哪些子任务上发挥良好,又在哪些子任务上失败。下表 5 展示了评估结果:
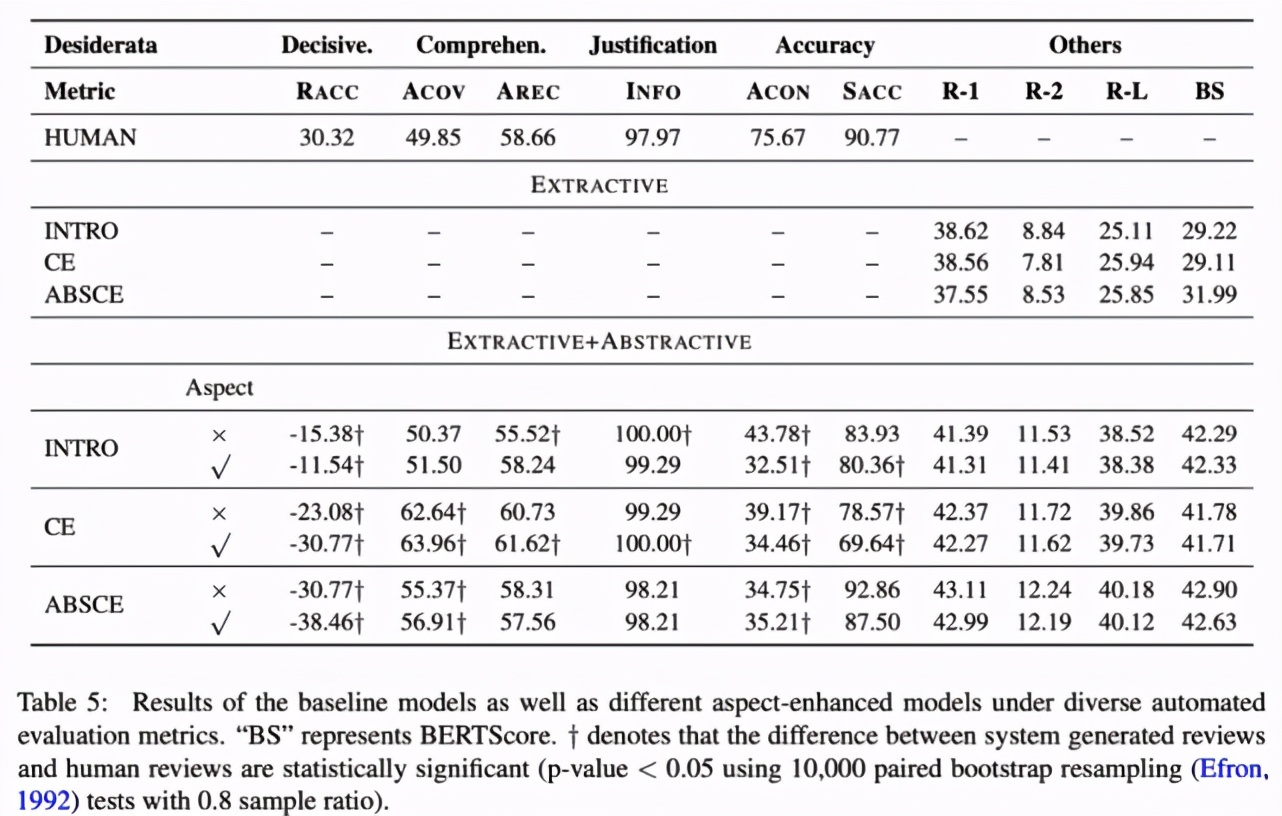
实验发现,该评审生成系统存在一些缺陷,主要表现在以下几个方面:
缺乏对论文的高级理解:系统无法准确分辨高质量论文和低质量论文,大多数时候负面 aspect 的证据并不可靠;
模仿源数据的风格:在不同生成评审结果中常出现某些特定句子,这表明生成评审的风格易受训练样本中高频句子模式的影响;
缺乏问题:生成评审很少对论文内容提出问题,而这是同行评审的重要组成部分。
当然,该系统也有一些优势。它通常能够准确总结输入论文的核心思想,生成评审覆盖的论文质量 aspect 也多于人类评审人员。
案例研究
研究者还进行了案例研究,下表 6 展示了示例评审结果。从中可以看出,该模型不仅能生成流畅的文本,还能意识到生成文本是关于哪个方面及其正确的极性。例如紫色部分是「摘要」,黄色部分是「清晰度」,+ 表示评论较为正面。
虽然生成的方面通常是小型文本片段,还存在一些微小的对齐问题,但该模型仍然能清晰地感知到不同方面。

系统生成的评审带有偏见吗?
文本中的偏见普遍存在,但检测难度高。该研究除了设计生成评审的模型外,还提出了一种偏见分析方法,以便更细粒度地识别和量化人类标注和系统生成数据中的偏见。
首先是度量评审中的偏见。下图 6 展示了参考评审和生成评审之间的差异:

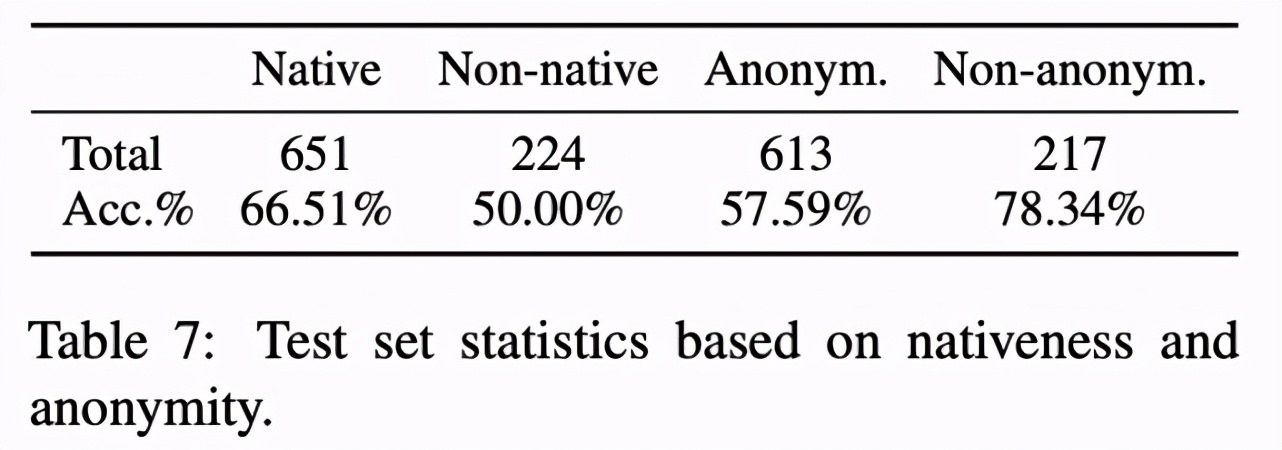
该研究按照「Nativeness」和「Anonymity」将所有评审进行分类,详情参见下表 7:
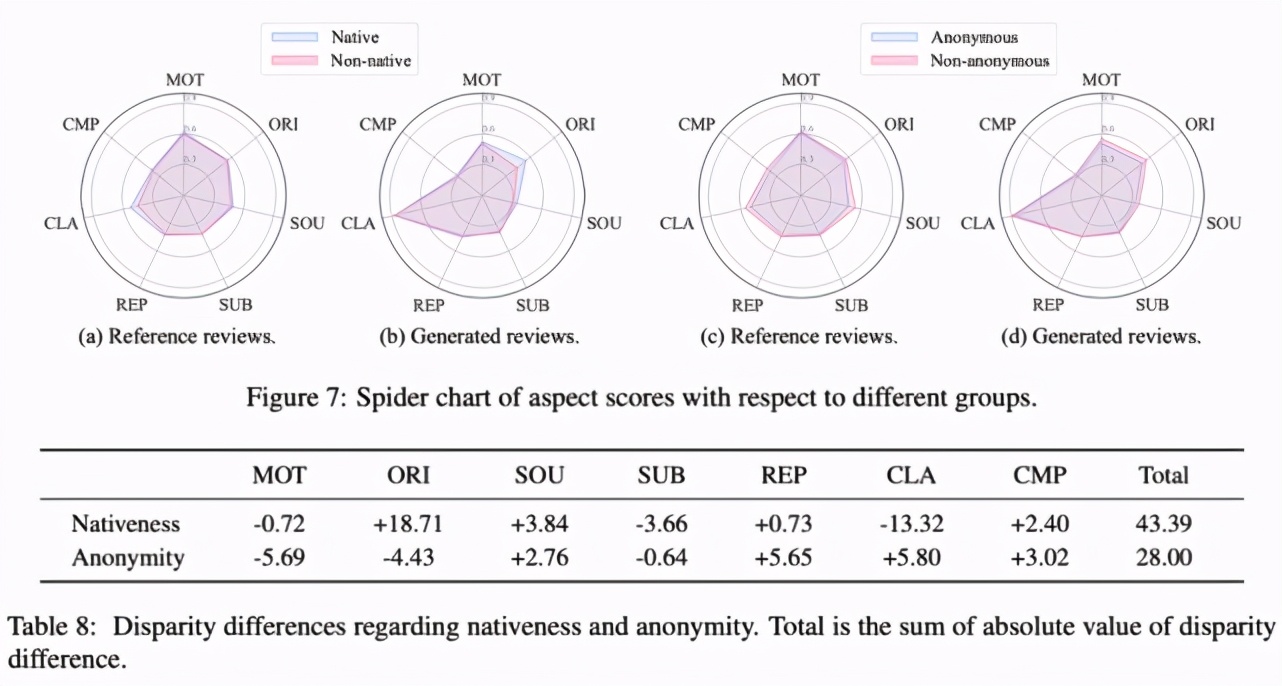
分析发现,Native 论文(即作者列表中至少有一位英语母语者)和非匿名论文的参考评审和生成评审得分更高。具体结果参见下图:
在论文最后,研究者还列举了自动评审生成系统面临的八项挑战,涉及模型、数据、评估三个方面,分别是:长文本建模、针对科学领域的预训练模型、结构信息、外部知识、更多细粒度评审数据、更准确和强大的科学论文解析器、生成文本的公平性和偏见、真实性与可靠性。
回到这个问题「科学评审可以自动化吗?」,答案依然是「还不能」。
但是,说不定在不久的将来,自动评审生成系统能够至少帮助人类评审更快速、高效地完成评审工作。