












一、人脸识别背景介绍
简单来讲,人脸识别这个问题,就是给定两个人脸,然后判定他们是不是同一个人,这是它最原始的定义。它有很多应用场景,比如银行柜台、海关、手机解锁、酒店入住、网吧认证,会查身份证跟你是不是同一个人。这个应用的主要特点是,在大多数场景下都需要你先提供一个证件,然后跟自己的人脸做比对。手机解锁可能是个例外,但也要求你提前注册一张人脸,然后再进行比对。这是最原始的形式,由用户直接提供需要对比的两个人脸。这也是最简单的形式,相当于做一个二分类。
进一步来讲,如果想要去做人的搜索呢?比如我们有一个大小为 N 的人脸库,有一张待检索的图片,让我们判断这个人有没有在这个人脸库中出现过。这种情况下,要回答的就有 N 个问题了,分别是:这个人脸是不是库中的人脸1、是不是人脸2,一直到是不是人脸N。如果这 N 个问题回答都是“否”的话,就意味着这个人不在人脸库里面。不在人脸库是一个很难的问题,等于 N 个问题都得回答对,然后才能真正确认它并不这个人脸库里。
实际使用时一般是静态的搜索,比如有一个公安的民警,他从视频或者图片里找到目标人物,把他的脸框出来,然后提交到系统里,在库里面做搜索。然后系统会返回,比如 Top K,K 一般是几十或者100这个量级的数字,会按照相似度把这些人脸排出来,然后人工验证到底哪些是对的。如果 Top 1 就是对的那最好,一般如果能够排到 Top 10 就算是不错的结果,但在 100 名以后的话,这个结果很难对使用的人有帮助了。如果允许TopK的话,这个底库是可以做到比较大的,因为并没有要求一定放到 Top 1。
公安评测时,在各个省公安的环境上做评测,底库一般都比较大,到千万的量级甚至到亿的量级,这也是因为最近几年深度学习发展的非常快。最早期时只能做静态检索,而且结果还不太好,随着深度学习算法的发展,现在很多公司的算法都越来越好了,评测的时候也会很难区分各个厂家的算法到底谁好谁坏,所以测试本身这个问题越来越难,用来检索图片的质量也越来越苛刻,实际应用中很多问题也很苛刻,比如嫌疑人在摄像头里出现距离比较远,有侧面的,或者帽子遮挡,戴眼镜等现象。
给大家举个例子,下面是我在互联网上找到的明星的照片,在真实场景里 query 的质量跟这个差不多,有的时候比这些更难一点。现在主流人脸算法解决这种问题时,当底库是千万量级时,TOP1是召回率还是很高的,百分之八九十的问题不是很大,甚至还会更高一些。

当然,在安防或者其他应用场景里有更难的任务,就是人脸的 N : N 搜索,这种情况下我们会有大量的摄像头,每一个都在实时抓拍,有非常多待确认的抓拍人脸,同时库也是相对比较大的。举个例子,在安防领域,假设我们有 100 个摄像头,然后每个摄像头每天抓拍 1 万个人,那么总的搜索次数就是 100 万次。假设这一天有 10 个嫌疑人被摄像头抓拍到,假设我们需要在一个 10 万大小的底库里面去搜索他们。我们有一个算法,这个算法这一天总报警 100 次,警察每一个都去确认,最后抓到了 9 个嫌疑人,这看起来还不错,因为总共出现了 10 个人,抓到了 9 个,召回率是 90%。那我们来看看误报率,100 次报警,对了 9 次,错了 91 次,误报率就是91 除以 100万×10万,大概算下来是 10亿分之0.91,约为 10亿分之1 的误报率。

这个指标在现在的人脸识别算法里还算比较不错的了,但是在公安民警看来没有那么理想,因为他们出警了 100次,只抓到了 9 个人,他们非常想出警 10 次就抓到 9 个人,这样成本就会低很多。那我们来看一下出警 10 次抓到 9 个人的误报率是多少呢?看起来少了一个数量级,但实际上要求误报率要提高两个数量级,因为这个时候误报的次数只有 1 次,1 除以 100万×10万,就是已经到了千亿分之一,这个就非常难达到。即使有一个千亿分之一的算法也只能支持 100 个摄像头的需求,在很多城市里轻轻松松就有上万个摄像头,甚至几十万个。所以算法还要在误报率方面再降低 N 个数量级,或者要求我们有更聪明的使用方式,在还有很多研究的空间。
还有一类应用是人脸虚拟 ID 的聚类,虚拟 ID 就是我们不知道每个人的证件信息,只有大量的摄像头抓拍结果,我们想根据这些人脸的图像特征和出现的时间、空间等先验信息进行聚类,这样可以挖掘用户的轨迹和行为习惯。这些信息在很多场景下非常有用,最简单的是人脸相册的聚类,这个应用很简单,因为你只需要在一个人的相册里做聚类就可以了,库很小。但在安防、零售等场景都是城市级的数据,这个做好的话可以带来很有价值的信息,比如谁跟谁经常在一起活动,从 A 点到 B 点到 C 点到 D 点有什么异常,像这些人员流动的异常,在很多地方,尤其是新疆、西藏等 ,大家都非常关注。
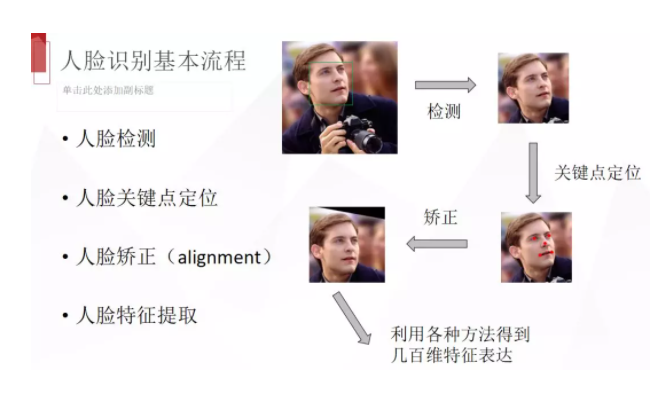
人脸识别的基本流程,首先要检测到人脸,检测到之后一般会做关键点的定位,把他的眼睛、鼻子、嘴角等信息都定位出来,利用这个信息对人脸做个矫正,把它变换到比较正情形,便于后面模型分析或者处理时各个部分更好的对齐。最终会提取得到一个人脸的描述特征,通常是一个 100 多维到几百维的特征表达,然后我们用不同人脸特征之间的相似度或者距离,相似度是越高越好,距离是越小越好,去刻画两个人之间的关系,再卡一个域值,来判断这两个人是否为一个人。这次我们讲人脸识别主要就是最后的人脸特征提取的部分。
▌二、人脸识别前沿算法简介
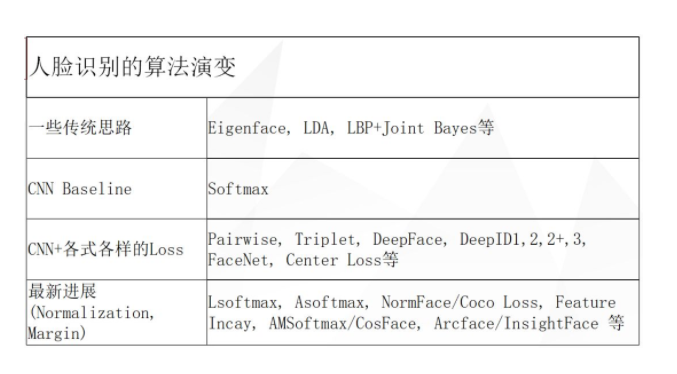
人脸识别传统思路挺多的,我只列了一小部分。下面我们来一一回顾这些基本的算法:

首先是 Baseline,早在八十年代末就可以做基于 CNN 的分类了。如果想把这套东西用在人脸上的话只需要做简单的替换。字符的输入替换成矫正之后的人脸输入。LeNet5 可以换成 ResNet 以及后面的各种改进。然后是分类,人脸有多少个 ID 就可以分多少类。然后我们训练完网络后就有了特征,比如可以把最后的 FC 的输出当做人脸的特征。
当然,也会有潜在的问题,如果类别太多,会不会训练不动?比如你在做认证的应用时,每一类的训练图片会不会样本太少?如果你在训练集上的分类结果非常好,但对于新的 ID 怎样呢?分类的模型训练得好,能够代表学到的特征在人脸识别应用的时候非常好吗?这些问题都有人在研究,有一些也会在后面的介绍中体现出来。
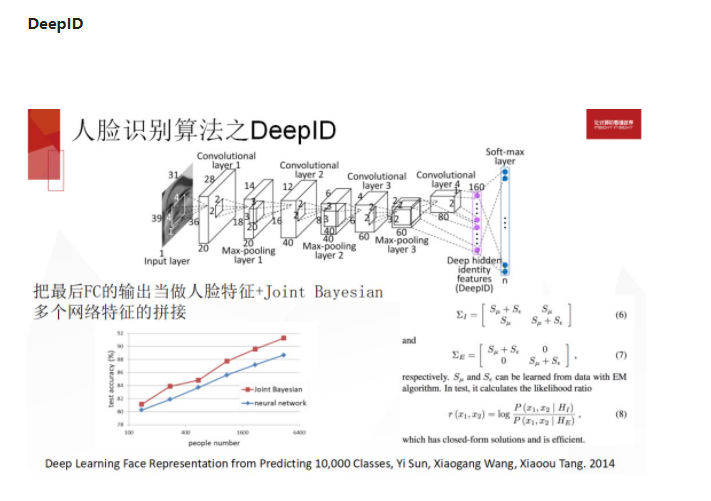
DeepID 这个算法是刚刚那个思路的具体实现,有一些更细节的调整,它在得到最终的人脸特征之后,又做了一个基于概率统计的降维。它这个特征也是多个特征的融合体,你可以理解为它对人脸上的很多关键区域都训练了一个 CNN 网络,去做分类,得到隐层特征,把这些特征拼接在一起,再做某种意义上的降维,得到最终特征,用这个特征来做描述。这是最早的 DeepID。

DeepID2 做得更细致,它希望同一个人的特征尽量近,不同人的特征可以比较远。两张图作为输入 ,每一个都用一个 CNN 去提取特征,这两个 CNN 网络是共享参数的,通过这个 Siamese Network 来判断他们是不是一个人。如果他们是一个人的话,我们要求特征之间的欧式距离比较小,如果他们不是同一个人的话,我们希望他们之间的欧式距离至少大于等于 m。可以从这个 Loss 里看到,它一旦小于 m 就会受到惩罚,只有大于 m 时才是安全的。人们希望这种方法使得特征的表达更清楚。这个方法不需要依赖特别大的 FC 层,不管你真实的人的ID有多少,你都是在做一个类似于二分类的事情。同时,它也可以跟之前的 DeepID1 里面的 softmax 一起使用,这样会有一些提升。
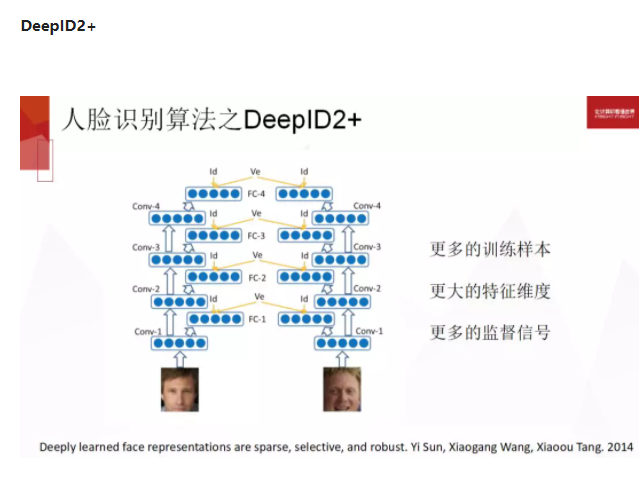
DeepID2+ 做了一些小的修改,更多训练样本,更大的特征维度,更多的监督信号,在网络中间的很多层都连接到了最终的分类和验证的卷积函数,有点类似于 GoogLeNet,不过那时 GoogLeNet 还没有出来。
DeepFace
DeepFace 在算法上并没有什么特别的创新,它的改进在于对前面人脸预处理对齐的部分做了精细的调整,结果显示会有一定的帮助,但是也有一些疑问,因为你要用 3D 的Alignment(对齐),在很多情况下,尤其是极端情况下,可能会失败。人脸识别的算法发展得非常快,有很多不同思路和做法,但是在不同的应用类型中是不是真的都能 work的比较好,需要尝试之后才能下结论,不一定能普适的应用。
DeepID3
DeepID3 是 2015 年的工作,那一年正好是在 GoogLeNet 和 VGG 出来的那一年,所以作者把比较深的卷积网络模块加进去了,有一些提高。
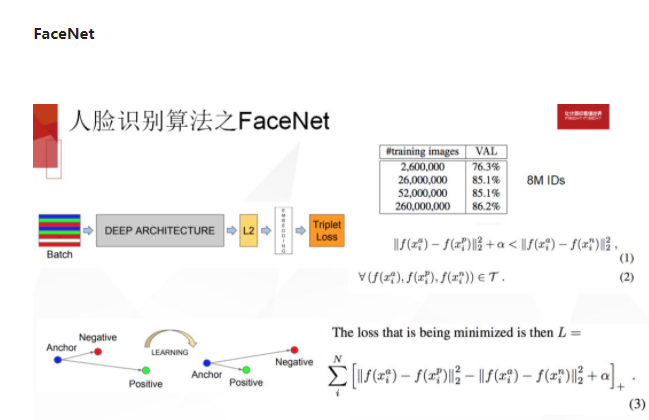
Google 的 FaceNet 不太一样,它用的是 Triplet Loss,这跟它自己的数据量有直接关系,之前那几个论文都是基于公开的数据,人脸 ID 数在 1 万的量级左右。但 Google 的互联网数据非常多,它做得最大的实验用到了两亿六千万的人脸数据,总 ID 数大概在 800 万左右。所以在那个时候,Google 从一开始就用了 Triplet Loss,意思就是它有三个样本的对,其中有一个叫 Anchor一个叫 Negative,一个叫Positive。Positive 的意思就是它跟 Anchor 是同一类的,如果跟 Anchor 不是同一类就是 Negative。
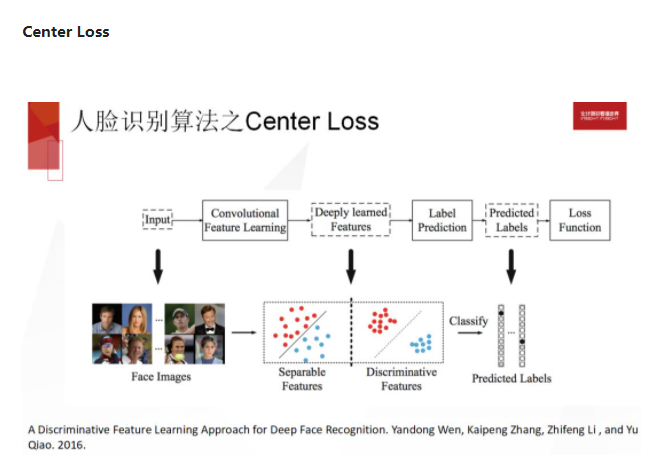
Center Loss 则更加直接一点,它做 Softmax 的时候不仅仅是分对,而是希望每一类更加紧凑一些,更加直接。它的 Loss 函数比较简单,相当于 xi 是每张图片的特征,yi 是它的标签,Cyi 就是对某个类的一个中心,相当于每张图片的特征在学,然后每个类的类中心同时也在学,希望属于同一类的那些样本的特征都离它们自己的类中心比较近。这个跟 softmax 合并在一起出现一个新的 Loss,这样学出来的特征在欧氏距离下就更加能够表达不同人脸之间的相似度关系。
前面几个算法都是相对比较传统的、比较老一点的,在现在人脸识别系统里用得人比较少。总的来说,它们大部分都是从 Loss 设计方面做了改进,然后跟softmax进行配合。但 Google 是一个例外。然后下面几个感觉更加有效的方法则基本都是在 softmax 的基础上再进行深入的探索。

第一个比较重要的、改动比较大的工作是 L-softmax(Large-Margin Softmax),它的意思是我在做分类时,希望不同的类之间能够区分得更开,把同一个类压缩得更紧,但它跟之前的思路有一定的相似性,但并没有通过额外的限制来做,它深入分析了 softmax loss 的形式,直接对这个形式做了精细的改动,把其中的cosθ改成了cosmθ,起到了增加 margin 的效果。这里还有一些处理细节,比如当 mθ 超过一定范围时要重新定义等等,但是大的思路比较容易理解。
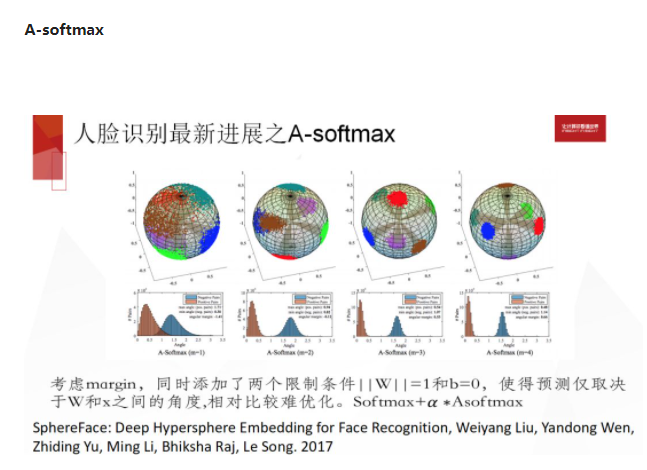
A-softmax 则是在 L-softmax 上做了一个很小的修改。它们虽然是两篇论文,但其他所有东西都跟 L-softmax 一模一样。A-softmax 就是在考虑 m 倍的 θ 这个 margin 的同时要添加两个限制条件,第一个是 W 的 norm 要是一个固定的值,我们把它的值固定为 1,其次我们把 B 直接设置为 0,因为它跟W相比只有一维维度,所以感觉上不太会很影响这个网络的表达能力,同时它还可以让解释变得非常自然,使得在这种情况下模型的预测仅仅取决于 W 和 X 之间的角度。但事实上,如果真的去尝试这个算法,会发现这个 margin 加的是非常强的,比如 θ 是 30 的时候,就是当某个样本离它的类中心 已经只有30 度的情况下,在 m=2 的时候它会保守的认为,样本离类中心还有 60 度,所以这个限制很强,是比较难优化的。真正用的时候是 softmax+α 倍的A-softmax 优化,α 一开始是约等于 0,等于是一开始在优化 softmax,随着优化的进行,α 逐步有些提高,能起到一些 A-softmax+margin 的效果。

刚刚的 A-softmax 是从 margin 的角度来讲的,后面出现了两篇论文,NormFace 和 CocoLoss,是从 Norm 的角度来分析这个问题的。它在对 softmax 做改进的时候加了两个限制,一个是特征,每个样本特征的 Norm 要是 constant 的,就是希望所有样本学出来的特征模长都是固定的数字。同时,分类时有一个 W 的参数矩阵,希望参数矩阵的每一列 Norm 也都是一个固定的数字。
有两篇论文同时看到了这一点,就是在不考虑 margin 的情况下,仅仅去考虑这两个 Norm 的限制,听起来是很简单的思路,正好两个工作也做重了,它俩几乎在同一时间发表,内容也几乎是一模一样的。但这里面我选择介绍下 NormFace,它的论文分析看起来更深入一些,而且讲到了normface 跟 triple loss(当用 agent 代替一个类中心的时候)之间的一些联系。还有一点,从这里开始,人脸识别的特征对比就不再用 L2 的距离了,基本上全面转向了cos 距离。因为在这种情况下,L2 和 cos 距离其实是一样的。
这点其实也是很重要的,我们可以看到在早期的 Google 的 FaceNet 里面,它对feature也做了一个 Normalization,就说明它早就发现了这一点,这个对特征做 Normalization 会有帮助。但是如果你想深入的看一看为什么要对特征做normalization,为什么要加 margin 在 softmax 里面?其实也有一些理论上的东西来分析这个,我可以跟大家介绍两个简单的想法。

- 第一,为什么要 normalize 特征?
有一个性质,如果大家仔细想一想的话会觉得非常有意思,就是当一个样本如果已经处于分对的状态,也就是说它已经距离自己类中心的 Wi 最近的的话,这时 softmax loss 本身会随着这个 feature 的模长而递减,也就是说如果你已经分对了,softmax 继续优化的时候会朝着让你模长更大的方向去走,但这对最终效果没有任何帮助,因为只是模长在变,跟类中心的夹角并没有改变,但是从 softmax 的角度来看,它的 loss 竟然下降了,就意味着我们不能自由的去学每一个样本的特征,我们希望它的特征受到一些限制。Normalize 特征,就是特征模长受到限制,也就是 norm 等于 1 或者等于一个常数。
- 第二,为什么要加 margin?
同样有一个类似的性质说,如果说你的特征对于某个人脸的图片分类已经概率很高了,比如它应该是属于第 10 类的,你现在的模型预测出来它属于第 10 类的概率非常高,比如已经0.999,这种情况下你去看样本的梯度,发现它的梯度几乎约等于 0。说明在某个样本在几乎分对的情况下,训练过程不会再把这个样本朝着这个样本的类中心继续压缩了 ,默认的 softmax 是没有产生margin 的能力的,所以 margin 这一项需要单独加。
总之,直观理解就是在 softmax 这个 loss 上,如果你想让特征学得更有意义和特征更加紧凑,一定要单独去考虑 feature 的 normalization 和 margin 应该怎么加。

关于 margin 刚刚只讲了一个,就是 Asoftmax ,其实还有其他的几种形式,第一个是AMSoftmax,还有一个叫 CosFace,这两个是同样的想法,内容也基本是一模一样的。Margin 是指的类似于 SVM 里面的那种分类面之间要有一个间隔,通过最大化这个间隔把两个类分得更开。在 AMSoftmax 里面本来 xi 和类中心的距离是 cosθ,不管是 ASoftmax 还是 AMSoftmax,都是想把这个数字变小一点,它本来相似度已经 0.99 了,我希望让它更小一点,使得它不要那么快达到我想要的值,对它做更强的限制,对它有更高的要求,所以它减 m 就相当于这个东西变得更小了,xi 属于应该在那个类的概率就更难达到 99% 或者 1,这个 θ 角必须要更小,这个概率才能更接近 1,才能达到我们想要的标准。右边也是一样的,这两个公式几乎完全一模一样,同时大家都在要求 W 的 norm 要是固定的,x 的 Norm 要是固定的,我们只关心 cos 距离

第三个跟前面的两个非常像,叫 InsightFace,也叫 ArcFace,虽然是两个不同的名字,但实际上是一篇论文。这三种方式都是让 cosθ 变得更小,第一个是通过 θ 乘以 m 的方式变小,第二个是通过 cosθ 减 m 的方式让 cosθ 变小,第三个是通过 θ 加 m 的方式让 cosθ 变小。因为 cos 这个函数对 θ 是单调递减的,所以让这个函数变小,第一种是让 cos 减去一个值,第二种是让里面的 θ 变大,变大有几种方式,一种是乘以 m,一种是加 m,其实这三种方式是可以统一起的。
文里面作者提到, ArcFace 跟 CosineFace 相比,在训练一开始,所有类之间每个类的样本跟它类中心的距离是比较远的,随着训练进行,它们越来越紧凑 ,ArcFace 可以做到更加紧凑的
同时,这三种方法可以和合并成一个公式,可以在 θ 上乘一个 m,然后再加上一个 m2,cos 算完之后可以减 m3,这三个参数,不管哪个调整,都可以让函数比原来设定得更小,这在 softmax 里面就意味着加了更强的 margin。有些实验结果表明,单独调每一个都不一定是最优的,它们联合起来调整可能有更好的结果。但在几何上具体是怎样的现象,就比较难以描述,可能需要更多的研究。
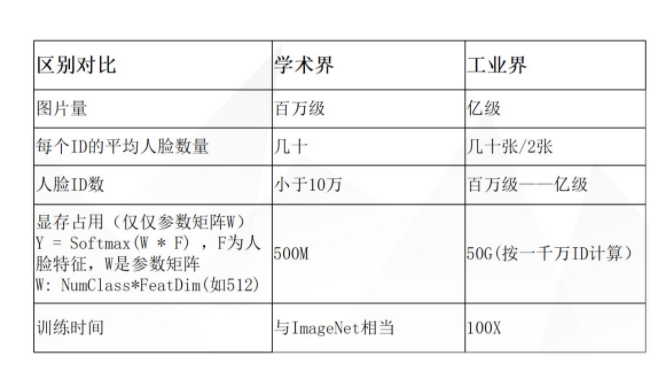
新的算法简单就回顾到这里,这些算法大家平时用起来不会觉得有些问题,在学术界公开的训练集上也能得到比较好的效果。但是学术界跟工业级是有很大区别的,主要的几个区别在于以下几个方面:图片量、每个ID的平均人脸数量、人脸ID数、显存占用、训练时间。
▌三、分布式人脸识别训练
我们设计了简单的分布式人脸识别的训练框架,想法很简单,就是数据并行+模型并行。
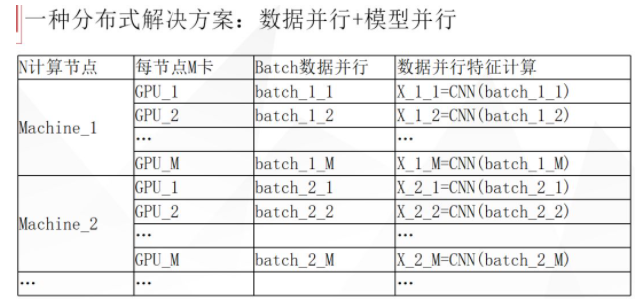
首先是数据并行,假设我们有 N 个计算节点,N 台机器,每台机器有 M 张卡。首先,我们通过数据并行,把一个大的 batch 平均分到每张卡上,然后每张卡跑一个同样参数的 CNN 网络,得到那部分数据的特征,然后对这些特征做多级多卡的汇聚,得到所有 batch 里面数据总的特征是X。为什么要做特征汇聚?主要是因为后面的模型并行。
模型并行把原来一张卡上的 W 参数矩阵平均拆分到多张卡上,举个例子,现在让第一张卡来负责预测每个样本属于 0-10万 类的概率,第二张卡预测属于 10万-20万 类的概率,比如一个卡负责 10万类,总共我们有 100 张卡的话,那就可以做 1000 万类的分类。参数拆分之后,每张卡上就可以计算每个样本属于每个类的概率了,但这个地方需要通信,因为你要计算类别的话,需要做一个指数操作,然后得到所有卡的指数的总和,然后除一下才能知道。但好处是通信量很小,每张卡只需要负责计算它自己那部分的和,然后把这个和同步给其它GPU就可以了,而和的话就只有一个数字(当然这里有一些细节,如果考虑到计算稳定性还需要同步比如像最大值之类的信息,但通信代价都很小)。
一旦计算出了每张卡上每个样本属于自己卡负责这部分类别的概率之后,剩下的事就容易做了,因为我们看到下图中的偏微分公式,它只依赖于这个 Pk 的概率,我们得到了这个 Pk 概率之后,就可以直接写出来目标函数相对于算出来的 fk 的导数是什么,相当于你可以同时拿到损失函数对 W 的导数和对 X 的导数。但损失函数是被拆分在多张不同的卡上,所以对 X 这部分导数还需要做多机多卡的汇聚,得到对总的特征的导数。对 W 参数的导数,每张卡是独立的,互相之间并不影响,所以每张卡自己更新就行了,也没有通信传递。对所有 X 的梯度求和的通信量也不大,得到对 X 的导数之后可以沿着前面正向传播的路径,多机多卡的反向传播过去就可以了。
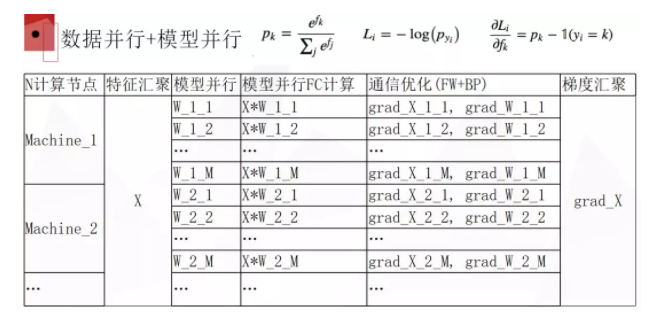
数据并行是很成熟的技术,比如之前有很多报道,说很多人都可以在多级多卡的环境里面训练 ImageNet 的数据集,好像大概一个多小时就能训完了。我们把模型并行这部分也加进去了。模型并行也没有那么复杂,主要是考虑机器之间的通信量能受控就可以。所以这样的思路实现起来比较简单,而且可以把模型显存占用和计算量都均匀分散到每个 GPU 上,实现线性加速,也没有增加额外的通信带宽,甚至它降低了 FC 层的梯度更新所需要的带宽。原来 W 矩阵不做拆分的时候,多张卡之间要同步对 W 的梯度,W 拆分到每张卡之后梯度反而不需要同步了。
这样的情况下,我们测试实际的网络环境可以支持 100 卡以上的训练,在 512 维特征的情况下做到几千万类的人脸识别,如果维度降低一点,比如压缩到 128 维,可以支持到上亿类的人脸识别,而且随着卡的增长,也不会带来的性能损失,基本上是线性加速。它的好处是支持大部分主流损失函数的扩展。

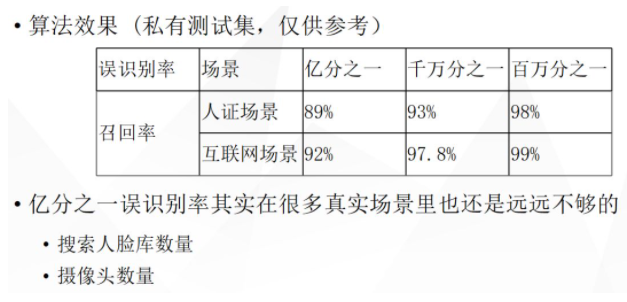
下面是一个简单算法的效果展示,基于这种思路,不做其他的修改,在数据量还可以的情况下,很容易做到亿分之一的误识别率,召回率在 90% 左右,如果是互联网产品可能更高一点。但是我刚刚在前面也说了,随着人脸库数量的增加和摄像头抓拍量的增加,亿分之一的识别率还是会有很多误报的,需要持续改进。
还有很多影响人脸识别的重要因素,我这里简单列一下,感兴趣的同学可以去关注:

之所以要做这个事情有几个原因:
第一,学术界曾经有很多非常有名的测试集,比如 LFW 有 6000 对人脸 1:1 认证。但现在有很多算法都可以达到 99% 以上甚至 99.8% 的好成绩,所以这个效果已经不能很好的衡量算法的好坏了,可能两个同样在 LFW 上达到 99.8% 的算法,换一个数据集时结果会差很多。
第二,MegaFace 在学术界也是非常有名的。它的测试条件是在 100 万干扰项中找到目标人脸,一开始的时候大家觉得这是个很难的问题,但随着学术界几年的研究,排行榜的第一名已经超过 98.9% 了,看起来也有一定的饱和趋势。这里面一开始是有些噪音的,后来被一些研究人员发现之后做了些清理,就发现这个测试集没有想象得那么难。另外,它提供的正样本人脸对的比较有限,正样本每个人的变化并不是特别的大,导致这个问题可能并没有一开始大家预想的那么难。
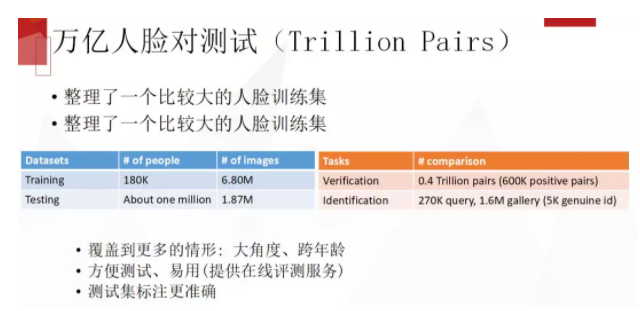
于是,我们想办法去扩充做一个更大规模的训练集,希望做更客观的评测,帮助在人脸方面做研究的同行们有一个未来几年还可以继续用的测试平台。我们做了两件事情,第一个是做一个比较大的人脸训练集,第二个是做比较大的人脸测试集。训练集大概是有 18 万人,共有 680 万张图片左右,测试集大概有 187 万的人脸。
下面简单介绍这些训练集的制作及清理过程,训练集一部分是基于公开的 MS-Celeb 上做了清理,去掉了重复的名人,然后又收集了一个亚洲人的名人库,大概也有 10 万个ID,再把两个合并一起做除重,最后合并数据。MS 这个数据集有两种噪声,一个是类内的噪声 ,也就是说每个类并不只包含一个人。还有一个是类间的噪声,同一个演员出现在不同的电影里面,或者有多个不同的名字,就被分在两个不同的类里面。
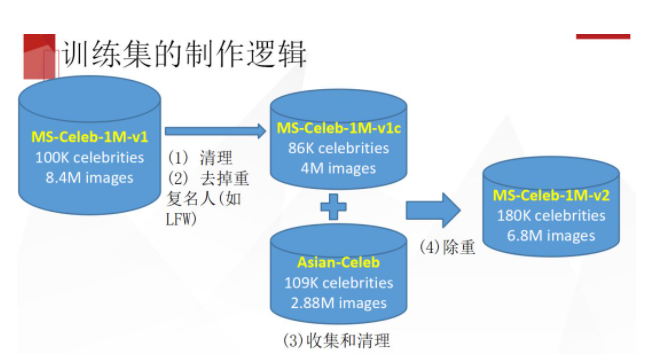
清理流程是首先检测和align之后,用一个比较好的模型去提特征,在这个过程中顺带可以把原来数据集中的误检测去掉。具体清理的时候,我们对原来每个类都做一个层次聚类。我们为了数据集的纯净,只把每个原始类里面聚类之后最大的簇保留起来,保证每个类别里是足够c lean的。但每个类只保留最大的簇是不是最好也值得商榷,现在初步的版本是保留最大的。
第二个是减少类间的错误 ,比如这两类是同一个人,但一个是电影角色的名字,一个是他自己的名字。当初M s-celeb数 据集在整理的时候,是用图片和它周围的文本信息做的聚类,所以它不可避免会有一定比例的这方面的错误。我们做清理的时候,首先对每个类得到它的主簇,然后两个不同的类,如果我们去比较两个类中任何两个图之间的最小距离,如果发现它们小于某个阈值的话,说明两个类有可能可以被合并 ,然后让标注员标注一下,确定真的是同一个人的话就会标在一起,通过这种方式来尽可能减少类间错误 。
还有亚洲的名人数据集,因为之前的 MS 中欧美人比较多,我们又爬了大概十几万的亚洲名人的数据,经过类似的清理过程,最终得到了 10 万的 ID,200 多万的人脸。总的来说,亚洲名人数据集跟原始的 MS 相比,会更不均衡一些,怎么去解决不均衡以及跨 domian 的问题,就先留给研究人员去探索了。
关于测试集也有类似的制作逻辑,只不过测试集我们花了更大的功夫,因为测试集对准确性要求更高。之前的训练集里面是把所有的 LFW 里面那些 5000 个名人全都排除了,这样我们测试集可以基于 LFW 来做,测试集的 query 全部来自于 LFW 里面的这些名人,然后我们基于这个名人列表爬了更多的名人日常照片,然后爬取的160 万的干扰项,然后互相之间除重之后最终变成一个大的 TestSet。
可以看到,我们新做的评测集检测图片的类别差异非常丰富,比如戴眼镜、侧脸、很大的表情、化妆、年龄变化、光线影响、黑白、戴帽子等等,常见的变化都在会在里面。
评测标准如下图所示:



















