












如果只有一张图片,怎么创建出一个人逼真的数字化身?
在 2020 年计算机视觉与模式识别会议(CVPR)期间,伦敦帝国学院和 AI 面部分析初创公司 FaceSoft.io 的研究人员介绍了一种 “AvatarMe” 技术,该技术能够仅仅通过一张普通的图像或照片,就重建逼真的 3D 半身像。更厉害的是,不仅能从低分辨率目标生成真实的 4K x 6K 分辨率的 3D 人脸,而且还可进行细致的光线反射。

图|3D 人脸重建和实时渲染效果(来源:GitHub)
从视频会议、虚拟现实到影视游戏,渲染 3D 人脸都有着数不尽的应用场景,尽管可以在没有 AI 的情况下拟合出几何形状,但是需要更多的信息才能在任意场景中渲染人脸。
为了提取这些信息,研究人员使用一个有 168 盏 LED 灯和 9 个单反相机的采样装置,拍摄了 200 张人脸的毛孔级反射图,然后他们用这些数据训练了一个人工智能模型 GANFIT,它可以从纹理合成逼真的人脸图,同时优化渲染和输出之间的“身份匹配”。
与其他生成性对抗网络(GANs)类似,GANFIT 是一个由两部分组成的模型:一个生成样本的生成器和一个试图区分生成样本和真实样本的鉴别器。生成器和鉴别器各自的能力互补,直到鉴别器无法将真实的例子与合成的例子区分开来。
此外,AvatarMe 的另一个组件则负责增强纹理的分辨率,还有一个单独的模块从被照明的纹理中预测皮肤结构(如毛孔、皱纹或头发)中每个像素的反射率,甚至估计表面细节(如细皱纹、疤痕和皮肤毛孔)。
研究人员说,在实验中,AvatarMe 在最终的渲染中没有产生任何伪影,并成功地处理了像太阳镜这样的 “极端” 案例和遮挡,反射率是一致的,即使在不同的环境中,系统都 “真实地” 照亮了被摄体。

图|不同场景下可以自适应的人脸光线反射(来源:GitHub)
三维人脸和几何纹理的重建是当前计算机视觉、图形和机器学习交叉领域中最受欢迎的方向,这项研究的关键工作之一,是对三维可变形模型(3DMM)拟合法的改进。
在优化渲染和输入之间的身份匹配的同时,将 3DMM 拟合到 “野生” 输入图像,并合成完整的 UV 纹理。
纹理被上采样 8 次,以合成合理的高频细节。然后,研究人员使用图像转换网络对纹理进行照明,并获得具有高频细节的漫反射反照率,使用单独的网络从漫反射反照率和 3DMM 形状法线推断出镜面反射率、漫反射法线和镜面法线。此外,网络是在 512x512 补丁上训练的,推断过程则是在 1536x1536 补丁上进行。最后,将面部形状和一贯推断出的反射率传递给头部模型,呈现出在任何环境中实时渲染的效果。
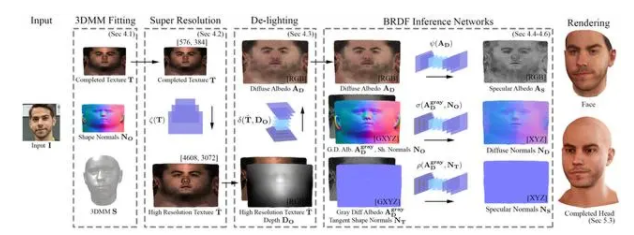
图|AvatarMe 的基本方法框架(来源:GitHub)
如何增强细节?核心是基于补丁的图像到图像转换。照明任务、去光以及从给定的输入图像(UV)中推断漫反射和镜面反射分量的任务可以表述为域适应问题,研究人员选择的模型是 pix2pixHD,它在高分辨率数据的图像到图像转换中显示了令人印象深刻的结果。
为了实现皮肤的真实感绘制,研究人员分别对所需几何体的漫反射、镜面反射反照率以及法线进行建模。因此,在给定一幅无约束的人脸图像作为输入的情况下,他们就能推断出人脸的几何参数以及漫反射反照率(AD)、漫反射法线(ND)、镜面反射反照率(as)和镜面反射法线(NS)。
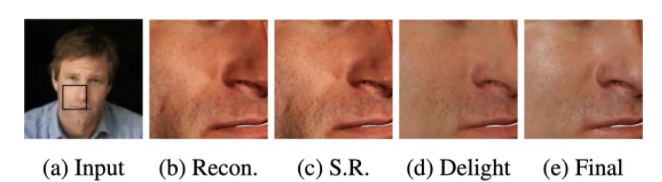
图|a、图像输入;b、基础重建;c、超分辨率;d、去光;e、最终渲染(来源:GitHub)
这个细节优化过程还是存在一定小坎坷的。例如,为了训练算法模型,研究人员捕获的数据具有非常高的分辨率(超过 4K),因此不能用于使用 pix2pixHD 进行 “原样” 训练,因为硬件限制(即使是在 32GB 的 GPU 上,也无法以原始格式拟合此类高分辨率数据)。此外,pix2pixHD 只考虑纹理信息,不能利用形状法线和深度形式的几何细节来提高生成的漫反射和镜面反射组件的质量。
所以,为了克服上述问题,研发人员将原始高分辨率数据分割成 512×512 像素的小块进行训练,在推断过程中,由于网络是完全卷积的,则补丁可以更大(例如 1536×1536 像素)。
AvatarMe 并非没有局限性,这个局限性就是现在美国科技公司都在极力呼吁的 “种族歧视” 问题。
论文中提到,由于训练数据集没有包含来自某些种族的主题示例,因此在尝试重建肤色较深的面孔时会导致效果不佳,且由于所需数据与 3DMM 模型的微小对准误差,重建的镜面反照率和法线有时会显示出一些高频孔隙细节的轻微模糊。最后,面部重建的精度跟输入的照片质量息息相关,一张光线充足、分辨率较高的照片会产生更精确的结果。
研究人员表示,在业内,这是用任何肖像图像(包括黑白照片和手绘图)实现 “可渲染” 人脸的第一种方法,作为一种最新的 3D 人脸生成和实时渲染 AI 系统,AvatarMe 有望使以前需要人工设计的过程逐步自动化。



























