深度强化学习是近年来热起来的一项技术。深度强化学习的控制与决策流程必须包含状态,动作,奖励是三要素。在建模过程中,智能体根据环境的当前状态信息输出动作作用于环境,然后接收到下一时刻状态信息和奖励。以众所周知的AlphaGo为例,盘面就是当前的状态,动作就是下一步往哪里落子,奖励就是最终的输赢。整个强化学习过程就是不断与环境交互,在交互的过程中产生数据,并利用这些交互产生的数据来学习的过程。正是在深度强化学习的帮助下,AlphaGo得以横扫世界级顶尖棋手。所以相比于有监督学习方法,深度强化学习在特定场景下可以达到超越人类的水准。
在围棋领域大放异彩之后,深度强化学习也在不断地拓展着自己的疆域,游戏、金融等越来越多的领域也出现了深度强化学习的身影。现代城市作为人类生产、生活的核心区域,是一个汇聚了交通、物流、能源等多个产业的复杂综合体。如果能够优化这种复杂结构,那么将会带来巨大的社会价值。而强化学习恰好可以做到这件事情。本文将为大家介绍几个强化学习在智能城市领域的应用案例。
一、智能交通
在城市各种各样的交通场景中,会遇到各种各样的资源配置和交通调度难题。如图3(a)所示,在一个典型的救护车辆调度场景中,救护车需要不断地往返于患者和救护车站点。救护车的接车时间在很大程度上取决于移动救护车的动态重新部署策略。也就是说,在救护车可用之后,应该把它调到哪个车站。重新调配现有救护车会影响未来接载病人的时间。例如在图3(b)中,未来将有3名患者来到1号站附近,因此将现有的救护车1号重新部署到1号站,通过从1号站派遣救护车,可以使这些患者迅速被接走。
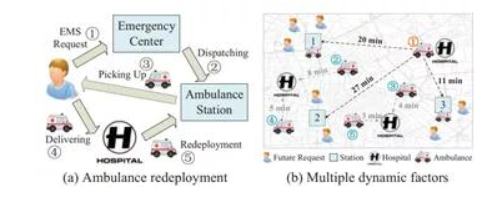
图1 救护车调度场景
这一问题依然可以利用强化学习的方法来求解。文章[1]将需要调度的救护车都被作为智能体,建模的核心就是确定相应的状态、动作以及奖励。在这一场景中,影响救护车效率的因素主要包括未来车站附近的病人数量、车站救护车的数量以及救护车与车站的距离等。将这些指标进行一定的转化,就可以提炼出病患密度、旅程时间等多个相关因子。这些相关因子就可以被作为输入状态。在这一场景中,决策变量,也就是救护车在完成接送任务后,被部署到不同的站点,就是智能体的动作。而优化目标,也就是将接载病人的时间,就是智能体的奖励,时间越短,奖励越大。理想情况下,每一辆救护车智能体都能够找到一种优势策略,让平均接送时间最短。接下来,文章引入深度强化学习算法,对这一场景进行很好地求解。
文章使用在真实世界中收集的数据集来评估动态救护车重新部署方法。实验结果表明,基于深度强化学习的救护车的重新部署方法明显优于最先进的基准方法。具体来说,与基准方法相比,基于深度强化学习的方法可以将10分钟内接诊的患者比例从0.786提高到0.838,节省平均接诊时间约20%(约100秒)。为了能够增加及时拯救病人的可能性,每一秒都是至关重要的。
在交通场景中,还有很多与之相似地调度问题,例如共享单车调度、公交车辆路线规划、出租车/网约车调度等。在这些场景中,都可以使用与之相类似的方法。此外,随着物联网技术的发展,未来各行各业的管理将进一步扁平化。一大批新的场景也会涌现出来。例如,交通信号灯的控制优化、自动驾驶的控制于决策,无人车辆的调度都属于深度强化学习的应用场景。所以,强化学习技术在未来将会在未来的智能交通中起到重要作用。
二、智能物流
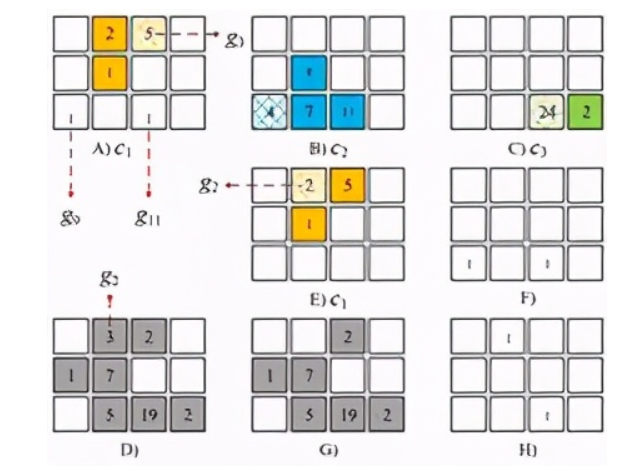
物流的发展极大地方便了人们,促进了电子商务的发展。但庞大的运单量却带来了很多管理问题,行业派单效率和配送效率普遍低下,导致了大量劳动力浪费。在快递领域,配送员的任务量不均衡现象是普遍存在的。这导致部分快递员任务量过饱和或不足。如果能够根据任务的不同,动态规划出每一个快递员的任务进行规划,那么就可以减弱这种资源不均衡现象,来提高资源利用率和任务完成率。但在现实中,快递员需要同时肩负配送和取件两项职能,还要兼顾整体地配送效率更高,这无疑会增加问题的复杂度。文章[2]利用深度强化学习来解决这一问题。在文章中,作者将整个空间粗略地划分成若干小区域,由图4中的小方格来表示。其中A、B、C分别表示三个快递员c1、c2、c3在每一个小区域的剩余配送量,其中阴影的小区域表示快递员当前的位置。D和G表示每一个小区域待取件的数量。F和H分别表示以快递员c1、c2为视角,其他快递员的位置。E表示快递员c1由位置g3到达位置g2。在真实场景中,影响快递员路线规划的因素,包括剩余的配送位置、待取件的位置、队友的位置、队友的行进路线等,基本都可以被这一图结构表达出来。所以这一图结构就作为智能体的状态。而智能体的动作则是快递员的前进方向,如向左还是向右,奖励就是为快递员完成的任务量。完成的任务越多,奖励越大。同样,在确定了这三维核心指标后,就可以引入深度强化学习算法来求解。
我们可以推断出,除了快递员的路径选择,车辆的运输、调度,也属于相似的场景,也可以使用相似的方法来解决。甚至大型物流仓储管理,也可以利用强化学习来建模。
三、智能能源
锅炉燃烧优化是一个典型的智能控制场景。电站锅炉系统高度复杂,包含磨煤、燃烧、水汽循环等多个环节,一个普通600MW中型火电机组就拥有上万个传感器测点,内部涉及燃烧、风烟、水热循环等众多物理化学过程非常复杂。纯粹使用机理建模的方法很难对如此复杂的系统做精准化建模,导致系统描述失准,影响优化效果。
从控制优化角度来讲,火电燃烧优化涉及上百个主要控制量(例如机组内部各种锅炉给煤量、各种风门、阀门开度等),而且这些变量均为连续变量(例如某个阀门开度20%和开度25%可能对机组运行带来非常不同的影响)。与此同时,当前动作所造成的影响往往不能够实时反馈,所以还需要考虑到长期的影响。对于如此复杂的场景,即便是有多年丰富经验的运行人员,也很少能够总结出一套高效的调节策略。所以此类复杂系统高维连续变量控制优化问题是世界性的难题。
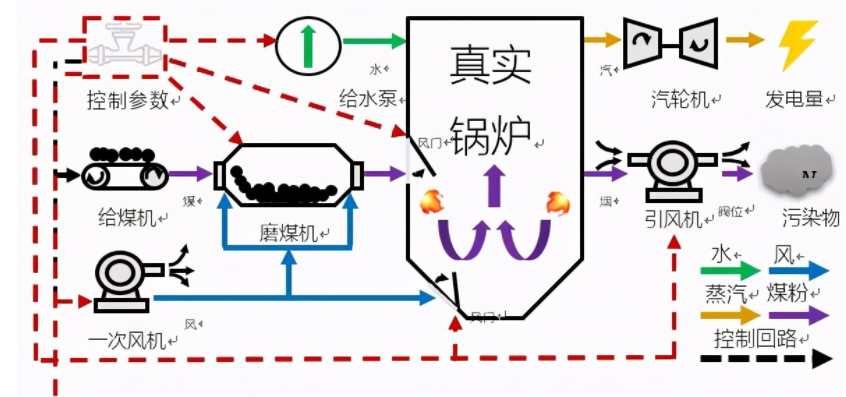
图3 火电锅炉运行流程
而深度强化学习恰恰适合来做这件事情。图2展示了我们基于强化学习的建模流程。对于一个典型的锅炉环境,我们可以得到很多的传感器提供系统的状态描述,例如锅炉中各种温度、风量、水量、压力等监测值。我们可以把这些实时反馈的监测值作为状态,也就是智能体能够“看到”的东西。然后我们将给煤量、各种风门、阀门开度等控制变量作为动作。在确定了状态和动作,我们利用一个业务指标(燃烧效率)作为奖励。智能体依据当前的状态输出动作,对锅炉控制参数进行调节,锅炉环境就会产生一个变化,到达一个新的状态,如果燃烧效率朝着好的方向变化,我们就给一个正向的奖励,如果是不好的变化,我们可以给一个负向的奖励。在完成了建模工作后,我们接下来通过合理的学习算法,就可以学习出更好的策略。学习算法通过观察很多的从状态和动作到下一个状态的变化过程,从中抽象状态——动作——奖励的对应模式,最终找到一个最佳的控制策略,可以从当前的状态映射到最佳的控制(动作)变量,实现长期平均奖励的最大化。
在上机实测过程中,基于强化学习的控制策略相比于人类操作达到了0.5%的效率提升,对于一台600MW机组,相当于年经济效益240万元。与此同时,我们已经实现了对于AI模型的产品化,具备了批量复制的能力,并在多个电厂落地并完成了验收。
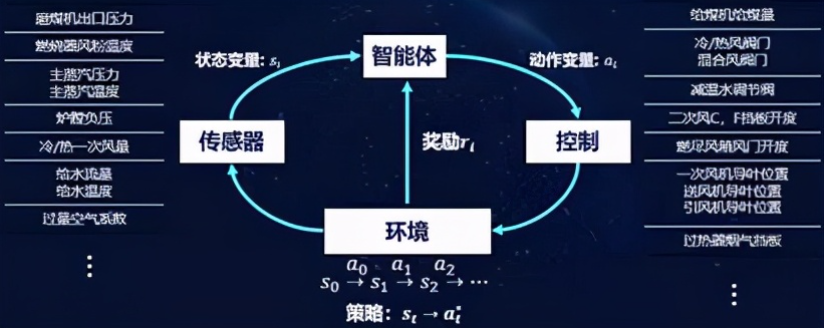
图4 基于强化学习的燃烧优化智能体
除了燃烧优化场景之外,在火电中,我们也已经将强化学习方法用在了磨煤机控制优化、冷端优化等场景中,并取得了很好的效果。上文所述的控制场景,强化学习也可以在温度控制、电网调度、能源管理等领域得到应用。另外,火电锅炉的控制属于典型的过程控制。在工业生产中,水泥生产过程中的磨机控制,机场ACDM系统中的车辆与人员调度、停机位优化,以及钢铁制造、化工等工业场景也均属于相似的场景。在这些场景中,可以提炼出来大量的控制与优化问题,深度强化学习技术也具有着广阔的空间。
通过案例我们可以看到,对于一个现实中的场景,如果能够确定影响的相关因素、优化动作以及优化目标,深度强化学习技术将可以隆重登场了。而这些场景在我们的生产生活中是大量存在的。所以在未来的智能城市与产业中,深度强化学习技术会起到重要的作用。但是就目前来说,深度强化学习的落地仍存在一些局限。这其中一部分原因是算法的学习效率仍不够高效,适应场景也较为狭窄,另外一部分原因是目前很多行业的数字化程度还比较低。但随着物联网时代的到来,这一问题将会被逐步解决。与此同时,随着大批研究人员的前仆后继,深度强化学习本身的技术也在不断地迭代发展,算法适用的范围也越来越广泛。未来的发展一定越来越好。
参考文献
[1] Shenggong Ji,et.al A Deep ReinforcementLearning-Enabled Dynamic Redeployment System for Mobile Ambulances. UbiComp2019
[2] Li Y, Zheng Y, Yang Q. Efficient and Effective Expressvia Contextual Cooperative Reinforcement Learning[C]//Proceedings of the 25thACM SIGKDD International Conference on Knowledge Discovery & Data Mining.2019: 510-519.