













【引子】 “海内存知己,天涯若比邻”, 这是石头兄弟推荐给我的一篇关于语义网的综述性文章,刊载于《美国计算机学会通讯》第64卷第2期——“A Review of the Semantic Web Field”(https://cacm.acm.org/magazines/2021/2/250085-a-review-of-the-semantic-web-field/fulltext),作者是Pascal Hitzler。老码农认真研读,颇有收获,编译成文。
“语义网”(Semantic Web)和“人工智能”一样,都指的是一个研究领域,而不是一个具体的产品。语义网是一个丰富的研究和应用领域,借鉴了计算机科学内部或邻近的许多学科。有时候,人们使用“语义网技术”这个术语被用来描述这一领域中出现的一系列方法和工具,以避免术语上的混淆。语义网领域不仅在研究和应用的方法和目标方面非常不同,而且有许多不同但又相互关联的次级社区,每个社区都可能对该领域的历史和当前状况作出相当不同的叙述。
那么,语义网是一个关于什么的研究领域呢?答案可能是主观的,因为在这个领域里没有明确的共识。
一种观点认为,该领域的长期目标是创建语义网产品 ,以及创建、维护和应用所需的所有必要工具和方法。相对于目前大多数主要面向人类消费的网络,这里的语义网通常被设想为机器可理解的信息以及利用这些信息的服务(智能代理)来增强当前的互联网。这种观点可以追溯到2001年《科学美国人》的一篇文章,可以说标志着这个领域的诞生。在这种情况下,提供机器可理解的信息是通过为数据赋予元数据来完成的。在语义网中,这些元数据通常采用本体论的形式,或者至少是一种具有基于逻辑语义的形式语言,允许对数据的意义进行推理。如果再加上智能代理将利用这些信息的理解,会发现语义网领域与人工智能领域有着显著的重叠。事实上,在过去大多数主要的人工智能会议上,都有明确的“语义网”的印记。
另一种更近期的观点是,语义网领域的开发方法及工具与互联网无关的应用,即使不使用机器可理解的数据建立智能代理,这些应用也能提供附加值。事实上,早期业界对这个领域的兴趣,旨在将语义网技术应用于信息集成和管理。从这个角度来看,可以说这个领域是关于建立高效的(即低成本的)数据共享、发现、集成和重用的方法和工具,而互联网在这方面可能只是数据传输的工具。这种理解使它更接近数据库,或者数据科学的数据管理部分。
通过将语义网描述为以 W3C 标准 RDF、 OWL 和 SPARQL 为核心来研究本体论、关联数据和知识图谱的基础和应用,可以对该领域进行限制,但实际上可能是相对精确的描述。
或许,这几个视角都有各自的优点,语义网的研究领域存在于它们的融合之中,本体论、关联数据、知识图谱是这个领域的关键概念,围绕 RDF、 OWL 和 SPARQL 的 W3C 标准构成了技术交流方式,它们在语法(在某种程度上是语义)层面上达成了统一; 语义网领域应用的目的是建立有效的数据共享、发现、集成和重用的方法(无论是否针对 Web) ; 作为驱动力的长期愿景是在的某个时刻,将语义网建立为一个完整的基于智能代理的应用环境。
“治学先治史”,让我们看看过去这些年语义网领域出现的关键概念、标准和突出成果。
语义网的发展阶段
当一个研究领域诞生时,确定任何特定的时间点当然是有争议的。然而,2001年 Berners-Lee 等人在《科学美国人》上发表的一篇文章是一个早期的里程碑,为这一新兴领域提供了重要的线索。而且,那是在世纪之初,当时语义网领域在社区规模、学术生产力和最初的产业兴趣等方面处于非常重要的上升初期。
但是,已经有人在早期做出了努力。从2000年运行到2006年的DAML项目,目标是开发一种语义 Web 语言和相应的工具。由欧盟资助的 On-To-Knowledge 项目,运行于2000-2002年,产生了 OIL 语言,后来与 DAML 合并,最终产生了网络本体语言的W3C标准。为网络数据赋予机器可读或“可理解”的元数据,这一更为普遍的想法可以追溯到互联网本身的起源。例如,早在1997年就发表了资源描述框架(RDF)的初稿。
从21世纪初开始,可以分为三个相互重叠的阶段,每个阶段都由一个关键概念驱动,也就是说,语义网领域的主要焦点至少转移了两次。第一阶段是由本体论驱动的,它跨越了21世纪初到21世纪中期; 第二阶段是由关联数据驱动的,一直延伸到21世纪10年代初。第三阶段到现在都是由知识图谱驱动的。
本体论
在21世纪的大部分时间里,这个领域的工作都以本体论为中心,当然,这个概念有着更为古老的渊源。本体是共享概念化的一个正式的、明确的规范ーー尽管有人可能认为这个定义仍然需要解释,但还是相当通用的。在一个更精确的意义上 ,本体论实际上是一个概念(即,类型或类别,如“哺乳动物”和“胎生动物”)及其关系(如“哺乳动物产下胎生动物”)的知识库,在一个基于形式逻辑的本体语言中指定。在语义网上下文中,本体是数据集成、共享和发现的主要工具,一个重要的思想是本体本身应该可以被其他人重用。
2004年,网络本体语言的OWL成为了W3C 标准,为该领域提供了进一步的燃料。OWL的核心是基于描述逻辑,也就是说,基于一阶谓词逻辑的子语言,只使用一元谓词和二元谓词,限制使用量词,设计的方式使得语言上的逻辑演绎推理是可判定的。
同样在2004年,资源描述框架(RDF)也成为了W3C标准。本质上,RDF是一种用于表达标记化并类型化的有向图的语法,它使用OWL指定类型及其关系的本体,然后在RDF图中使用这些类型,并将这些关系作为边。从这个角度来看,OWL本体可以作为RDF图的模式(或类型逻辑)。
一个用于RDF查询语言的 W3C 标准,称为 SPARQL,在2008年发布,在2013年进行了更新,3与 OWL 更加兼容。在RDF、 OWL和SPARQL周边的其他标准已经或正在开发,其中一些已经获得了重大的进展,例如,语义传感器网络本体论或起源本体论,以及SKOS 简单知识组织系统。
通过在W3C的所有这些关键标准,与其他关键 W3C 标准之间的基本兼容性得到了维护。例如,XML 作为RDF和OWL的语法序列化和交换格式。所有 W3C 语义 Web 标准还使用 IRI 作为 RDF图中的标识符,并使用了OWL类名和数据类型标识符等。
在语义网上下文中,本体是数据集成、共享和发现的主要工具,一个重要的思想是本体本身应该可以被其他人重用。
DARPA的 DAML 项目在2006年结束,随后在基础语义网研究方面几乎没有大规模的资助项目。因此,大部分相应的研究要么转移到应用领域,比如医疗保健或国防领域的数据管理,要么转移到相邻的领域。相比之下,欧盟的框架方案,特别是 FP6(2002-2006)和 FP7(2007-2013) ,为基础和面向应用的语义网研究提供了大量资金。在语义网研究社区的组成中,可以看到这个社区主要是欧洲人。社区的规模难以评估,但自2000年代中期以来,该领域的主要会议——“国际语义网会议”平均每年吸引了600多名参与者。
工业界的兴趣从一开始就很大,但几乎不可能描述关于工业活动相关水平的可靠数据。主要和较小的公司已经参与了大规模的基础或应用研究项目,特别是根据欧盟 FP 6和7。工业界的兴趣已经改变了研究团体的焦点。
一些大规模的本体论(通常早于语义 Web 社区)在这个时期成熟了。例如,于1998年开始的基因本体论,现在已经是一个非常突出的资源。另一个例子是 SNOMED CT,它可以追溯到1960年,但现在已经在OWL中完全正式化,并广泛用于电子健康记录。
正如计算机科学研究中经常出现的情况一样,在2005年前后,人们最初对短期取得突破性结果的期望开始降低,开始更为冷静看待这一问题。大多数本体论是在这一时期开发的,其形式通常是基于临时建模的意义,作为开发本体论的方法,但尚未产生具体的结果,结果是难以维护和重用。这一点,再加上当时开发良好的本体论所需的大量前期成本,为研究团体转移注意力铺平了道路,这也许可以被理解为与21世纪初强烈的基于本体论的方法相对立。
关联数据
2006年见证了“关联数据”的诞生,如果重点是在免费许可下的开放、公开和可用性,则称为“关联开放数据”。关联数据很快成为语义网研究和应用程序的主要驱动力,并一直持续到2010年左右。
关联数据由一组RDF图组成,这些RDF图是关联的,因为图中的许多IRI标识符也出现在其他的图中,可以是多个图中。从某种意义上说,所有这些关联的RDF图集合可以理解为一个非常大的 RDF 图。
如下图所示,公开可用的关联RDF图的数量在第一个十年中在显著增长; 数据来自关联开放数据云网站,该网站并不包含所有RDF数据集。2015年的一篇论文报道了“来自超过65万个数据文档的超过370亿个三元组”,这也只是所有可以在互联网上自由访问的 RDF三元组的集合。例如,大型数据提供者通常只提供基于SPARQL的查询接口,或者使用RDF进行内部数据组织,但只通过Web 页面向外部提供服务。关联开放数据云中的数据集覆盖了各种各样的主题,包括地理、政府、生命科学、语言学、媒体、科学出版物和社交网络。
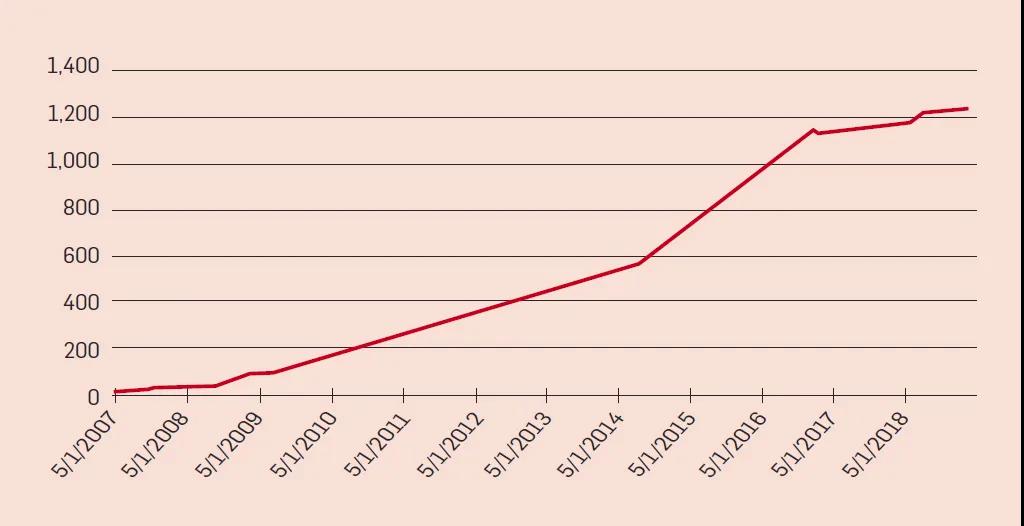
随着时间的推移,关联数据开放云中 RDF 图的数量
其中最著名和最常用的关联数据集是 DBpedia,这是从 Wikipedia (以及最近的 Wikidata)中提取的关联数据集。2016年4月发布的数据集包括了约600万个实体和约95亿个RDF三元组。由于其广泛的主题覆盖(基本上是维基百科中的所有内容) ,而且它是最早提供的链接数据集之一,DBpedia 在关联数据开放云中发挥着核心作用: 许多其他数据集都会链接到它,因此它已成为关联数据的枢纽。
从一开始,业界就对关联数据产生了浓厚的兴趣。例如,BBC是第一个重要的行业贡献者,纽约时报公司和Facebook是早期采用者。然而,业界的兴趣似乎主要在于利用关联数据技术进行数据集成和管理,而这些数据往往不会在开放的互联网上显示出来。
在关联数据的时代,本体论扮演了一个不那么重要的角色。它们通常被用作模式,可以告知RDF 数据集的内部结构,然而,相对于本体论时代的过度承诺和深度研究,关联数据云中的RDF图中的信息是肤浅和相对简单的。在这段时间里,人们有时会说本体论不能被重用,而且一种更简单的方法,主要基于利用 RDF 和数据集之间的链接,对于数据集成、管理和线上线下的应用程序有着更现实的作用。也正是在这个时期,基于RDF的数据组织词汇表与本体的关系并不大。
也正是在这段时间(2011年)里,schema.org 登场了。最初由Bing、 Google 和雅虎推动,后来yandex也加入进来,公开了一个相对简单的本体论体系,并建议网站提供商使用schema.org的词汇表在各自的网站上注释(即链接)实体。作为回报,schema.org背后的 Web 搜索引擎提供商承诺通过利用注释作为元数据来改善搜索结果。在2015年,大约有超过30% 的页面使用了schema.org的注释。
2012年发起的另一个重要项目是Wikidata,该项目最初是德国wikimedia协会的一个项目,由谷歌、 Yandex 和Allen人工智能研究所等机构资助。Wikidata 基于与维基百科类似的想法,即众包信息。然而,维基百科提供了百科全书式的文本(以人类读者为主要消费者) ,Wikidata 则是关于创建可用于程序或其他项目的结构化数据。例如,许多其他wikimedia包括维基百科,使用Wikidata提供一些信息,然后呈现给人类读者。Wikidata已经拥有了超过6600万个的数据项,自项目启动以来已经进行了超过10亿次的编辑,并且有超过20000个活跃用户。
在21世纪10年代早期,关联数据的最初炒作开始让位于一种更为冷静的观点。虽然关联数据确实有一些突出的用途和应用,但结果表明,集成和利用关联数据需要比最初的预期付出更多的努力。可以说,用于关联数据的浅显的非表达性模式似乎是可重用性的一个主要障碍,最初期望数据集之间的相互联系会以某种方式解释这一弱点,但似乎并没有实现。这不应被理解为贬低了链接数据给该领域及其应用带来的重大进展: 仅仅以某种结构化的格式提供数据,遵循一个突出的标准,就意味着可以使用现有工具访问、集成和管理数据,然后进行利用。这比以语法和概念上更加异构的形式提供数据要容易得多。但是,寻求更有效的数据共享、发现、集成和重用的方法当然和以往一样重要,而且正在开始。
知识图谱
2012年,当谷歌推出它的知识图谱时,一个新的术语出现了。例如,可以通过在 google 网站上搜索知名实体来查看 Google知识图谱的部分内容: 在链接到网页的搜索结果旁边显示一个所谓的信息框,显示来自Google知识图谱的信息。下图给出了这种信息框的一个例子,搜索 Kofi Annan 就可以找到这个例子。人们可以通过跟随一个超链接从这个节点导航到图谱中的其他节点,例如,到 Nane Maria Annan,她与 Kofi Annan 节点有配偶关系。在这个链接之后,Nane Maria Annan 的一个新的信息框被显示在同一个词的搜索结果旁边。
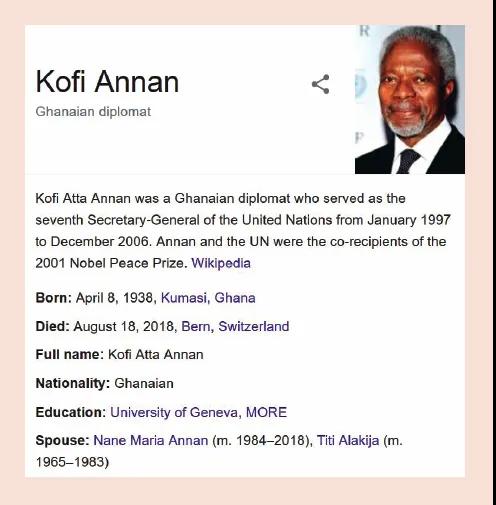
在 google 上搜索“ Kofi Annan”后的 Google知识图谱节点
虽然 Google 没有提供可下载的知识图谱,但它提供了内容访问的API,这个API 使用标准的schema.org类型,并且满足JSON-LD格式,这实际上是W3C RDF 标准化的另一种语法。
然而,考虑到语义网技术的历史,特别是之前讨论过的关联数据和本体论,知识图谱仿佛是一种直接来自语义网领域的新构想,关注的重点发生了显著转变。
其中一个不同之处在于开放性: 正如关联开放数据这个术语从一开始就暗示的那样,语义网社区的关联数据工作大多以开放共享数据为其目标之一,这意味着关联数据大多可以免费下载,或者由支持SPARQL的服务提供,并且重要的是在社区中使用非限制性许可。wikidata作为一个知识图谱也是开放共享的。相比之下,围绕知识图谱的活动往往是由行业主导的,而主要的应用并不是真正开放的。
另一个区别是集中控制与自下而上的社区贡献: 在某种意义上,关联数据云是目前已知最大的现有知识图谱,但它不是一个简洁的实体。相反,它由松散且相互关联的单个子图组成,每个子图都由它自己的结构、表示模式等控制。相比之下,知识图谱通常被理解为更具内部一致性和更严格控制的组件服务。因此,对于没有严格质量控制的外部图表的价值受到质疑,而内容和/或基础模式的质量受到更多关注。
最大的区别可能是从学术研究到工业应用的转变。因此,围绕知识图谱的活动是由强大的工业用例及可感知的附加价值推动的,没有公开的正式评估。
语义网与其他领域和学科的关系
与机器学习那样的其他领域不同,语义网领域主要不是由该领域固有的某些方法驱动的。相反,它是由一个共同的愿景驱动的,因此,它根据需要借鉴了其他学科。
例如,语义网领域作为人工智能的一个子学科,与知识的表示有着密切的关系,因为知识图谱和本体论来表示语言可以被理解,而且与知识表示的语言密切相关,描述逻辑作为支撑网络本体语言 OWL的逻辑学,发挥着核心作用。语义网的应用需求也推动或启发了描述逻辑的研究,以及对不同知识表示方法(如规则和描述逻辑)之间桥接的研究。
数据库领域显然是密切相关的,如(元)数据管理和图的结构化数据有一个自然的家园,也是重要的语义网领域。然而,语义网研究的重点主要集中在异构数据源的概念集成上;,例如,如何克服不同的数据组织方式; 在大数据术语中,语义网的重点主要是数据的多样性。
自然语言处理作为一种应用工具,在知识图谱和本体集成、自然语言查询应答、文本知识图谱或本体构造等方面发挥着重要作用。
机器学习,特别是深度学习,正在改进语义网上下文中困难任务的处理能力,例如知识图谱补全,数据清洗等等。与此同时,语义网技术正在研究提高人工智能的可解释性。
在网络物理系统和物联网的某些方面也正在研究使用语义网技术,例如,在智能制造(工业4.0)、智能能源网和智能建筑等等。
生命科学的一些领域受益于语义网技术已经有相当长的历史了,例如,前面提到的 SNOMED-CT 和基因本体论。一般来说,生物医学领域是语义网概念的早期采用者。另一个突出的例子是由语义网技术驱动的ICD开发。
语义网技术其他潜在的应用领域可以是任何需要数据共享、发现、集成和重用的场景,例如在地球科学或数字人文学科。
语义网的未来
毫无疑问,语义网领域的宏伟目标尚未实现,无论是将语义网作为一个产品来创建,还是为数据共享、发现、集成和重用提供解决方案,使其变得完全容易和轻松。正如关于知识图谱、schema.org和生命科学本体论的讨论所证明的那样,这并不意味着中间结果没有实际用途。
然而,为了向更大的目标前进,几乎每一个子领域的语义网都需要进一步的发展。例如,工业知识图谱,本体匹配,信息抽取等等。与其重复些清单,不如让把重点放在当前的短期主要障碍的挑战上。
在语义网社区及其应用社区中,关于如何有效的处理数据管理问题有着丰富的软硬知识。然而,刚刚采用语义网技术的人们经常发现自己面临着一种不和谐的声音,面对不同方法的推销,但几乎没有关于这些不同方法的利弊介绍。还有那些工具包,从不适合实践的粗糙原型到针对特定子问题而精心设计的软件,但同样没有什么指导,到底哪种工具,哪种方法,将最有助于用户实现自己的特定目标。
因此,在这个阶段,语义网领域最需要的可能是整合。作为一个固有的应用驱动领域,这种合并会在其各个子领域进行,从而形成面向应用的流程,这些流程的目标和优缺点都有详细的文档记录,同时还有易于使用和支持整个流程的集成工具。一些著名的流行软件,如OWL API,Wikidata的底层引擎Wikibase,或者ELK推理机,都是强大且非常有帮助的,但是在某些情况下,尽管它们都使用了 RDF 和 OWL 进行序列化,仍然不能轻松地相互协作。
谁可能是这种整合的驱动力呢?
对于学术界而言,开发并维护稳定易用软件的动机往往有限,因为学术成绩(主要以出版物和获得的外部资金总额衡量)往往与这些活动不相符。编写高质量的入门教科书是非常耗时且回报很少的学术成绩。然而,通过开发各种范式之间的桥梁解决方案,以及通过与应用领域合作开发和实现用例,学术界确实为整合提供了一个基础。
在工业界,各种各样的整合已经发生,初创企业和跨国公司采用语义网技术就是明证。但是,不论是技术细节还是其内部采用的软件,通常是不共享的,大概都是为了保护自己的竞争优势。如果确实如此,那么相应的软件解决方案变得普及将只是时间的问题。
小结
在语义网存在的第一个近20年里,语义网领域已经产生了丰富的关于数据共享、发现、集成和重用的高效数据管理的知识。通过语义网的应用,可以很好的理解这个领域的主要贡献,包括 Schema.org,工业知识图谱,Wikidata,本体建模应用等。这些应用背后的关键科学发现是什么呢?然而,这个问题更难回答。语义网的进步需要许多计算机科学子领域的贡献,而其中一个关键任务就是如何将这些贡献整合起来,以便提供适用的解决方案。从这个意义上说,这些应用展示了整个领域的主要进展。
主流工业界正在采用语义网技术,然而,寻求更有效的数据管理解决方案远远没有结束,仍然是该领域的驱动力。























