












我成为数据科学家是因为我最喜欢找到解决复杂问题的解决方案,工作的创造性部分以及从数据中获得的见解。诸如清理数据,预处理和调整超参数之类的无聊的事情并没有给我带来什么乐趣,这就是为什么我尝试尽可能自动执行这些任务的原因。
如果您还喜欢将无聊的东西自动化,那么您会喜欢本文中将要介绍的库。
如今,没有人使用Scikit-Learn的线性回归来预测Kaggle竞争中的房价,因为XGboost方法更准确。
但是,XGboost超参数很难调整。它们很多,而机器学习工程师在使用此算法时浪费了很多时间进行调整。好吧,不再了。
介绍Xgboost-AutoTune
我很高兴与您分享由MIT的Sylwia Oliwia开发的Python Xgboost AutoTune库,该库最近已成为我自动XGboost微调的首选。
让我们看一下此气候数据集的示例,我们可以根据温室气体浓度预测温度升高,并评估每种气体的影响。
首先,我们导入数据集并绘制CO2,CH4,N20和合成气的气体浓度:
通过运行,我们可以看到过去140年中所有温室气体的增加情况:
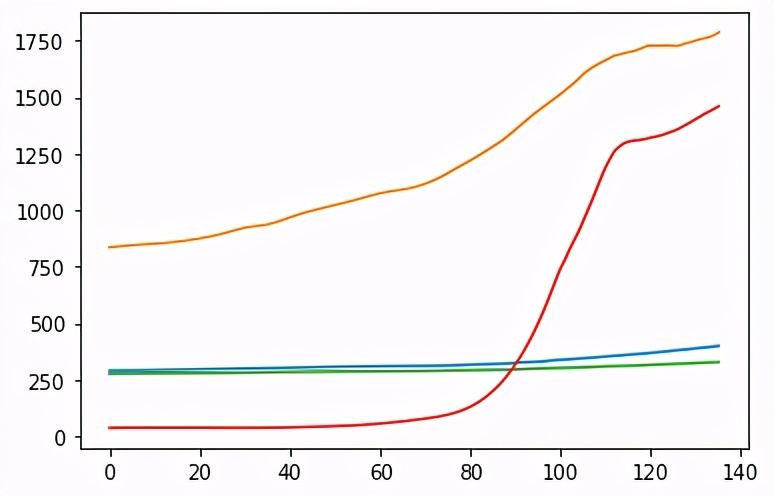
太酷了,现在我们可以导入我提到的Autotuning库,但是以防万一您没有下载存储库,我也会在此处显示代码:
基本上,您只需要记住该自动调整库的主要方法是“ fit_parameters”,只需调用它,它就为找到超参数的最佳值进行了所有艰苦的工作,如下所示:
请注意,我们选择了一种计分方法(在本例中为均方根对数误差RMSLE),并且初始模型为XGBRegressor,因为这是一个回归问题(另一个选项将是分类问题)。
太酷了,因此我们仅用两行代码构建了最佳的XGboost模型,现在让我们做出预测:
这将输出一个图形,其中包含预测温度与测试集中的实际值的对比:
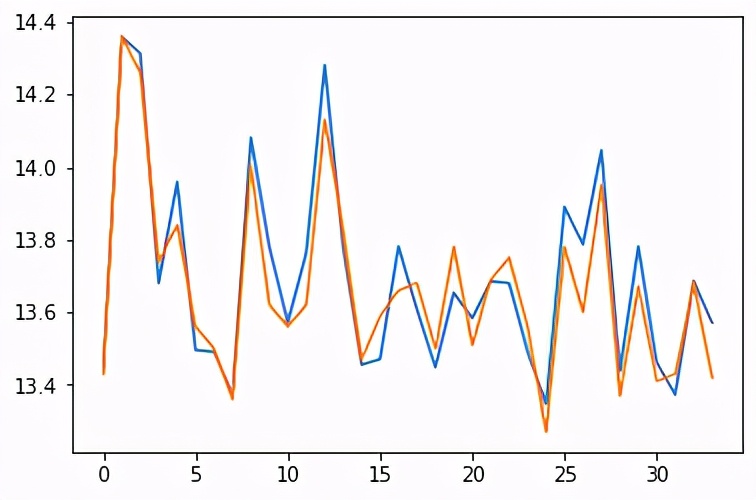
看起来不错。
现在,如果我们想知道在变暖作用中最重要的气体是什么,我们可以做:
这将返回以下内容:
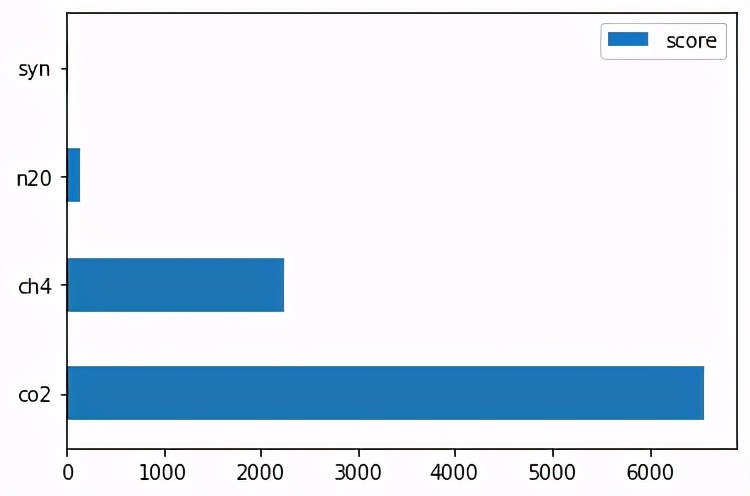
正如预期的那样,CO2是效果最强的气体,这不足为奇,但是我们可以看到CH4也具有非常重要的作用,最重要的是,这种模型训练起来非常快。
结论
梯度提升是其不涉及深度学习的回归和分类任务中最常用的算法,因为它具有很高的准确性,可解释性和速度。
遗憾的是,尽管Python生态系统提供了XGboost库,但是它没有像Scikit-Learn这样的其他库那么广泛,并且数据科学家必须手动完成调整参数,这会造成很多麻烦。
这就是为什么我认为这个自动调整库是一个需要共享的瑰宝。
我最后的反思是:数据科学家的聘用费用昂贵,而他们的时间最好花在进行非琐碎的工作上。
您能想象一位销售主管打了电话吗?当然那不是他们的工作。
好吧,可悲的是,许多数据科学家都是各行各业的佼佼者,他们的工作通常包括:查找数据,清理数据,摄取数据,决定使用的模型,编码模型,编码脚本以调整模型,部署模型,将模型展示给企业,上帝知道还有什么。
因此,数据科学家拥有的自动化工具越多,她就越能专注于最重要的工作:理解数据并从中获取价值
希望您喜欢这篇文章,它可以帮助您更快地训练模型。
祝您编码愉快!
原文链接:https://towardsdatascience.com/the-coolest-data-science-library-i-found-in-2021-956af253fb2c












