缓存的重要性
缓存对于每个Python程序员来说都是一个需要理解的重要概念。
简而言之,缓存的概念主要是利用编程技术将数据存储在临时位置,而不是每次都从源检索数据。
随后,缓存可以提高应用程序的性能,因为从临时位置访问数据比每次从源(如数据库、web服务等)获取数据更快。
本文旨在解释Python中的缓存是如何工作的。

为什么我们需要实现缓存?
要理解缓存是什么以及为什么需要缓存,请考虑下面的场景。
我们正在用Python构建一个应用程序,它将向最终用户显示产品列表。这个应用程序每天会被超过100个用户多次访问。应用程序将托管在应用程序服务器上,并且可以在internet上访问它。产品将存储在一个数据库中,该数据库将安装在数据库服务器上。因此,应用服务器将查询数据库以获取相关记录。
下图演示了我们的目标应用程序是如何设置的:
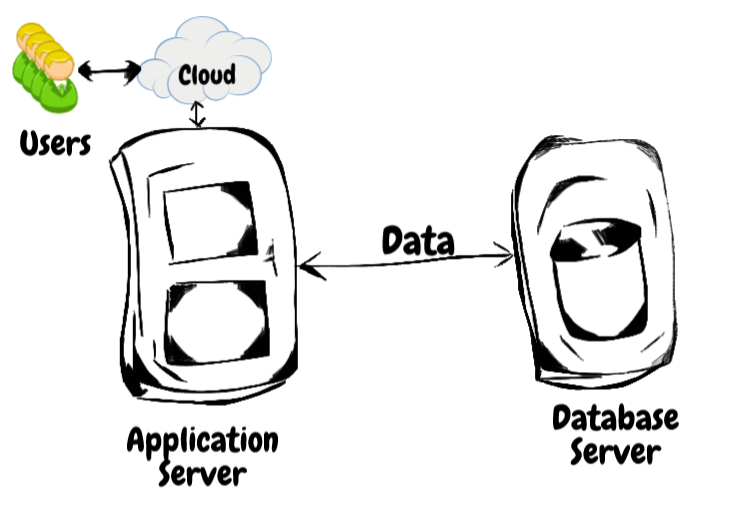
问题
从数据库获取数据是一个io绑定操作。因此,它的本性是缓慢的。如果频繁发送请求,而响应更新不频繁,那么我们可以将响应缓存到应用程序的内存中。
我们可以缓存结果,而不是每次都查询数据库,如下所示:
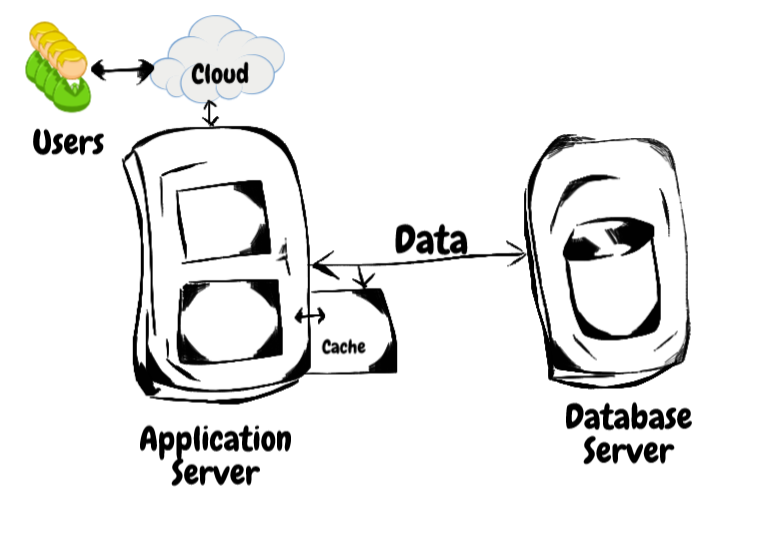
获取数据的请求必须通过线路,响应必须通过线路返回。
这在本质上是缓慢的。因此,引入了缓存。
我们可以缓存结果,以减少计算时间和节省计算机资源。
缓存是一个临时存储位置。它以惰性加载方式工作。
最初,缓存是空的。当应用程序服务器从数据库服务器获取数据时,它将用所需的数据集填充缓存。从那时起,后续的请求将从缓存获取数据,而不是一路到应用程序服务器。
我们还需要及时使缓存失效,以确保向最终用户显示最新的信息。
这就引出了本文的下一节:缓存规则。
缓存规则
在我看来,缓存有三条规则。
在启用缓存之前,我们需要执行分析应用程序的关键步骤。
因此,在应用程序中引入缓存之前的第一步是对应用程序进行概要分析。只有这样,我们才能了解每个函数需要多长时间以及它被调用了多少次。分析过程完成后,我们需要确定需要缓存的内容。
我们需要一种机制来连接函数的输入和输出,并将它们存储在内存中。这就引出了缓存的第一条规则。
(1) 缓存的第一条规则
第一个规则是确保目标函数需要很长时间才能返回输出,它经常被执行,并且函数的输出不会经常改变。
我们不希望为那些不需要很长时间就能完成的函数、在应用程序中很少被调用的函数或那些返回结果却在源代码中频繁更改的函数引入缓存。
这是一个需要记住的重要规则。
适合缓存的候选者:频繁调用的函数,输出不经常改变,执行需要很长时间
作为一个实例,如果一个函数执行了100次,并且函数需要很长时间才能返回结果,并且对于给定的输入它返回相同的结果,那么我们可以缓存结果。
然而,如果一个函数返回的值更新每一秒在源得到请求执行函数每分钟然后理解真的很重要我们需要缓存结果是否会最终将陈旧的数据发送给用户。这可以帮助我们理解我们是否需要缓存,或者我们是否需要不同的通信通道、数据结构或序列化机制来更快地检索数据,例如通过在套接字上使用二进制序列化器发送数据,而不是使用http上的xml序列化。
此外,知道什么时候使缓存失效,什么时候用新数据重新加载缓存也很重要。
(2) 第二个规则
第二条规则是确保从引入的缓存机制获取数据比执行目标函数更快。
只有当从缓存中检索结果的时间比从数据源检索数据的时间快时,我们才应该引入缓存。
缓存应该比从当前数据源获取数据快
因此,选择合适的数据结构(如字典或LRU缓存)作为实例是至关重要的。
(3) 第三个规则
第三条重要的规则是关于内存占用的,这一点经常被忽略。您是在执行IO操作(如查询数据库、web服务),还是在执行CPU密集型操作(如计算数字和执行内存计算)?
当我们缓存结果时,应用程序的内存占用将会增加,因此选择适当的数据结构并只缓存需要缓存的数据属性是至关重要的。
有时我们查询多个表来创建一个类的对象。但是,我们只需要在应用程序中缓存基本属性。
缓存影响内存占用
作为一个实例,考虑我们构建了一个报告指示板,它查询数据库并检索订单列表。为了便于说明,让我们考虑一下仪表板上只显示订单名。
因此,我们可以只缓存每个订单的名称,而不是缓存整个订单对象。通常,架构师建议创建一个具有__slots__属性的精益数据传输对象(DTO),以减少内存占用。也使用了命名元组或Python数据类。
这就引出了本文的最后一节,概述了如何实现缓存的细节。
如何实现缓存?
有多种实现缓存的方法。
我们可以在Python进程中创建本地数据结构来构建缓存,或者将缓存作为服务器,充当代理并为请求提供服务。
有一些内置的Python工具,比如使用functools库中的cached_property装饰器。我想通过提供缓存装饰器属性的概述来介绍缓存的实现。
下面的代码片段说明了缓存属性是如何工作的。
- from functools import cached_property
- class FinTech:
- @cached_property
- def run(self):
- return list(range(1,100))
结果,FinTech().run现在被缓存,range(1100)的输出将只生成一次。然而,在实际场景中,我们几乎不需要缓存属性。
让我们回顾一下其他方法。
1. 字典的方法
对于简单的用例,我们可以创建/使用映射数据结构,如字典,我们可以保存在内存中,并使其在全局框架上可访问。
有多种方法来实现它。最简单的方法是创建一个单例样式的模块,例如config.py
在配置。我们可以创建一个dictionary类型的字段,在开始时填充一次。从那时起,可以使用dictionary字段来获取结果。
2. 最近使用的算法
我们可以使用Python的内置特性LRU。
LRU代表最近最少使用的算法。LRU可以缓存函数的返回值,这些返回值依赖于传递给函数的参数。
LRU在递归CPU绑定操作中特别有用。
它本质上是一个装饰器:@lru_cache(maxsize, typed),我们可以用它来装饰函数。
maxsize告诉装饰器缓存的最大大小。如果我们不想设置大小,那么只需将其设置为None。
typed用于指示是否要将输出缓存为可以比较不同类型值的相同值。
当我们期望相同的输入产生相同的输出时,这是有效的。
将所有数据保存在应用程序的内存中可能会带来麻烦。
在具有多个进程的分布式应用程序中,这可能会成为一个问题,因为不适合将所有结果缓存到所有进程的内存中。
一个很好的用例是应用程序运行在一个机器集群上。我们可以将缓存作为一种服务托管。
3. 缓存即服务
第三种选择是将缓存数据作为外部服务托管。该服务可以负责存储所有请求和响应。
所有应用程序都可以通过缓存服务检索数据。它就像一个代理。
假设我们正在构建一个和Wikipedia一样大的应用程序,它将同时或并行地服务1000个请求。
我们需要一个缓存机制,并希望在服务器之间分布缓存。
我们可以使用memcache并缓存数据。
Memcached在Linux和Windows中非常流行,因为:
- 它可以用于实现具有状态的记忆缓存。
- 它甚至可以跨服务器分布。
- 它使用起来非常简单,速度很快,并且在多个大型组织中广泛使用。
- 它支持自动过期缓存的数据
我们需要安装一个叫做pymemcache的python库。
Memcache要求数据以字符串或二进制形式存储。因此,我们必须序列化缓存的对象,并在需要检索它们时反序列化它们。
代码片段展示了如何启动和使用memcache:
- client = Client(host, serialiser, deserialiser)
- client.set(‘blog’: {‘name’:’caching’, ‘publication’:’fintechexplained’}}
- blog = client.get(‘blog’)
原文链接:
https://medium.com/fintechexplained/advanced-python-how-to-implement-caching-in-python-application-9d0a4136b845