作者:TurboNLP,腾讯 TEG 后台工程师
导语
NLP 任务(序列标注、分类、句子关系判断、生成式)训练时,通常使用机器学习框架 Pytorch 或 Tensorflow,在其之上定义模型以及自定义模型的数据预处理,这种方式很难做到模型沉淀、复用和共享,而对于模型上线同样也面临:上线难、延迟高、成本高等问题,TEG-AI 平台部-搜索业务中心从 2019 年底开始,前期经过大量调研,在 AllenNLP 基础上自研了推理及训练一体化工具 TurboNLP, 涵盖了训练框架 TurboNLP-exp 和推理框架 TuboNLP-inference,TurboNLP-exp 训练框架具备可配置、简单、多框架、多任务、可复用等特点,在其之上能够快速、高效的进行 NLP 实验.
TurboNLP-inference 推理框架底层支持高效的模型推理库 BertInference,集成了常用的 NLP 模型, 具备无缝兼容 TurboNLP-exp、推理性能高(在 BERT-base 文档分类业务模型上实测,FP6 精度在 batch_size=64、seq_len=64 的情况下达到了 0.275ms/query,INT8 精度在 batch_size=64、seq_len=64 的情况下达到了 0.126ms/query 性能)等特点,NLP 训练和推理一体化工具极大的简化了训练到推理的流程,降低了任务训练、模型上线等人力成本,本文将主要介绍 NLP 训练和推理一体化工具。
背景
- NLP 任务通常是算法研究者自定义模型和数据预处理在机器学习框架Pytorch或Tensorflow进行训练,并手动部署到 libtorch 或 tensorflow 上,这一过程存在如下问题:
- NLP 任务已有的模型结构和数据预处理重新定义,重复性高。
- 手动修改模型结构和数据预处理代码,不断调整训练参数,反复试验,造成代码混乱。
- 模型复杂度(多模型多任务)高或需要对现有模型进行优化改进时,如不熟悉模型结构,就需要重头梳理 Python 定义的模型和数据预处理代码。
- 知识沉淀、模型复用及共享困难。
- 上线难、数据预处理 C++化复杂、推理延迟高。
- 流程化提升 NLP 任务的离线训练及效果实验效率困难,试错成本高。
为了解决以上存在的痛点,在此背景下,我们打通了 NLP 训练端到推理端、自研了训练框架TurboNLP-exp及推理框架TuboNLP-inference,以下是框架的整体架构图:
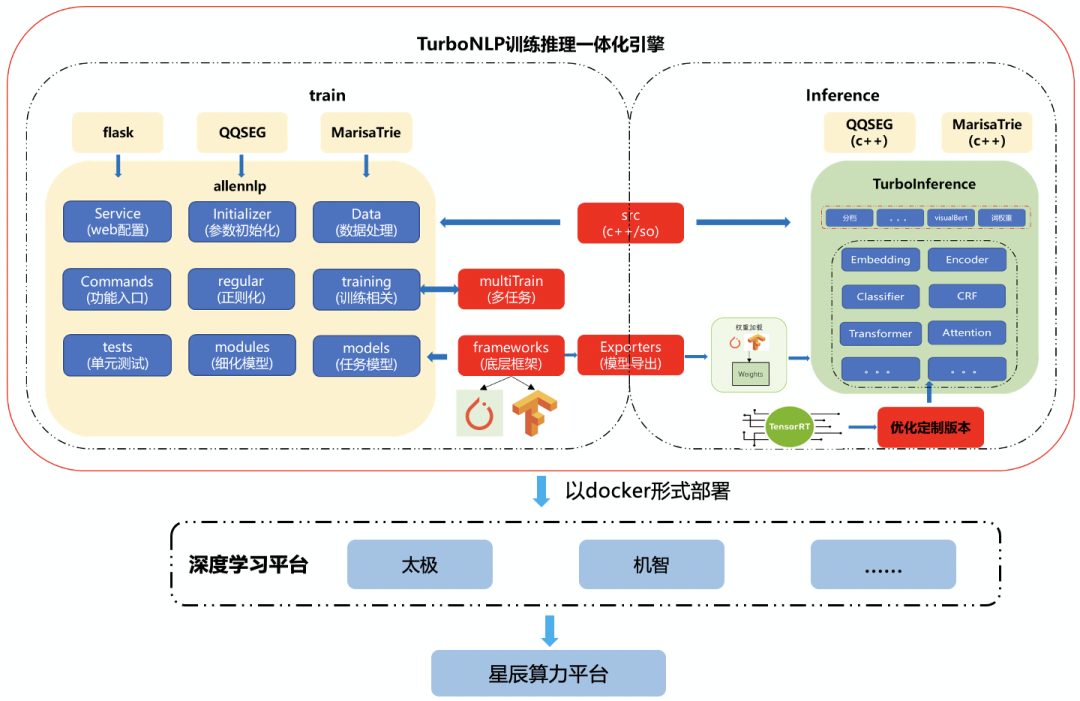
简介
- 训练框架 TurboNLP-exp
- TurboNLP-exp 具备模块化、可配置、多平台支持、多任务支持、多模型格式导出、C++数据预处理等特点、既能满足研究者快速实验、也能将模型通过配置沉淀到框架上,后续研究者通过配置来复用和共享知识。
- TuboNLP-exp 对模型和数据预处理进行了模块化设计,对于数据预处理,针对同一类 NLP 任务(序列标注、分类、句子关系判断、生成式)数据预处理基本一样,通过复用配置即可复用已有的数据预处理;对于模型,TurboNLP-exp 集成了丰富的子模块:embedder、seq2seq_encoder、seq2vec_encoder、decoder、attention 等,通过配置随意的构建模型,达到快速实验目的。
- TuboNLP-exp 对底层机器学习平台(Pytorch 和 Tensorflow)进行了统一的封装,熟悉不同的机器学习平台丝毫不影响模型的复用、共享和知识沉淀。
- TurboNLP-exp 支持 C++和 Python 数据预处理,Python 数据预处理具备快速实验调试的特点主要服务于训练端,C++数据预处理具备性能高的特点主要服务于推理端,C++数据预处理和 Python 具有相同 API 接口,研究者在训练阶段能够随意切换 C++和 Python 数据预处理,保证训练端和推理端的数据一致性。
- 推理框架 TurboNLP-inference
- TurboNLP-inference 能够直接加载 TuboNLP-exp 导出的模型,根据配置来实例化数据预处理。
- TurboNLP-inference 提供统一的 API、完善的文档和 examples,通过 examples 快速实现模型推理代码,业务代码通过 API 接口和 so 包调用推理库。
- TurboNLP-inference 推理框架集成了 NLP 常用的模型:lstm、encoder-decoder、crf、esim、BERT,底层支持五种推理库:BertInference(BERT 推理加速库)、libtorch、tensorflow、TurboTransformers(WXG 开源的 BERT 推理加速库)、BertInference-cpu(BERT 在 CPU 上推理加速库)。
TurboNLP-exp 训练框架
TurboNLP-exp 训练框架是基于 AllenNLP 研发,为了满足算法研究者和推理的业务需求,TurboNLP-exp 不断优化,具备了业界框架不具备的特性,下表是 TurboNLP-exp 于业界其他框架的对比:
| 框架 | 难度 | 模块化 | 可配置 | Pytorch | Tensorflow | 多任务训练 | 多模型格式导出 | 数据预处理 | 推理 |
|---|---|---|---|---|---|---|---|---|---|
| PyText | 难 | T | T | T | F | F | F | Python | Caffe2 执行引擎 |
| AllenNLP | 简单 | T | T | T | F | F | F | Python | 简单的 Python 服务 |
| TurboNLP-exp | 简单 | T | T | T | T | T | T | Python、C++ | 高效的 TurboNLP-inference |
以下会详细介绍我们对 TurboNLP-exp 上所做的优化。
模块化及可配置
TurboNLP-exp 的可配置程度高,源于其合理的模块设计,通过模块化封装,TurboNLP-exp 支持随意组合模型、扩展子模块等,对于刚接触的研究者 TurboNLP-exp 提供了界面化配置,通过可视化界面生成数据预处理和模型配置,大大降低了上手难度。
数据预处理模块化及可配置
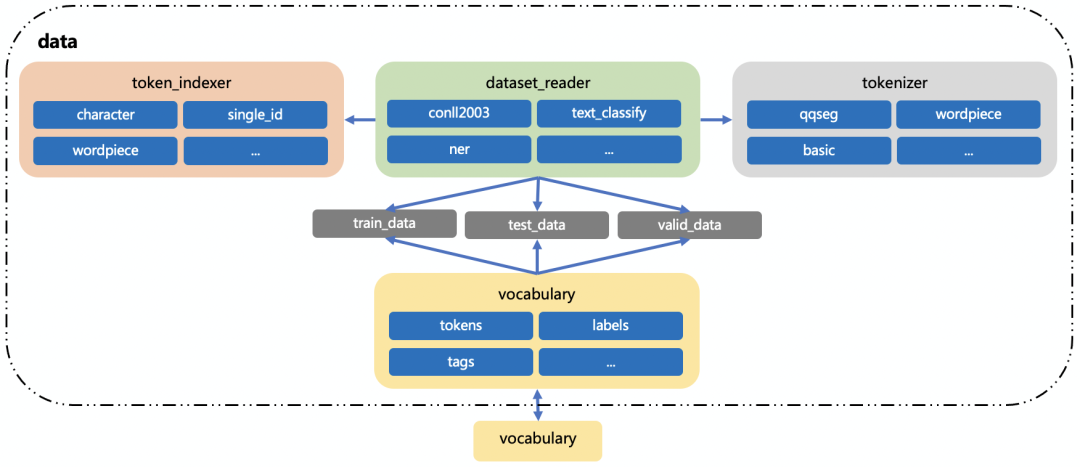
数据预处理粗略可分为dataset_reader、token_indexer、tokenizer、vocabulary四个模块。
- dataset_reader:负责读取训练数据,使用分词器进行分词、索引器来进行 id 转化;集成了多种数据格式读取:文本分类数据格式、NER 数据格式、BERT 数据格式等,支持自定义扩展。
- token_indexer:负责对 token 进行索引(根据词典转化 id),集成了多种索引器:根据单字索引、根据词索引、根据词的属性索引等,支持自定义扩展。
- tokenizer:负责对文本进行分词,集成了 NLP 任务常用的分词器:qqseg、wordpiece、whitespace、character 等,支持自定义扩展。
- vocabulary:数据词典,支持从训练数据中自动生成,并在训练结束后保存到本地,或从本地已有的词典文件中生成,vocabulary 会以命名空间的形式同时保存多个词典(tokens 词典、labels 词典等)。
模型模块化及可配置
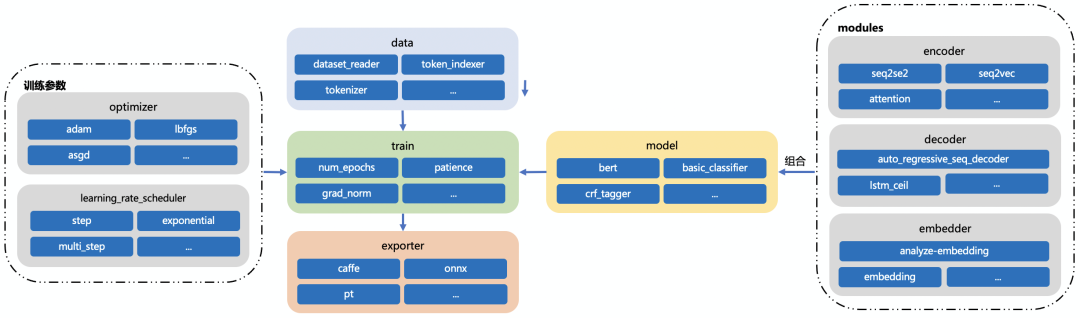
模型的模块化设计可以分为三大块:model、trainer、exporter。
- model:该模块集成了 NLP 任务常见的模型:encoder、decoder、embedder 等,每一个子模型又有其他模型构成,这种组合式的模块化设计,能够很方便的根据配置来定义模型,对于同一类 NLP 任务,模型结构基本大同小异,研究者可以通过修改配置快速的调整模型结构,自定义扩展子模型。
- trainer:TurboNLP-exp 对训练过程中用到的优化器、学习率、评价指标等都进行了封装,通过配置来修改训练参数,达到快速实验的目的。
- exporter:该模块集成了导出各种模型格式:caffe、onnx、pt格式,通过配置来定义导出的格式。
多平台支持
TurboNLP-exp 对底层机器学习平台进行了抽象,实现统一的 framework 接口对底层的 pytorch 和 tensorflow 调用(如下图所示),framework 根据配置来选择 pytorch 或 tensorflow 来实现接口。目前以 pytorch 的格式为标准。
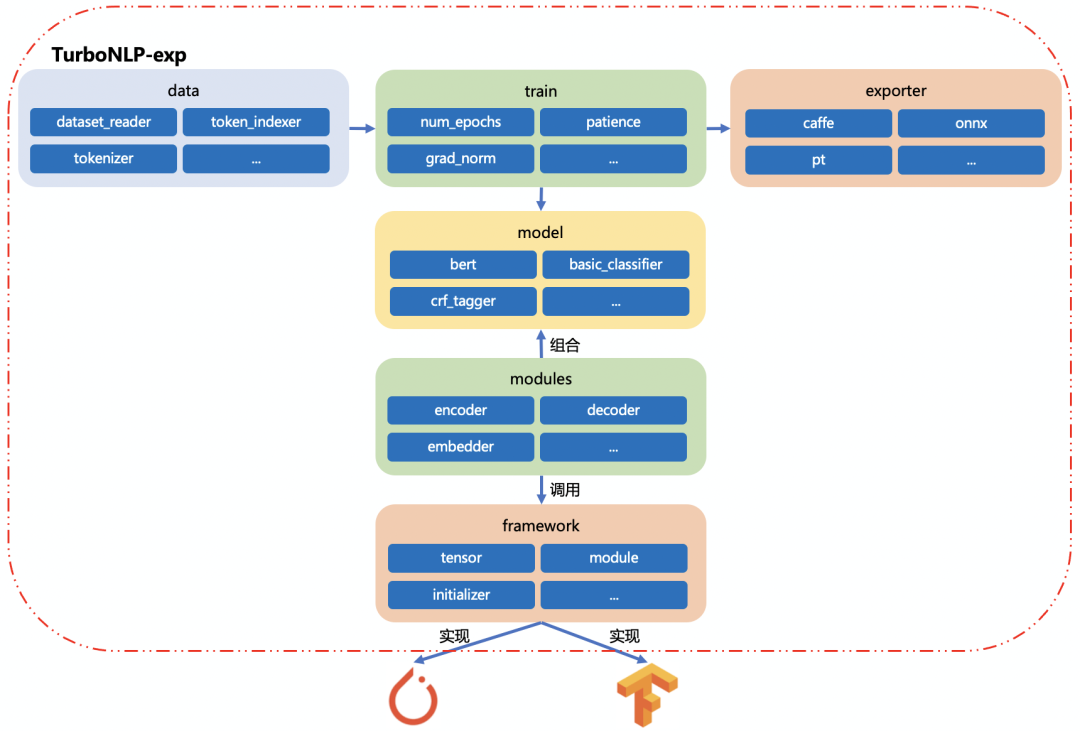
多任务训练
多任务学习通过模拟人类认知过程的多任务特性,将不同类型的任务如实体识别、紧密度等集成在一个模型中,在共用的预训练语言模型上,训练各自的 tagger 层,在训练中,通过各个任务领域知识和目标的相互补充,共同提升任务模型效果,在上线时,使用同一个底层模型,从而达到节省存储及计算资源;目前,多任务的需求日渐增大,TurboNLP-exp 支持多任务多种组合方式及训练调度方式(如下图所示)
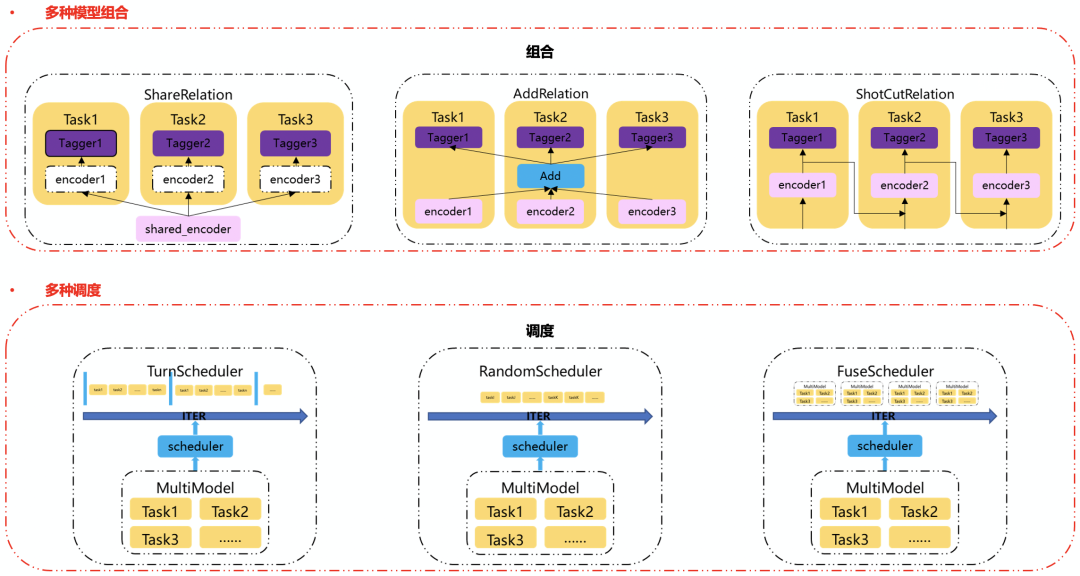
TurboNLP-exp 的多任务模型具备以下几个特点:
- 能通过现有单任务模型快速组合多任务模型。
- 支持多种组合规则,包括:共享、累加、shotcut。
- 共享:多个模型共享同一个 encoder 输出。
- 累加:每个任务的 encoder 累加后输出到每个任务的 tagger 层上。
- shotcut:每个任务的 encoder 输出将作为下个任务的 encoder 输入。
- 支持多种训练调度方式,包括:依次调度、随机调度、共同调度。
- 依次及随机调度属于交替训练,可以在多任务的基础上获取各自任务的最优解,且不需要构造统一输入,更加简单。
- 共同调度属于联合训练,使用统一的输入,由于 loss 最后会累加,因此查找的是多任务综合最优解。
- 用户可根据实际任务场景自由配置对应的组合方式和调度方式,以此来让多任务能达到最优的效果。
多模型格式导出
TurboNLP-exp 能够导出格式:caffe、onnx、pt,支持直接导出 TurboNLP-inference 推理框架支持的格式,直接推理端加载,无需再经过复杂的模型转换。
数据预处理
TurboNLP-exp 的数据预处理能够同时支持 Python、C++,Python 数据预处理主要服务于训练端,C++数据预处理主要服务于推理端,也能服务于训练端(如下图所示)
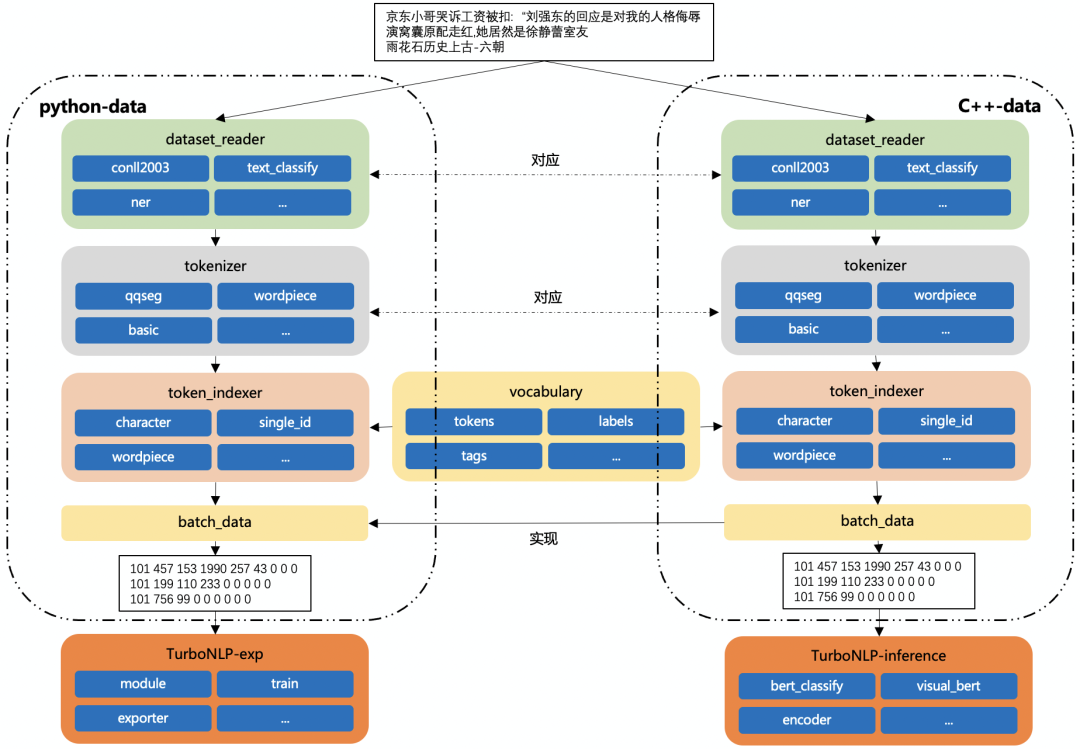
在训练端,当数据预处理还处在修改、调试时,使用 Python 数据预处理能够快速实验,当 Python 数据预处理固定后,通过配置切换为 C++数据预处理来验证数据预处理结果,从而保证训练端和推理端数据一致性。
在推理端,使用与训练端相同的配置,C++数据预处理输出将作为模型输入,C++数据预处理——TurboNLP-data采用多线程、预处理队列来保证数据预处理的低延迟,在 BERT-base 五分类模型上实测,在 batch_size=64、seq_len=64 的情况下达到了0.05ms/query的性能。
TurboNLP-inference 推理框架
TurboNLP-inference 推理框架能够无缝兼容TurboNLP-exp、具备低延迟、可配置等特点,TurboNLP-inference 底层支持五种推理库:BertInference(BERT 推理加速库)、libtorch、tensorflow、TurboTransformers(WXG 开源的 BERT 推理加速库)、BertInference-cpu(BERT 在 CPU 上推理加速库),其中,BertInference是我们基于TensorRT研发的一款高效能 BERT 推理库,BertInference-cpu是和 intel 合作开发的一款在 CPU 上进行 BERT 推理加速库。
以下是推理框架 TurboNLP-inference 和训练框架 TurboNLP-exp 一体化架构图:
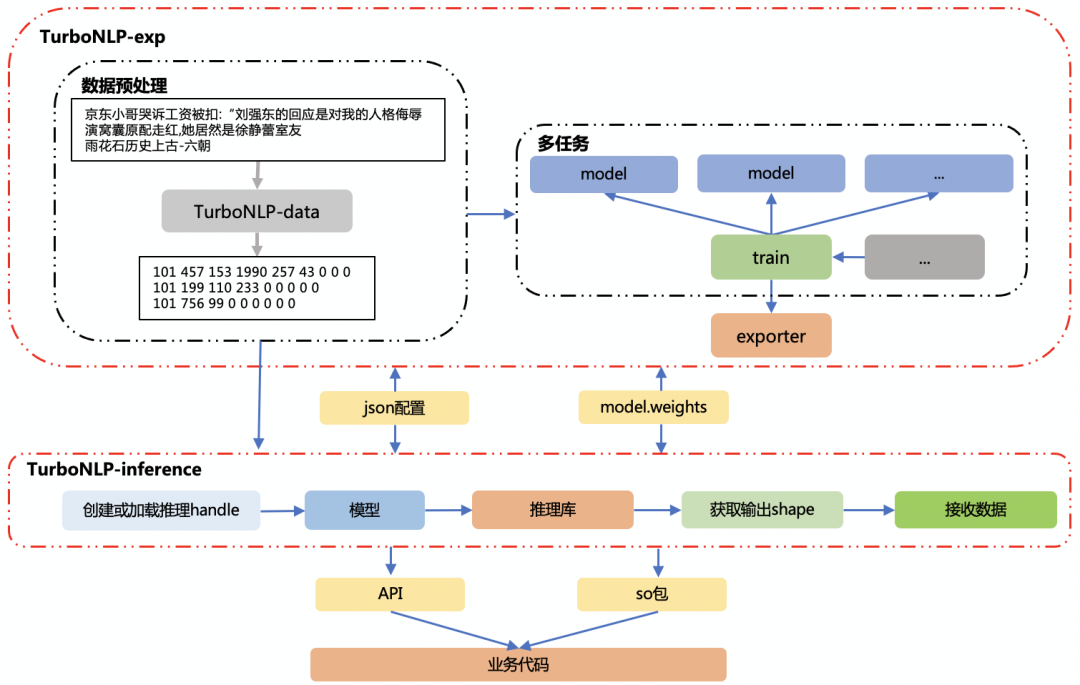
TurboNLP-inference 具备以下特性:
- 集成了 NLP 任务常用的模型:lstm、esim、seq2seq_encoder、attention、transformer等,根据配置构造模型结构及模型输入。
- 能够直接加载TurboNLP-exp的 exporter 导出model.weights模型格式。
- 使用 C++数据预处理——TurboNLP-data,并将数据预处理输出自动的喂入模型输入。
- 推理代码将会以 C++ so 包和 API 的形式嵌入业务代码中,尽量少的侵入业务代码,修改灵活方便。
业务应用
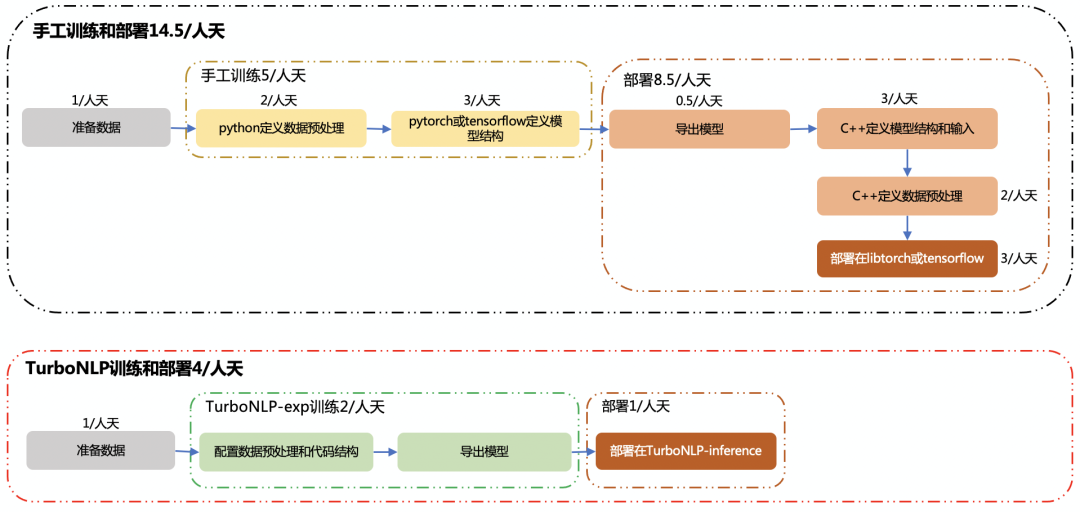
NLP 一体化工具(TurboNLP-exp 训练框架和 TurboNLP-inference 推理框架)极大的简化了模型从训练到上线的流程(如下图所示),依据业务模型的实际上线流程,手工训练和部署需要 14.5/人天,而使用 NLP 一体化工具仅需 4/人天,整体节省了**72.4%**人力成本。
TurboNLP-inference 目前已成功支持了 TEG-AI 平台部-搜索业务中心的 5 个业务:
- 某业务的文档分类 BERT 模型,FP16 精度在 batch_size=64、seq_len=64 的情况下达到了0.290ms/query的性能,机器资源节省了97%,上线周期缩短了近50%,极大的降低了机器和人力成本。
- 某业务的文本视频关系判断 BERT 模型,响应延迟减少为原来的 2/3,设备资源节省了92.8%。
- 某业务的 query 改写 BERT-base 模型,相比于以前,极大的降低了上线周期及人力成本。
- 某业务多任务(encoder 为 BERT,decoder 为 GRU)模型,在 FP16 精度情况下,达到了2ms/query的性能。
- 某业务的 query 非必留 BERT-base 模型,上线周期极大缩短,在 FP16 精度情况下,达到了1.1ms/query的性能。
TurboNLP-inference 在业务上的表现,离不开对训练框架的无缝支持以及底层高效推理库的支持。
最新进展
TurboNLP-inference 的底层高效推理库之一——BertInference 目前已具备支持 INT8 推理,优化了 Attention 计算,我们使用 BERT-base 文本分类业务模型和真实的线上数据进行了性能测试,效果如下:
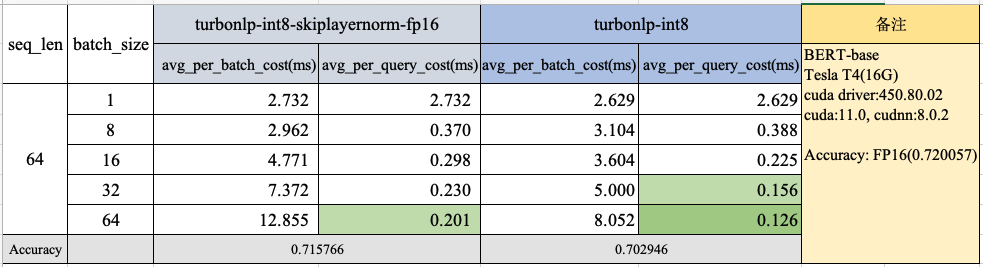
在 batch_size=64,、seq_len=64 的情况下,性能达到了0.126ms/query,INT8 相比于 FP16 提升了**54.2%**左右。
TurboNLP-inference 支持 INT8 校准,能够使用已有的模型直接校准,通过配置调整校准过程,校准过程简单,校准后可以直接使用 INT8 精度进行模型推理。
总结和展望
NLP 一体化工具(TurboNLP-exp 训练框架和 TurboNLP-inference 推理框架)目前已经在 TEG AI 工作组内部演进,在预训练模型方面也有一些合作应用,同时我们也正在积极与 AI 工作组的算力和太极机器学习平台团队积极合作,把训练端能力在平台上更好的开放出来。接下来训练及推理框架也会在 TencentNLP 的公司统一协同 oteam 里面去演进,也期待在公司内更多团队的合作。
TurboNLP-inference 的 BERT 推理加速在 INT8 精度模型效果上仍有进一步的提升空间,目前着力于 QAT 以及知识蒸馏、QAT 目前在五分类 BERT-base 模型上实测,Accuracy 仅降低了0.8%,加入知识蒸馏有望达到 Accuracy 不掉。