本文转载自微信公众号「小姐姐味道」,作者小姐姐养的狗 。转载本文请联系小姐姐味道公众号。
很多接触Docker的同学,都接触过cgroup这个名词。它是Linux上的一项古老的技术,用来实现资源限制,比如CPU、内存等。但有很多同学反映,这项技术有点晦涩,不太好懂。
这就是本篇文章存在的目的,会让你以最简单直观的方式,了解cgroups到底是个什么东西。
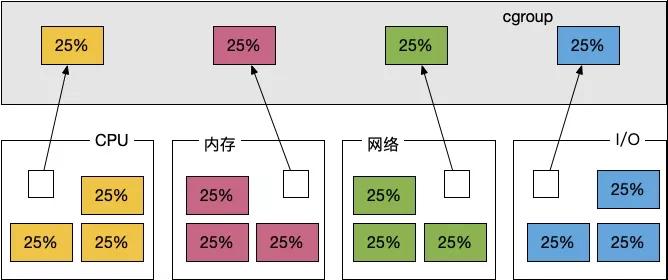
cgroups,是实现docker功能的重要底层设施。如上图,使用cgroups,能够把操作系统的各项资源变成池子,然后通过配置获取相应的资源。
那它是怎么实现的呢?
要注意cgroups这个名词,它有两个特性。首先是c,就是Control的意思,是个动词;第二部分,就是groups,证明它是个组。
1. 动词的目标
control,用来限制什么呢?除了CPU、内存,还有啥?
使用mount命令,查看当前系统支持的限制目标,它有个专用的名词,叫做子系统。
- # mount | grep cgroup
- tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
- cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
- cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
- cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
- cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
- cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
- cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
- cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
- cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
- cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
- cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
- cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
不同的系统版本,会有一些细微的区别,大体上,子系统的分类包含下面这些:
- cpu,cpuacct cpu主要限制进程的 cpu 使用率,cpuacct可以统计 cgroups 中的进程的 cpu 使用报告
- cpuset 可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点,就像Numa做的那些事情一样
- blkio 可以限制进程的块设备 io,比如物理设备(磁盘,固态硬盘,USB 等等)
- devices 控制进程能够访问某些设备
- net_cls 标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制
- net_prio — 这个子系统用来设计网络流量的优先级
- freezer 可以挂起或者恢复 cgroups 中的进程。
- ns 可以使不同 cgroups 下面的进程使用不同的 namespace
- hugetlb 主要针对于HugeTLB系统进行限制,这是一个大页文件系统。
内容很多,但我们平常关注的大多数就是内存和CPU,这些繁杂的细节,不影响我们理解它的设计原则。
下面就以CPU为例,来看一下子系统的实际表现。
2. CPU使用限制的例子
首先,我们进入cpu子系统目录。
- cd /sys/fs/cgroup/cpu
然后,创建一个组名为xjjdog的cgroups,这个名字,就叫做控制组。
- mkdir xjjdog
这时候,神奇的事情发生了。我们使用ll命令,查看xjjdog目录中的内容,发现系统已经为我们默认生成了一堆文件。
- # ll xjjdog/
- total 0
- -rw-r--r-- 1 root root 0 Jan 28 21:09 cgroup.clone_children
- --w--w--w- 1 root root 0 Jan 28 21:09 cgroup.event_control
- -rw-r--r-- 1 root root 0 Jan 28 21:09 cgroup.procs
- -r--r--r-- 1 root root 0 Jan 28 21:09 cpuacct.stat
- -rw-r--r-- 1 root root 0 Jan 28 21:09 cpuacct.usage
- -r--r--r-- 1 root root 0 Jan 28 21:09 cpuacct.usage_percpu
- -rw-r--r-- 1 root root 0 Jan 28 21:09 cpu.cfs_period_us
- -rw-r--r-- 1 root root 0 Jan 28 21:09 cpu.cfs_quota_us
- -rw-r--r-- 1 root root 0 Jan 28 21:09 cpu.rt_period_us
- -rw-r--r-- 1 root root 0 Jan 28 21:09 cpu.rt_runtime_us
- -rw-r--r-- 1 root root 0 Jan 28 21:09 cpu.shares
- -r--r--r-- 1 root root 0 Jan 28 21:09 cpu.stat
- -rw-r--r-- 1 root root 0 Jan 28 21:09 notify_on_release
- -rw-r--r-- 1 root root 0 Jan 28 21:09 tasks
通过控制这些文件里面的数值,就可以对资源进行限制。比如cpu.cfs_quota_us文件,如果我们往里写入100000(十万),那么就证明使用了xjjdog的cgroup,最多能够使用1核的CPU。写入20000,证明最多使用使用1/5核的CPU。
这是因为,cpu.cfs_period_us这个配置文件,默认把1核cpu分成了10万份。
那我们就写入20000试一下。
- sudo echo 20000 > xjjdog/cpu.cfs_quota_us
我们把当前shell的pid,加入被受控进程列表。
- echo $$ > xjjdog/tasks
执行完毕之后,再启动一个死循环。
- while true;do ;done;
重新打开一个shell,使用top观察CPU的使用率。可以发现,我们的死循环,最多只使用了20%的CPU。us保持在20%以下,且不间断的在各个cpu之间切换。
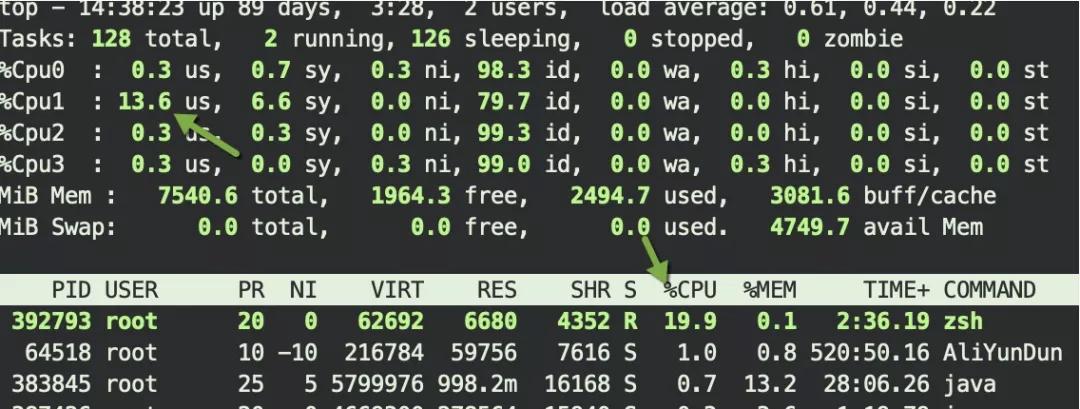
依次试验以下的命令,可以发现CPU的使用,会逐步增加,大体上和我们的限额是相等的。
- sudo echo 40000 > xjjdog/cpu.cfs_quota_us
- sudo echo 60000 > xjjdog/cpu.cfs_quota_us
- sudo echo 100000 > xjjdog/cpu.cfs_quota_us
其他的资源限制,都是类似的思路。那么最重要的工作,就是需要知道cpu.cfs_quota_us这样的字眼,代表的是什么意思,这些对着手册来看是很容易掌握的。比如quota是配额的意思,很明显就是限制资源的使用。
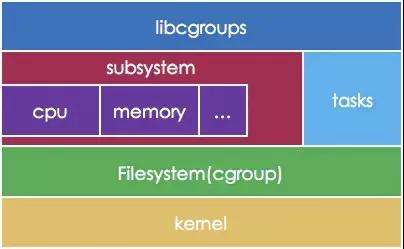
如上图,子系统可以控制多个tasks,把它纳入到控制组之内。我们上篇文章讲到,可以将bash进程,作为docker系统的1号进程,那么同样的,这个1号进程的子进程,都会共享同样的限额配置。
3. group的意思
浅显的来讲,group就是指的对各种资源进行分组。不同名字的资源,有不同的隔离配置。但它有更多的特性。
比较重要的,是它的层级关系(hierarchy)。这个也比较好理解,它主要是为了简化配置而存在的。
比如我上面的xjjdog目录,对cpu的限制限制在0.5核。这时候,我想要有另外一个应用,对cpu的使用限制在0.5核,同时限制内存1gb,那么就可以直接在xjjdog目录下创建xjjdog0目录,在xjjdog0目录下只配置内存方面的就可以了。
另外,如果你在外层的cpu限额限制了2core,然后在继承的目录里限制了1/5核,那它就只能使用操作系统的2/5核。这也是继承的一个特性。
End
cgroups是2006年诞生的,发起人是Google 的工程师(Rohit Seth 和 Paul Menage )。在 2008 年成功合入 Linux 2.6.24 版本中,可以说这项技术是很古老的。cgroups目前已经成为 systemd、Docker、Linux Containers(LXC) 等技术的基础。
像Windows平台的WSL,是没有cgroups功能的,使用mount命令可以验证,这证明了它是不能把docker跑起来的,因为缺乏基础。不过,WSL2已经可以了。
有些同学对docker目前的发展现状有些担心,但当你熟悉了这几个常见的底层原理,读完容器的标准之后,就会发现,上层的实现无论是换成docker也好,换成containerd也罢,都一样!
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。我的个人微信xjjdog0,欢迎添加好友,进一步交流。