本文转载自公众号“读芯术”(ID:AI_Discovery)。
数据科学是一个跨学科领域,其基石之一是统计学。如果没有足够的统计知识,就很难理解或解释数据。
统计学帮助解释数据。我们使用统计学方法,根据从某个总体中抽取的样本,推断出该总体的结果。此外,机器学习和统计学也有很多交叉。要成为一名数据科学家,就需要学习统计学及其概念。本文将具体解释10个基本的统计概念。
1. 总体与样本
总体是一个群体中的所有元素。例如,美国的大学生是包括美国所有大学生的总体。在欧洲25岁的人是一个总体,该总体包括所有符合该描述的人。
由于我们不能收集一个总体的所有数据,因此对总体进行分析有时是不可行或不可能的,因此,可以借助样本进行分析。样本是总体的一个子集。例如,1000名美国大学生是“美国大学生”总体的一个子集。
2. 正态分布
概率分布是表示事件或实验结果概率的函数。考虑数据帧中的一个特性(即列)。这个特征是一个变量,它的概率分布函数显示了可以取值的区间。
概率分布函数在预测分析或机器学习中非常有用。我们可以根据某个总体样本的概率分布函数来预测该总体。
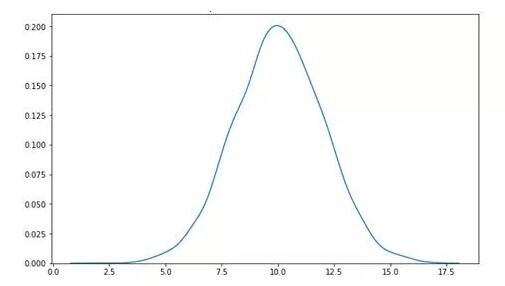
正态(高斯)分布是一个概率分布函数,看起来像一个钟型。下图显示了典型正态分布曲线的形状。
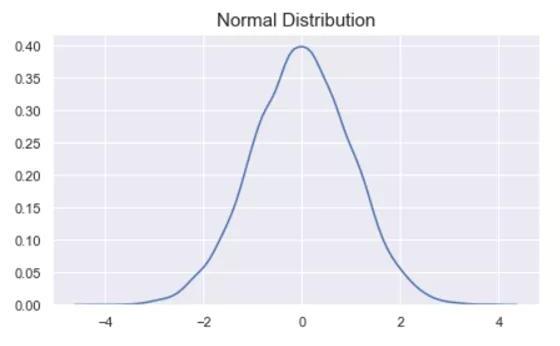
曲线的峰值表示变量最可能采用的值。离峰值越远,取该值的概率就越小。
3.量度集中趋势
中心趋势是概率分布的中心值(或典型值)。最常用的中心趋势度量是平均数、中位数和众数。
· 平均数是一列数值的平均值。
· 中位数是按升序或降序排序时中间的值。
· 众数是最常出现的值。
4.方差与标准差
方差是值之间变化的度量。它的计算方法是求每个值和平均值的平方差,然后将这些平方差相加,最后将总和除以样本数。
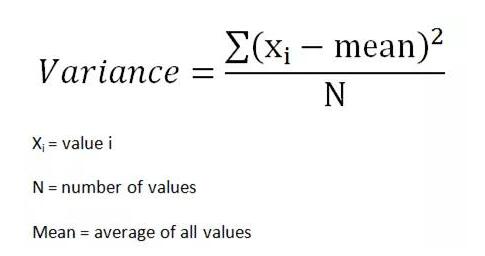
标准差是衡量数值分布的一种方法,它是方差的平方根。
5. 协方差和相关性
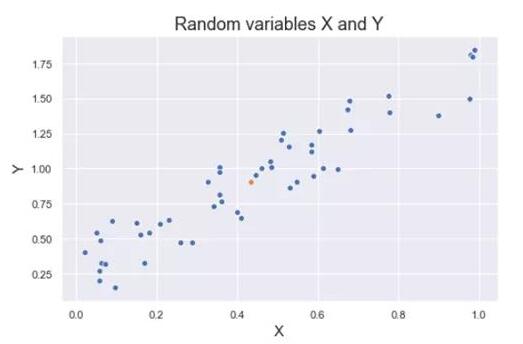
协方差是一种定量方法,它表示两个变量的变化在多大程度上相互匹配。更具体地说,协方差以其平均值(或预期值)来比较两个变量的偏差。
下图显示了随机变量X和Y的一些值。橙色点表示这些变量的平均值。这些值的变化与变量的平均值类似。因此,X和Y之间存在正值协方差。
两个随机变量的协方差公式:
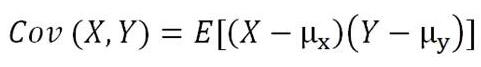
其中E是期望值,µ是平均值。
相关性是通过每个变量的标准差对协方差进行正态化。
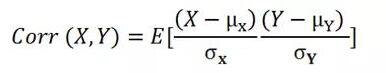
其中σ是标准偏差。
这种正态化消除了单位,相关值始终在0和1之间。请注意,这是绝对值。如果两个变量之间存在负相关性,则相关性介于-1和0之间。如果比较三个或更多变量之间的关系,最好使用相关性,因为值的范围或单位可能会导致其假设错误。
6.中心极限定理
随机变量的分布在社会科学的许多领域都鲜为人知,因此正态分布得以广泛应用。
中心极限定理(CLT)解释了为什么正态分布可以用来证明这种极限情况。根据中心极限定理,当我们从一个分布中抽取更多样本时,无论总体分布如何,样本平均值都将趋向于正态分布。
思考这样一个案例:我们需要了解一个国家所有20岁人群的身高分布。收集这些数据几乎是不可能,也不实际的。所以,我们在全国范围内抽取了20岁的人群样本,计算样本中人群的平均身高。中心极限定理指出,当我们从人群中抽取样本越多时,样本分布将越接近正态分布。
为什么正态分布如此重要?正态分布是用均值和标准差来描述的,可以很容易地计算出来。如果知道正态分布的平均值和标准差,就可以计算出几乎所有关于它的信息。
7.P值
P值是衡量随机变量取值可能性的量。假设有一个随机变量A和x值,x的p值是A取x值时的概率,或者是取任何其他值时,有相同或更少机会被观察到的值的概率。
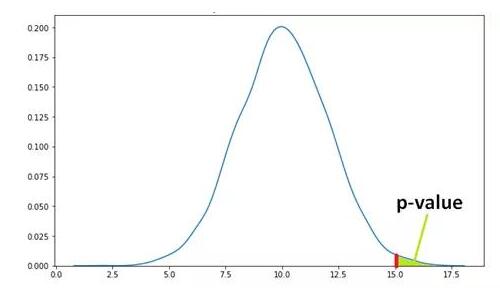
下图显示了A的概率分布,很容易就观察到10左右的值。随着值的增大或减小,概率降低。
有另一个随机变量B,而且想看B是否大于A。从B中获得的平均样本均值为12.5。12.5的p值位于下图中的绿色区域。绿色区域表示获得12.5或更大极值的概率(在本例中高于12.5)。
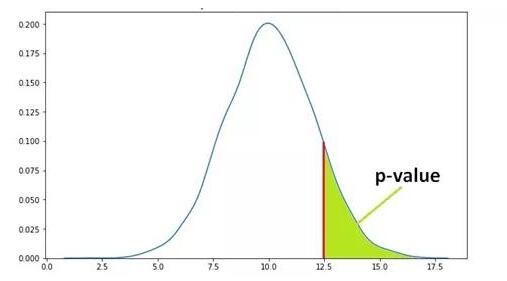
假设p值是0.11,怎么解释呢?p值为0.11意味着我们对结果有89%的把握。换言之,该结果受随机事件影响的可能性有11%。类似地,p值为0.05意味着结果受到随机事件影响的可能性为5%。
如果随机变量B的样本均值的平均值为15,这是一个更极端的值,p值将低于0.11。
8.期望值和随机变量
随机变量的期望值是该变量所有可能值的加权平均值。这里的权重是指随机变量取特定值的概率。对于离散和连续随机变量,期望值的计算是不同的。
· 离散随机变量取有限多或可数无限多的值。一年中的雨天数是一个离散的随机变量。
· 连续随机变量取不可数的无穷多个值。例如,从家到办公室的时间是一个连续的随机变量。根据你测量它的方式(分、秒、纳秒等等),它需要无数个值。
离散随机变量期望值的公式为:
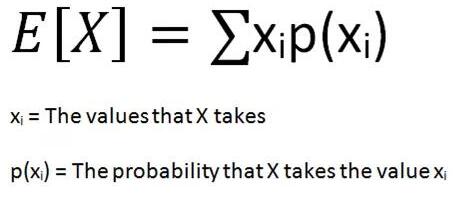
连续随机变量的期望值用相同的逻辑计算,但方法不同。因为连续的随机变量可以取不可数的无穷多个值,所以我们不能谈论取特定值的变量。我们更关注其有价值的范围。
为了计算值范围的概率,使用概率密度函数(PDF)。PDF是一个函数,指定随机变量在特定范围内取值的概率。
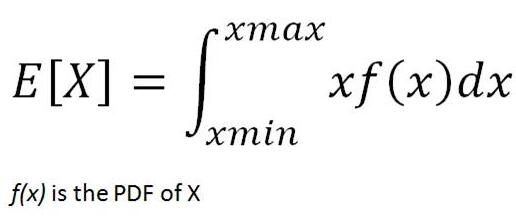
9. 条件概率
概率单纯是指事件发生的可能性,永远取0到1(包括0和1)之间的值。事件A的概率表示为p(A),并有期望结果的数量除以所有结果的数量来计算。例如,当掷骰子时,得到小于3的数字的概率是2/6。期望结果数为2(1和2);总结果数为6。
条件概率是假设与事件A有关的另一个事件已经发生时,事件A发生的可能性。
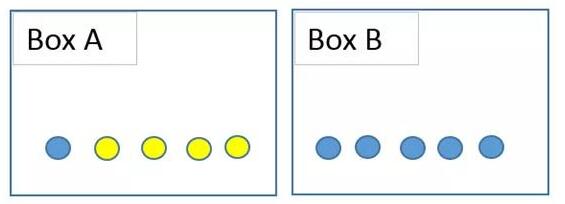
如下所示,假设有两个盒子,盒子里放着6个蓝色的球和4个黄色的球。我让你随便挑一个球。得到蓝球的概率是6/10=0,6。如果我让你从A盒中挑一个球结果会怎样?
选择蓝色球的概率明显降低。这里的条件是从A盒中取球,与之前事件(挑选一个蓝色的球)发生的概率相比,发生了明显改变。给定事件B已经发生的事件A的概率表示为p(A | B)。
10. 贝叶斯定理
根据贝叶斯定理,在给定事件B已经发生的条件下,A发生的概率以及给定事件A已经发生的条件下,事件B发生的概率可以用事件A和事件B的概率来计算。
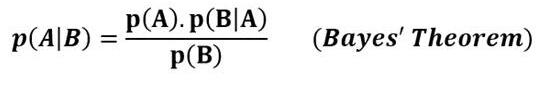
这就是所谓的普遍存在的贝叶斯统计定理。在贝叶斯统计定理中,事件或假设事件发生的概率可以作为证据发挥作用。因此,先验概率和后验概率因证据而异。
朴素贝叶斯算法是结合贝叶斯定理和一些朴素假设构造的。朴素贝叶斯算法假设特征是相互独立的,特征之间没有相关性。
当然,关于统计学还有很多东西要学。从基础知识开始,你可以稳步地深入到高级主题。