只需两步,将文献的 arXiv 信息转换为正式来源信息。
伴随着预印本平台 arXiv 的广泛使用,越来越多的研究者喜欢在写论文参考文献时直接使用 arXiv 信息。这看似非常方便,但也存在问题:这篇 arXiv 论文是否在 ACL、EMNLP、NAACL、ICLR 或 AAAI 等学术会议上发表过?
没错,在某些情况下,只引用 arXiv 信息显得不那么准确,这种不准确的文献条目甚至可能会违反某些会议的论文提交或 camera-ready 版本提交规则。
如何解决这一问题呢?最近,上交毕业生、南加州大学博士生林禹臣开发了一个简单的 Python 工具——Rebiber,它能够基于 ACL Anthology 和 DBLP 数据库自动解决这一问题。
项目地址:https://github.com/yuchenlin/rebiber

下图展示了 Rebiber 的使用示例:
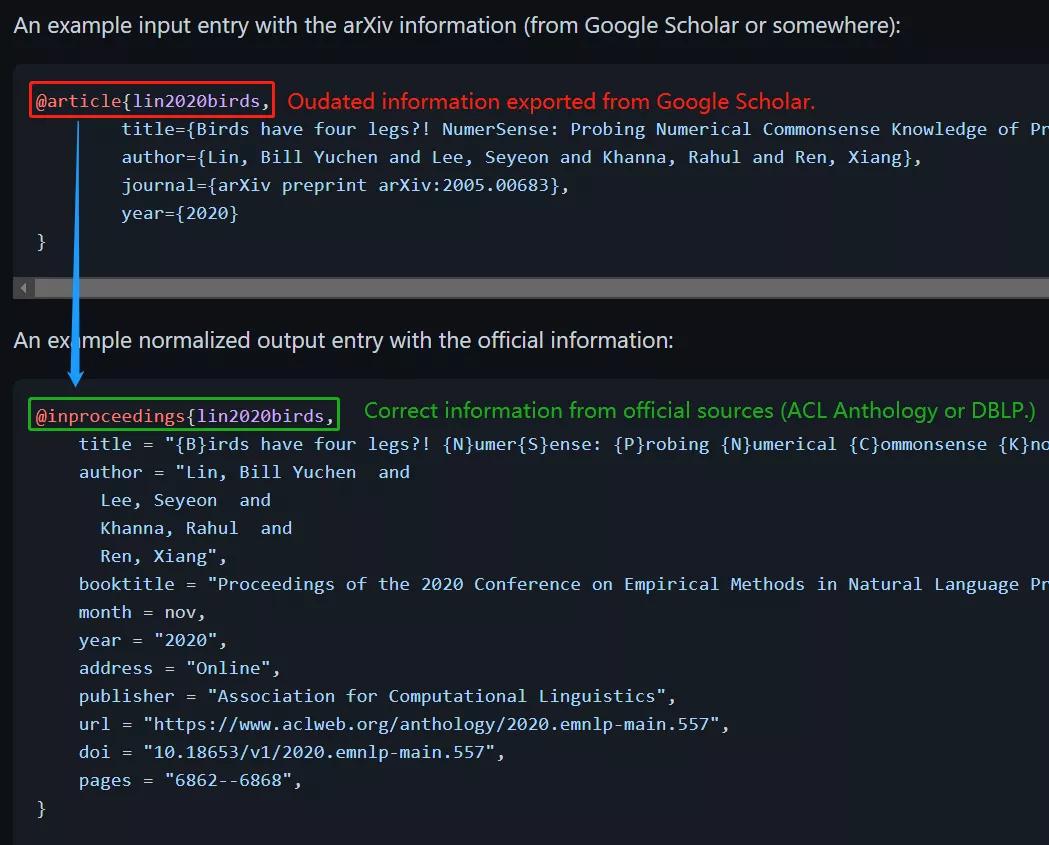
在该示例中,文章的原始信息来自 Google Scholar,仅包括标题、作者、期刊(arXiv)、年份。而事实上该论文已被 EMNLP 2020 接收,原始信息显然不够准确。
经过 Rebiber 转换后,原始 arXiv 信息被转换为来自正式来源的准确信息,包括标题、作者、年月、出版商、数字对象识别码(doi)、网址等详细内容。
Rebiber 支持的会议包括 ACL Anthology 涵盖的会议,如 ACL、EMNLP、NAACL 及其 workshop,以及 DBLP 涵盖的会议,如 ICLR 2020。
目前,Rebiber 支持的会议列表如下所示:
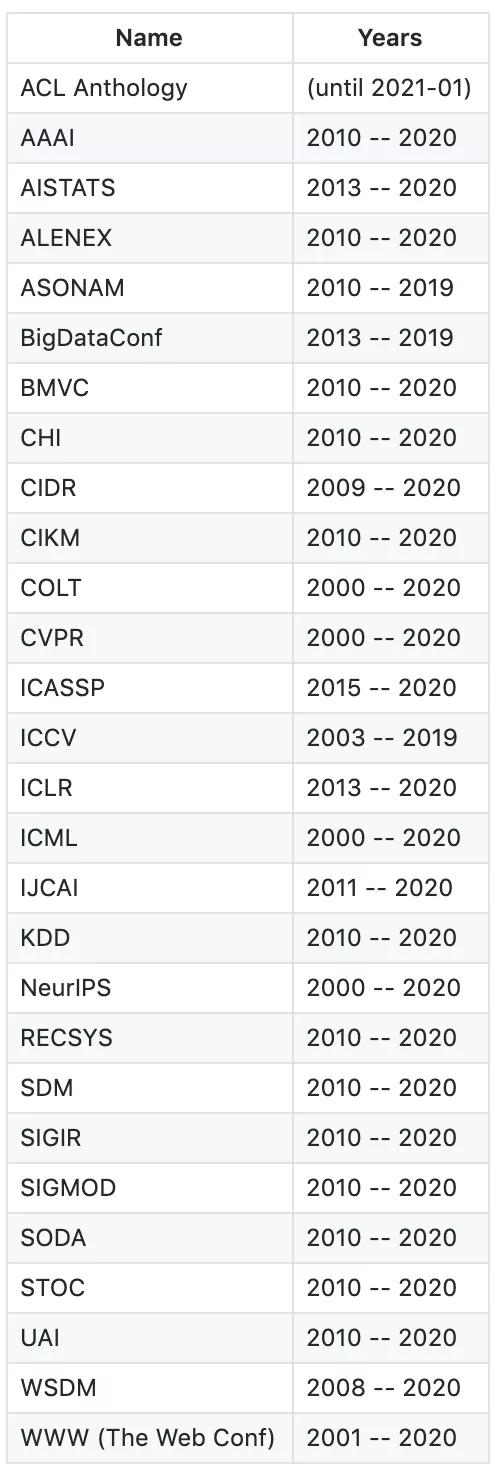
使用者还可以手动添加 DBLP 包含的任意会议:只需从 DBLP 中下载会议 bib 文件至 data 文件夹,然后将其转换为 json 格式,再把路径添加至 bib_list.txt 即可。
如何使用?
这款工具的使用也很简单。
首先,运行以下命令行:
- git clone https://github.com/yuchenlin/rebiber.git
- pip install bibtexparser tqdm
- cd rebiber
然后,将文献条目归一化为正式格式:
- python normalize.py -i example_input.bib -o example_output.bib -l bib_list.txt
只需要简单的操作,就可以将 arXiv 信息转换为正式信息了。
项目作者简介
项目作者林禹臣本科毕业于上海交通大学 IEEE 试点班,曾获上海市优秀本科生奖学金、上海交通大学优异学士学位论文奖,现在南加州大学攻读计算机科学博士学位,导师为南加州大学计算机科学学院助理教授、情报与知识发现(INK)研究实验室主任任翔。
他曾在微软亚洲研究院和谷歌 AI 有多段实习经历,研究兴趣包括构建能够深度理解世界的神经符号系统、集成信息提取、知识图谱、机器推理、图神经网络和模型鲁棒性的技术。近期研究集中在利用常识推理推动自然语言处理(理解与生成)。多篇论文发表在 ICLR、AAAI、EMNLP、KDD、ACL 等学术会议上。