表格是存储数据的最典型方式,在Python环境中没有比Pandas更好的工具来操作数据表了。 尽管Pandas具有广泛的能力,但它还是有局限性的。比如,如果数据集超过了内存的大小,就必须选择一种替代方法。 但是,如果在内存合适的情况下放弃Pandas使用其他工具是否有意义呢?
Pandas是一种方便的表格数据处理器,提供了用于加载,处理数据集并将其导出为多种输出格式的多种方法。 Pandas可以处理大量数据,但受到PC内存的限制。 数据科学有一个黄金法则。 如果数据能够完全载入内存(内存够大),请使用Pandas。 此规则现在仍然有效吗?
为了验证这个问题,让我们在中等大小的数据集上探索一些替代方法,看看我们是否可以从中受益,或者咱们来确认只使用Pandas就可以了。
您可以在GitHub上查看完整的代码
pandas_alternatives_POC.ipynb —探索dask,spark,vaex和modin julia_POC.ipynb —探索julia和julia性能测试 Performance_test.py —运行python性能测试控制台运行 Results_and_Charts.ipynb —处理性能测试日志并创建图表
Pandas替代
让我们首先探讨反对替代Pandas的论点。
1. 他们不像Pandas那么普遍
1. 文档,教程和社区支持较小
我们将逐一回顾几种选择,并比较它们的语法,计算方法和性能。 我们将看一下Dask,Vaex,PySpark,Modin(全部使用python)和Julia。 这些工具可以分为三类:
· 并行/云计算— Dask,PySpark和Modin
· 高效内存利用— Vaex
· 不同的编程语言— Julia
数据集
对于每种工具,我们将使用Kaggle欺诈检测数据集比较基本操作的速度。 它包含两个文件traintransaction.csv(〜700MB)和trainidentity.csv(〜30MB),我们将对其进行加载,合并,聚合和排序,以查看性能有多快。 我将在具有16GB RAM的4核笔记本电脑上进行这些操作。
主要操作包括加载,合并,排序和聚合数据
Dask-并行化数据框架
Dask的主要目的是并行化任何类型的python计算-数据处理,并行消息处理或机器学习。 扩展计算的方法是使用计算机集群的功能。 即使在单台PC上,也可以利用多个处理核心来加快计算速度。
Dask处理数据框的模块方式通常称为DataFrame。 它的功能源自并行性,但是要付出一定的代价:
1. Dask API不如Pandas的API丰富
1. 结果必须物化
Dask的语法与Pandas非常相似。

如您所见,两个库中的许多方法完全相同。但是dask基本上缺少排序选项。 那是因为并行排序很特殊。 Dask仅提供一种方法,即set_index。 按定义索引排序。
我们的想法是使用Dask来完成繁重的工作,然后将缩减后的更小数据集移动到pandas上进行最后的处理。这就引出了第二个警告。必须使用.compute()命令具体化查询结果。
与PySpark一样,dask不会提示您进行任何计算。 准备好所有步骤,并等待开始命令.compute()然后开始工作。
为什么我们需要compute() 才能得到结果?
你可能会想,为什么我们不能立即得到结果,就像你在Pandas手术时那样?原因很简单。Dask主要用于数据大于内存的情况下,初始操作的结果(例如,巨大内存的负载)无法实现,因为您没有足够的内存来存储。
这就是为什么要准备计算步骤,然后让集群计算,然后返回一个更小的集,只包含结果。这是目前分布式计算框架的一个通用的做法。
# the dask code goes for example like this: df = dd.read_csv(path) d2 = dd.read_csv(path2) re = df.merge(d2, on="col") re = re.groupby(cols).agg(params).compute()
Dask性能
如何比较用于不同目的的两个平台的速度并非易事。 结果也可能因数据而有所偏差。 一种工具可以非常快速地合并字符串列,而另一种工具可以擅长整数合并。
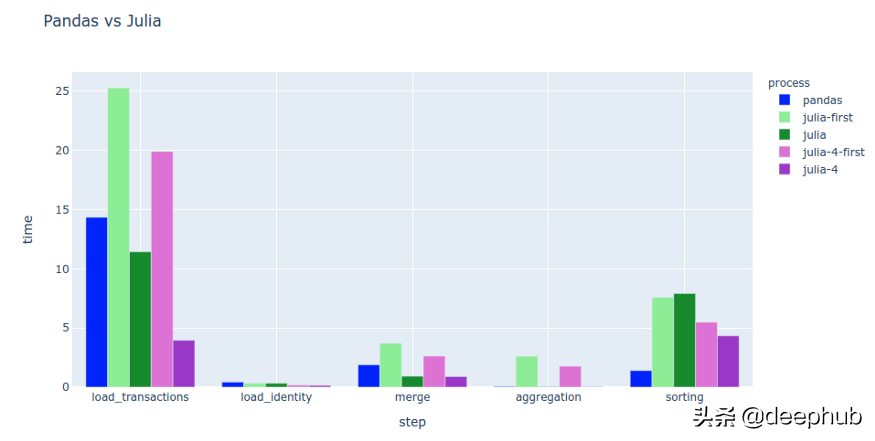
为了展示这些库有多快,我选择了5个操作,并比较了它们的速度。我重复了7次性能测试,我测量的cpu和内存使用率从来没有超过PC的50% (i7-5600 @ 2.60Ghz, 16GB Ram, SSD硬盘)。除了操作系统和性能测试之外,没有其他进程在运行。
· load_transactions —读取〜700MB CSV文件
· load_identity —读取〜30MB CSV文件
· merge—通过字符串列判断来将这两个数据集合
· aggregation—将6列分组并计算总和和平均值
· sorting—对合并数据集进行3次排序(如果库允许)
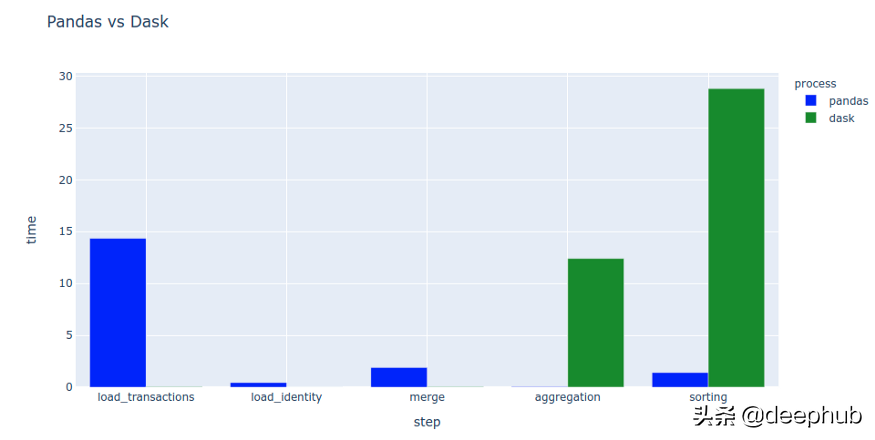
看起来Dask可以非常快速地加载CSV文件,但是原因是Dask的延迟操作模式。 加载被推迟,直到我在聚合过程中实现结果为止。 这意味着Dask仅准备加载和合并,但具体加载的操作是与聚合一起执行的。
Dask对排序几乎没有支持。 甚至官方的指导都说要运行并行计算,然后将计算出的结果(以及更小的结果)传递给Pandas。
即使我尝试计算read_csv结果,Dask在我的测试数据集上也要慢30%左右。 这仅证实了最初的假设,即Dask主要在您的数据集太大而无法加载到内存中是有用的。
PySpark
它是用于Spark(分析型大数据引擎)的python API。 Spark已经在Hadoop平台之上发展,并且可能是最受欢迎的云计算工具。 它是用Scala编写的,但是pySpark API中的许多方法都可以让您进行计算,而不会损失python开发速度。
与Dask类似,首先定义所有操作,然后运行.collect()命令以实现结果。 除了collect以外,还有更多选项,您可以在spark文档中了解它们。
PySpark语法
Spark正在使用弹性分布式数据集(RDD)进行计算,并且操作它们的语法与Pandas非常相似。 通常存在产生相同或相似结果的替代方法,例如sort或orderBy方法。
首先,必须初始化Spark会话。 然后使用python API准备步骤,也可以使用Spark SQL编写SQL代码直接操作。

如果只是为了测试,则不必安装spark,因为PySpark软件包随附了spark实例(单机模式)。 但是要求必须在PC上安装Java。
Spark性能
我使用了Dask部分中介绍的pySpark进行了相同的性能测试,结果相似。
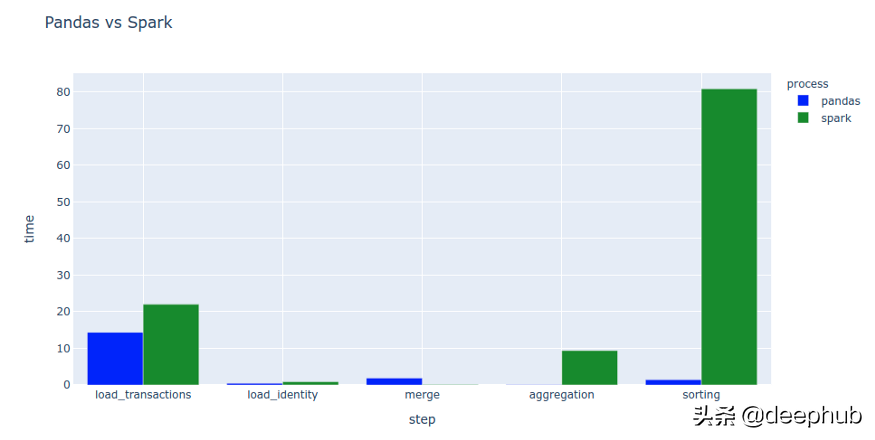
区别在于,spark读取csv的一部分可以推断数据的架构。 在这种情况下,与将整个数据集加载到Pandas相比花费了更多的时间。
Spark是利用大型集群的强大功能进行海量计算的绝佳平台,可以对庞大的数据集进行快速的。但在相对较小的数据上使用Spark不会产生理想的速度提高。
Vaex
到目前为止,我们已经看到了将工作分散在更多计算机核心之间以及群集中通常有许多计算机之间的平台。 他们还无法击败Pandas而 Vaex的目标是做到这一点。
作者创建该库是为了使数据集的基础分析更加快速。 Vaex虽然不支持Pandas的全部功能,但可以计算基本统计信息并快速创建某些图表类型。
Vaex语法
Pandas和vaex语法之间没有太多区别。

Vaex性能
与前两种工具不同,Vaex的速度与Pandas非常接近,在某些地区甚至更快。
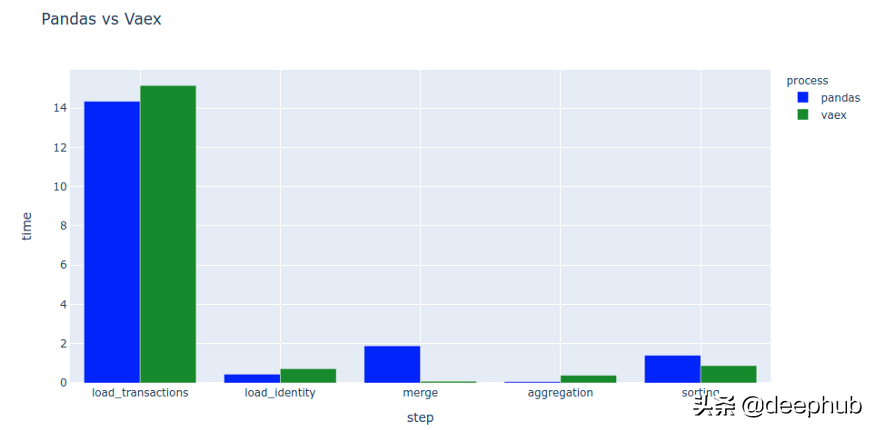
通常情况下,Pandas会很好,但也有可能你会遇到困难,这时候可以尝试以下vaex。
Julia
Julia在数据科学界颇受欢迎。尽管尚未取得突破,但人们曾预言它会有一个辉煌的未来,并且有很多人爱上了Julia的处理方式。
与python相反,Julia是一种编译语言。这通常会带来更好的性能。这两种语言都可以在jupiter notebook上运行,这就是为什么Julia在数据科学证明方面很受欢迎。
Julia语法
Julia是专门为数学家和数据科学家开发的。尽管Julia是一种不同的语言,但它以python的方式做很多事情,它还会在合适的时候使用自己的技巧。
另一方面,在python中,有许多种类库完成相同的功能,这对初学者非常不友好。但是Julia提供内置的方法来完成一些基本的事情,比如读取csv。
让我们来比较一下pandas和julia中数据加载、合并、聚合和排序的效果。

Julia性能
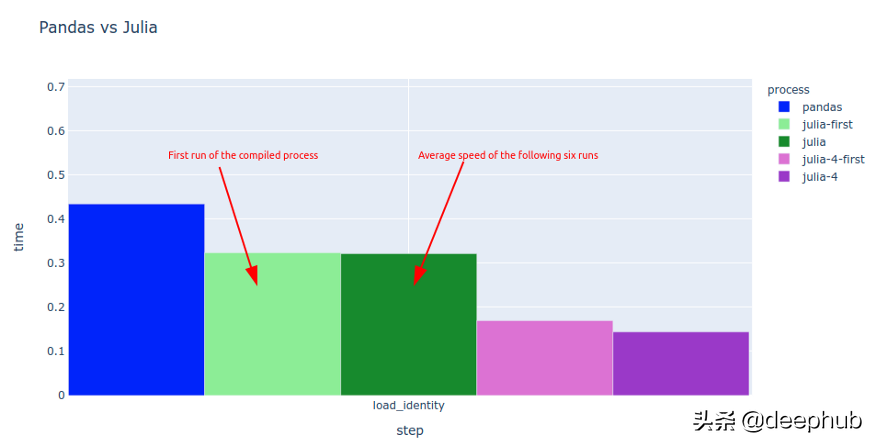
要衡量Julia的速度并不是那么简单。 首次运行任何Julia代码时,即时编译器都需要将其翻译为计算机语言,这需要一些时间。 这就是为什么任何代码的第一次运行都比后续运行花费更长的时间的原因。
在下面的图表中,您可以看到第一次运行的时间明显长于其余六次测量的平均值。 我还尝试过在单个内核(julia)和4个处理器内核(julia-4)上运行Julia。
通过将环境变量JULIANUMTHREADS设置为要使用的内核数,可以运行具有更多内核的julia。 从1.5开始,您可以通过julia -t n或julia --threads n启动julia,其中n是所需的内核数。
使用更多核的处理通常会更快,并且julia对开箱即用的并行化有很好的支持。 您可能会担心编译速度,但是不需要,该代码将被编译一次,并且更改参数不会强制重新编译。 例如在编译CSV.read(joinpath(folder,file), DataFrame)之后,即使您更改了源文件的路径,也将处理以下调用而不进行编译。 这就是为什么在load_identity步骤中看不到任何延迟的原因,因为CSV读取之前已经进行了编译。
Modin
在结束有关Pandas替代品的讨论之前,我必须提到Modin库。 它的作者声称,modin利用并行性来加快80%的Pandas功能。 不幸的是,目前没发现作者声称的速度提升。 并且有时在初始化Modin库导入命令期间会中断。 有一些情况,modin提示:"not supported, defaulting to pandas",然后该操作终崩溃了,只剩下4个python进程,每个进程都占用大量内存。 使得我之后花了一些时间杀死这些进程。
我喜欢modin背后的想法,我希望有一天能够弥补这些差距,从而使modin提升为值得考虑的替代方案。
最后总结
我们已经探索了几种流行的Pandas替代品,以确定如果数据集足够小,可以完全装入内存,那么使用其他数据是否有意义。
目前来看没有一个并行计算平台能在速度上超过Pandas。考虑到它们更复杂的语法、额外的安装要求和缺乏一些数据处理能力,这些工具不能作为pandas的理想替代品。
Vaex显示了在数据探索过程中加速某些任务的潜力。在更大的数据集中,这种好处会变得更明显。
Julia的开发考虑到了数据科学家的需求。它可能没有Pandas那么受欢迎,可能也没有Pandas所能提供的所有技巧。对于某些操作,它可以提供性能提升,我必须说,有些代码在julia中更优雅。即使Julia没有进入前20名最流行的编程语言,我想它还是有前途的,如果你关注它的开发,你就不会犯错误。
最后如果你想复现这些结果,请在查看这个代码:github/vaclavdekanovsky/data-analysis-in-examples/tree/master/DataFrames/Pandas_Alternatives
译者注:虽然我一直觉得pandas有点慢,但是看了上面的评测,还是继续用pandas吧。另外这里有个小技巧,pandas读取csv很慢,例如我自己会经常读取5-10G左右的csv文件,这时在第一次读取后使用topickle保存成pickle文件,在以后加载时用readpickle读取pickle文件,不仅速度上会快10几倍,文件的大小也会有2-5倍的减小(减小程度取决于你dataframe的内容和数据类型)
最后总结还是那句话,当数据能全部加载到内存里面的时候,用Pandas就对了