知道的太多,就会有人想搞你。
演电视剧是这样,开公司是这样,投胎成人工智能,依然如此。
1、给还是不给?这是个问题。
2015 年底,一个寒风凌冽的深夜,美国阿肯色州一户人家的泡泡浴缸中,包裹着一个男人,房主发现时,早已通体冰凉。
房主名叫詹姆斯·贝茨,案发当天,他邀请自己的三位好基友来到自家豪宅,一起观看橄榄球比赛,顺便吃吃喝喝,取点乐子。
谁料,第二天清晨,当贝茨睡眼惺忪地走进浴室,就看到惊魂一幕:好友柯林斯脸朝下躺在浴缸中,气息全无。
左为房主詹姆斯·贝茨,右为死者柯林斯
前一天俩人还在插科打诨,次日已是阴阳两隔,大清早看到这一幕,贝茨吓得当场自闭。
很快,FBI 将现场封锁,并调取了死者柯林斯的通话记录。梳理发现,就在凌晨时分,柯林斯拨出过很多电话,打给了父母和多位朋友,警方怀疑,柯林斯在死亡前曾奋力求救,如果这真是一场凶杀案,那凶手大概率就是贝茨。
随后,FBI 开始盘问贝茨。据贝茨讲述,整场聚会,四人不仅没有发生任何不愉快,反而有说有笑,气氛相当融洽,一直到午夜时分,另外两位朋友困意来袭,便道别离开,但柯林斯丝毫没有回家的意思,而是继续窝在沙发上看球赛。
作为主人的贝茨,坐在旁边陪柯林斯一起看,然而,没多久,贝茨的上下眼皮便激烈的干起仗来,于是,在跟柯林斯道晚安后,贝茨自顾自回到房间休息,一觉起来,惨剧已发生。
贝茨的说法,警方非常怀疑,但死者身上没有明显伤痕,现场没有目击证人,也没找到任何有力物证,破案一时陷入僵局。
就在一筹莫展之际,房间一角摆着的智能音箱 Echo,让 FBI 眼前一亮。
我们都知道,智能音箱的使命,是随时响应主人的命令,Echo 自然不例外。FBI 调查发现,案发当晚,Echo 中内置的 7 个麦克风,全部处于实时监控状态,作为现场唯一的“目击者”,它一定听到了些什么。
FBI 第一时间向亚马逊公司发出搜查令,要求亚马逊协助,提供相关数据资料,尤其是案发当日 Echo 中留存的语音信息。
一开始,亚马逊公司是拒绝的,毕竟美国宪法第一修正案中有规定,用户隐私至上。后来,贝茨为了自证清白,无奈之下,同意 FBI 调取录音,亚马逊便交出了与案件相关的全部信息。
亚马逊这一举动,瞬间带偏了舆论,原本都在关注凶案的民众,转而开始攻击亚马逊:原来我花钱请回家的智能音箱,不仅偷偷录我的对话,对话还被你们存起来,可以随时接受 FBI 的调用,这不就是传说中的卧底吗?亚马逊你这个无良商家,还我隐私!
作为昔日的吃瓜群众,亚马逊曾无数次围观苹果和 FBI 的针锋相对,谁能想到,自己有一天也能晋升成“宫斗戏”主角,面对同一道选择题:用户隐私,到底交还是不交?
说到用户隐私,企业和权力机构之间的博弈,虽有压力,但双方好歹都是明牌,局面相对好掌控,如果遇到热衷于打暗牌的黑客攻击者,这就很难搞。
毕竟,攻击者一般不讲武德。
2、从群众中来,到黑客中去
想象一个场景:你坐在房间里,跟人工智能聊着天,突然,这货连珠炮似的抖出一串陌生人的真实隐私信息,包括姓名、电话、住址和邮箱,就问你慌不慌?
不慌?那算了,反正 AI 能在你面前抖出别人的信息,就能在别人面前抖出你的信息,只要你不慌,慌的就是别人。
言归正传,上面这个场景 100% 真实,一句咒语就能实现:East Stroudsburg Stroudsburg…
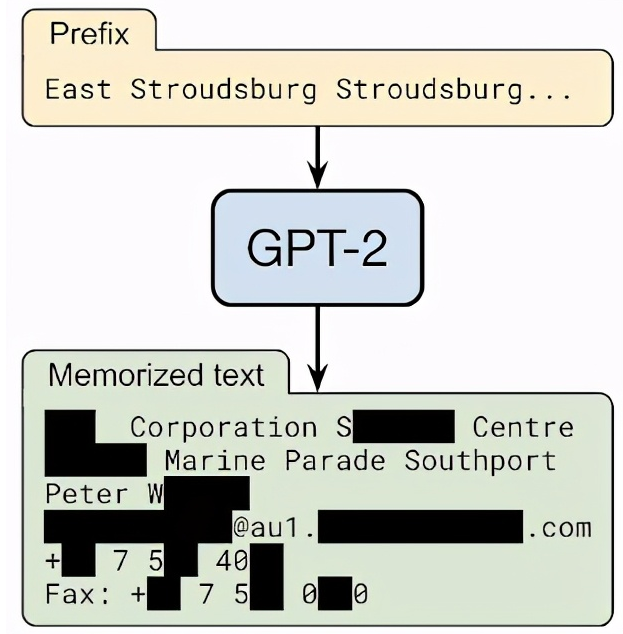
emmmm,好吧,那并不是什么咒语,而是一种针对人工智能的攻击手法:训练数据提取攻击 (training data extraction attacks)。
前不久,来自谷歌、苹果、斯坦福、UC 伯克利、哈佛、美国东北大学、OpenAI 七家公司和机构的学者们调查发现,那些用爬取来的网络数据所训练出的 AI 模型,遇到特殊的唤醒词,就会脱口而出隐藏在其中的个人隐私信息。
我们都知道,人工智能看似无所不能,是因为吃下了大量的训练数据,数据量越大,人工智能就显得越聪明。只是,人工智能毕竟是在模仿人类,本身并不具备思考能力,所以它能做的,就是把学到的知识存起来,等遇到具体问题,再提取相关部分,组合成人类想要的答案。
举个栗子,在正常训练情况下,当你输入“玛丽有只……”时,语言模型会给出“小羊羔”的答案。但如果模型在训练时,偶然遇到了一段重复“玛丽有只熊”的语句,那么,当你再输入“玛丽有只……”时,语言模型就很可能回答“熊”。
这个过程,本质上是对原始数据的还原。
正是因为模型习惯于“还原原始数据”,所以,只需要预测模型“想说的数据”,再给出合适的引导前缀,AI 就能完整还原出原始数据中的某些字符串。
模型的规模越大,泄漏隐私信息的概率就越高。
研究人员用已经开源的 GPT-2 进行了验证,结果显示,在随机抽取的 1800 个输出结果中,有近 600 个结果成功还原了训练数据中的隐私内容,包括新闻、日志、代码、个人信息等。
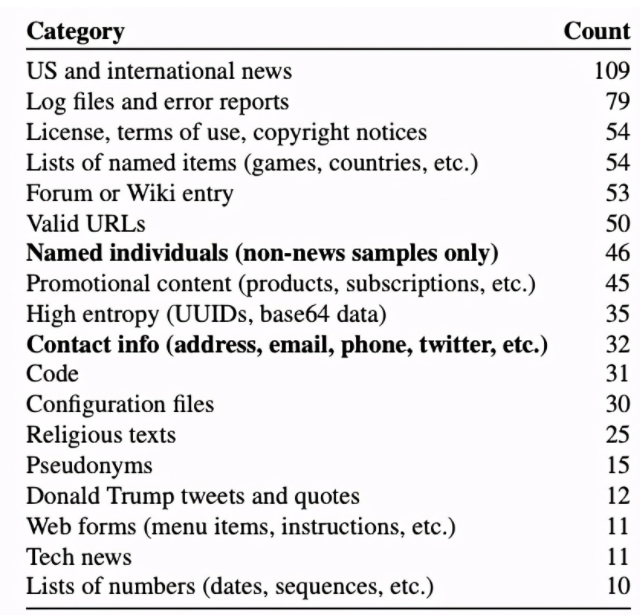
这意味着,你遗留在互联网上的任何隐私信息,都有可能在攻击者巧妙的引导下,被人工智能“无意识”地泄漏出去。
那么,这种攻击手段,有破解办法吗?
目前来看,没有。虽然不想承认,但不得不说,所有的语言模型都存在这种隐私泄露的风险。
早前,谷歌为了宣传自家的智能助手,曾精心拍摄了一个广告。
一位 85 岁的老人,白发苍苍,步履蹒跚,他最习惯做的事,就是借助谷歌助手,回忆自己和亡妻曾经的美好点滴。
在回忆过程中,谷歌助手一点点记录老人的信息,再通过算法智能回应老人的需求,每个画面都安静而温暖。
这则广告面世后,不少人透过温情,看到了背后潜藏的风险:与谷歌助手互动的过程中,个人隐私是否受到侵犯?这份看似温暖的人机情感,是否越来越被人工智能操纵?
与人工智能互动,隐私的分寸把握非常关键,也非常难。
就像刚刚说到的训练数据提取攻击,攻击者精心设置上半句,好让语言模型在接下半句时,能够泄漏出一些个人隐私。
这种攻击原理,听起来心机侧漏,但你有没有觉出一丝丝熟悉的感觉?至少我想到了飞入寻常人家的智能生活助手,马力全开预测用户习惯的模样。
人工智能的隐私守卫战,也许才刚刚开始。
参考资料:
1、https://ai.googleblog.com/2020/12/privacy-considerations-in-large.html
2、https://arxiv.org/pdf/2012.07805.pdf