












如果你正在 pytorch 中训练深度学习模型,那么如何能够加快模型训练速度呢?
在本文中,我会介绍一些改动最小、影响最大的在pytorch中加速深度学习模型的方法。对于每种方法,我会对其思路进行简要介绍,然后预估提升速度并讨论其限制。我会把我认为重要的部分强调介绍,并在每个部分展示一些实例。接下来我将假设你正在使用GPU训练模型,这些方法基本不需要导入其他的库,只需要再pytorch内进行更改即可。
以下是我根据预估的加速效果对不同方法的排序:
- 考虑使用其他的学习率调整计划
- 在DataLoader中使用多个辅助进程并页锁定内存
- 最大化batch大小
- 使用自动混合精度AMP
- 考虑不同的优化器
- 打开cudNN基准
- 当心CPU与GPU之间的数据传输
- 使用梯度/激活检查点
- 使用梯度累积
- 多GPU分布式训练
- 将梯度设置为None而不是0
- 使用.as_tensor()而不是.tensor()
- 只在需要的时候打开debugging模式
- 使用梯度裁剪
- 在BatchNorm之前忽略偏差
- 验证时关闭梯度计算
- 规范化输入和批处理
1. 考虑使用其他的学习率调整计划
在训练中使用的学习率调整计划会极大影响收敛速率以及模型泛化能力。
Leslie N. Smith 提出了循环学习率和1Cycle 学习率方法,然后由 fast.ai 的 Jeremy Howard 和 Sylvain Gugger 推广了。总的来说,1Cycle 学习速率方法如下图所示:
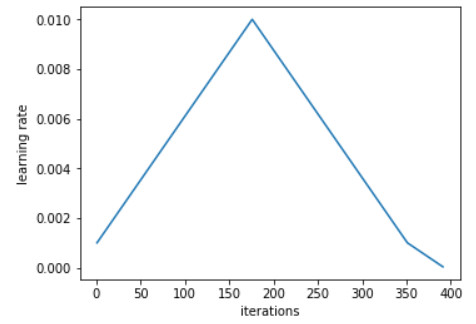
在最好的情况下,与传统的学习率策略相比,这种策略可以实现巨大的加速—— Smith称之为“超级收敛”。例如,使用1Cycle策略,在ImageNet上减少了ResNet-56训练迭代数的10倍,就可以匹配原始论文的性能。该策略似乎在通用架构和优化器之间运行得很好。
PyTorch提供了 torch.optim.lr_scheduler.CyclicLR 和 torch.optim.lr_scheduler.OneCycleLR 两种方法实现该操作,请参阅相关文档。
这两个方法的一个缺点是引入了许多额外的超参数。这篇文章和仓库对如何查找好的超参数(包括上文提及的学习率)提供了详细概述和实现。
至于为什么要这样做?现今并不完全清楚,但一个可能的解释是:定期提高学习率有助于更快越过损失鞍点。
2. 在DataLoader中使用多个辅助进程并页锁定内存
在使用 torch.utils.data.DataLoader时,令 num_workers > 0,而不是默认值 0,同时设置 pin_memory=True,而不是默认值 False。至于为什么这么做,这篇文章会给你答案。
根据上述方法,Szymon Micacz 在四个 worker 和页锁定内存的情况下,在单个epoch中实现了 2 倍加速。
根据经验,一般将进程数量设置为可用 GPU 数量的四倍,大于或小于这个值都会降低训练速度。但是要注意,增加num_workers会增加 CPU 内存消耗。
3.最大化batch大小
一直以来,人们对于调大batch没有定论。一般来说,在GPU内存允许的情况下增大batch将会增快训练速度,但同时还需要调整学习率等其他超参数。根据经验,batch大小加倍时,学习率也相应加倍。
OpenAI 的论文表明不同的batch大小收敛周期不同。Daniel Huynh用不同的batch大小进行了一些实验(使用上述1Cycle 策略),实验中他将 batch大小由64增加到512,实现了4倍加速。
然而也要注意,较大的batch会降低模型泛化能力,反之亦然。
4. 使用自动混合精度AMP
PyTorch1.6支持本地自动混合精度训练。与单精度 (FP32) 相比,一些运算在不损失准确率的情况下,使用半精度 (FP16)速度更快。AMP能够自动决定应该以哪种精度执行哪种运算,这样既可以加快训练速度,又减少了内存占用。
AMP的使用如下所示:
import torch# Creates once at the beginning of trainingscaler = torch.cuda.amp.GradScaler()for data, label in data_iter:
optimizer.zero_grad()
# Casts operations to mixed precision
with torch.cuda.amp.autocast():
loss = model(data)
# Scales the loss, and calls backward()
# to create scaled gradients
scaler.scale(loss).backward()
# Unscales gradients and calls
# or skips optimizer.step()
scaler.step(optimizer)
# Updates the scale for next iteration
scaler.update()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
Huang及其同事在NVIDIA V100 GPU上对一些常用语言和视觉模型进行了基准测试,发现在FP32训练中使用AMP提高约2倍的训练速度,最高甚至达到5.5倍。
目前,只有CUDA支持上述方式,查看本文档了解更多信息。
5. 考虑不同的优化器
AdamW是由fast.ai提出的具有权重衰减(而非 L2 正则化)的Adam, PyTorch中通过torch.optim.AdamW实现。在误差和训练时间上,AdamW都优于Adam。查看此文章了解为什么权重衰减使得Adam产生更好效果。
Adam和AdamW都很适合前文提到的1Cycle策略。
此外,LARS和LAMB等其他优化器也收到广泛关注。
NVIDA的APEX对Adam等常见优化器进行优化融合,相比PyTorch中的原始Adam,由于避免了GPU内存之间的多次传递,训练速度提升约 5%。
6. 打开cudNN基准
如果你的模型架构时固定的,同时输入大小保持不变,那么设置torch.backends.cudnn.benchmark = True可能会提升模型速度(帮助文档)。通过启用cudNN自动调节器,可以在cudNN中对多种计算卷积的方法进行基准测试,然后选择最快的方法。
至于提速效果,Szymon Migacz在前向卷积时提速70%,在同时向前和后向卷积时提升了27%。
注意,如果你想要根据上述方法最大化批大小,该自动调整可能会非常耗时。
7. 当心CPU与GPU之间的数据传输
通过tensor.cpu()可以将张量从GPU传输到CPU,反之使用tensor.cuda(),但这样的数据转化代价较高。 .item()和.numpy()的使用也是如此,建议使用.detach()。
如果要创建新的张量,使用关键字参数device=torch.device('cuda:0')将其直接分配给GPU。
最好使用.to(non_blocking=True)传输数据,确保传输后没有任何同步点即可。
另外Santosh Gupta的SpeedTorch也值得一试,尽管其加速与否尚不完全清除。
8.使用梯度/激活检查点
检查点通过将计算保存到内存来工作。检查点在反向传播算法过程中并不保存计算图的中间激活,而是在反向传播时重新计算,其可用于模型的任何部分。
具体来说,在前向传播中,function以torch.no_grad()方式运行,不存储任何中间激活。相反,前向传递将保存输入元组和function参数。在反向传播时,检索保存的输入和function,并再次对function进行正向传播,记录中间激活,并使用这些激活值计算梯度。
因此,对于特定的批处理大小,这可能会稍微增加运行时间,但会显着减少内存消耗。反过来,你可以进一步增加批处理大小,从而更好地利用GPU。
虽然检查点可以通过torch.utils.checkpoint方便实现,但仍需要里哦阿姐其思想与本质。Priya Goyal的教程很清晰的演示了检查点的一些关键思想,推荐阅读。
9.使用梯度累积
增加批处理大小的另一种方法是在调用Optimizer.step()之对多个.backward()传递梯度进行累积。
根据Hugging Face的Thomas Wolf发表的文章,可以按以下方式实现梯度累积:
model.zero_grad() # Reset gradients tensors for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
model.zero_grad() # Reset gradients tensors
if (i+1) % evaluation_steps == 0: # Evaluate the model when we...
evaluate_model() # ...have no gradients accumulated
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
该方法主要是为了规避GPU内存的限制,但对其他.backward()循环之间的取舍我并不清楚。fastai论坛上的讨论似乎表明它实际上是可以加速训练的,因此值得一试。详情查看GitHub托管的rawgradient_accumulation.py。
10.多GPU分布式训练
通过分布式训练加快模型速度的一种简单的方法是使用torch.nn.DistributedDataParallel而不是torch.nn.DataParallel。这样,每个GPU将由专用的CPU内核驱动,从而避免了DataParallel的GIL问题。
强烈推荐阅读分布式训练相关文档了解更多信息:
PyTorch Distributed Overview — PyTorch Tutorials 1.7.0 documentation
- 1.
11.将梯度设置为None而不是0
设置.zero_grad(set_to_none=True)而不是.zero_grad()。
这样内存分配器处理梯度而不是主动将其设置为0,这会产生该文档所示的适度加速,但不要抱有过大期望。
注意,这样做不会有任何副作用!阅读文档查看更多信息。
12.使用.as_tensor()而不是.tensor()
torch.tensor()本质是复制数据,因此,如果要转换numpy数组,使用torch.as_tensor()或torch.from_numpy()可以避免复制数据。
13.只在需要的时候打开debugging模式
Pytorch提供了许多调试工具,例如autograd.profiler, autograd.grad_check和autograd.anomaly_detection。使用时一定要谨慎,这些调试工具显然会影响训练速度,因此在不需要时将其关闭。
14.使用梯度裁剪
为了避免RNN中的梯度爆炸,使用梯度裁剪gradient = min(gradient, threshold)可以起到加速收敛作用,这一方法已得到理论和实验的支持。
Hugging Face的Transformer提供了将梯度裁剪和AMP等其他方法有效结合的清晰示例。
在PyTorch中,也可使用torch.nn.utils.clip_grad_norm_(文档查阅)完成此操作。
虽然我尚不完全清楚哪种模型可以从梯度裁剪中受益,但毫无疑问的是,对于RNN、基于Transformer和ResNets结构的一系列优化器来说,该方法显然是起到一定作用的。
15.在BatchNorm之前忽略偏差
在BatchNormalization层之前关闭之前层的偏差时一种简单有效的方法。对于二维卷积层,可以通过将bias关键字设置为False实现,即torch.nn.Conv2d(..., bias=False, ...)。阅读该文档了解其原理。
与其他方法相比,该方法的速度提升是有的。
16. 验证时关闭梯度计算
在模型验证时令torch.no_grad()
17. 规范化输入和批处理
也许你已经在这样做了,但还是要仔细检查,反复确认:
- 是否规范化输入?
- 是否规范化批处理?
其他技巧:使用JIT实现逐点融合
如果要执行相邻逐点操作,可以使用PyTorch JIT将它们组合成一个FusionGroup,然后在单内核上启动,而不是像默认情况那样在多个内核上启动,同时还可以保存一些内存进行读写。
Szymon Migacz展示了如何使用@torch.jit.script装饰器融合GELU操作融合,如下:
@torch.jit.scriptdef fused_gelu(x): return x * 0.5 * (1.0 + torch.erf(x / 1.41421))
- 1.
相比于未融合版本,融合这些操作可以使fused_gelu的执行速度提高5倍。
本文转自雷锋网,如需转载请至雷锋网官网申请授权。























