网络攻防是一个比较大的话题,比如端口扫描、SQL Injection扫描、数据包嗅探、网络密码猜解、后门、木马等知识的基础技术。这些技术在入侵剖析中是比较常见的技术。
在学习扫描器、嗅探器、木马等知识之前,首先必须学习网络编程的基础知识,网络编程的基础是深入学习网络的起步,没有基础知识,扫描、嗅探都是空谈。
01 网络基础知识
各计算机之间通过互联网进行通信主要依赖TCP/IP。该协议是一个4层协议,由上至下分别是应用层、传输层、网际层和链路层。TCP/IP的下层协议总是为上层协议服务,下层协议的细节对于上层协议来说是透明的。分层设计的好处是,每一层的功能比较明确,而且修改某一层的实现不会影响其他层。TCP/IP在每层协议中都定义了非常多的不同的协议,比如网际层的协议ICMP、IGMP等,传输层的TCP、UDP等。在众多协议中,最具代表性的协议是TCP和IP,因此,互联网协议被称为TCP/IP族(千万别认为TCP和IP就是互联网协议的全部)。
IP协议是“Internet Protocol”的简称,它是为计算机网络相互连接进行通信而设计的协议。在IP协议中最重要的就是IP地址,IP地址是用来在网络上唯一标识计算机主机的地址。互联网中没有两个机器有相同的IP地址,因此它是用来标识一台网络主机的。所有的IP地址都是32位长,它用点分十进制法来表示,比如“10.10.30.12”。IP地址指定的不是主机,而是网络接口设备。因此,一台主机有两个网络接口,那么就会有两个IP地址。通常情况下,对于一台普通主机只有一个网络接口设备,也就只有一个IP地址,比如个人使用的PC通常只有一个IP地址;而对于服务器或者网络设备(交换机、路由器等)来说,则会有多个网络接口设备,每个网络接口设备都会有一个IP地址,那么对于路由器这种网络设备来说就会有多个IP地址。
IP地址被分为5类,分别是A类、B类、C类、D类和E类。各类IP地址的范围如表1所示。
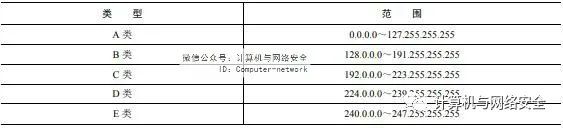
表1 各类IP地址的范围
IP工作在TCP/IP 4层协议的“网际层”,网际层最主要的工作是将数据包进行路由。这里所说IP是一种被路由协议,也就是在进行路由的过程中,IP协议会被路由协议用到。真正进行数据包选路的协议(其实就是路由的算法,数据包如何进行转发的算法)被称为路由协议,具体的路由协议有RIP、OSPF、BGP等。对于入门而言,只要了解了IP地址是什么,IP地址的作用是什么即可。
传输层主要有两大协议,分别是TCP协议和UDP协议。
TCP是“Transmission Control Protocol”的简称,其意思为传输控制协议。TCP是一种面向连接的、可靠的通信协议。TCP协议是IP协议的上层协议,IP服务于TCP。
UDP是“User Datagram Protocol”的简称,其意思为用户数据报协议。UDP是一种无连接的传输层协议,提供面向事务的简单不可靠信息传送服务。
传输层是为应用层提供服务的,应用层的协议一部分是基于TCP的,比如FTP、HTTP,而一部分是基于UDP的,比如DNS。IP层提供了IP地址用来标识网络主机,而传输层提供了端口用来标识主机中的进程。确定了IP地址和端口号,就确定了网络上的主机及主机上通信的进程。
传输层提供了标识通信进程的端口号。按照协议划分,端口分为TCP端口和UDP端口,TCP端口和UDP端口各有65536个。对于应用程序而言,一般使用大于1024的端口号,因为小于1024的端口号属于保留端口。Internet上的很多服务都是用了小于1024的端口号。为了避免冲突,程序员自己编写的应用程序不要使用小于1024的端口号。同一协议的端口不能冲突,比如Web服务器占用了主机TCP的80端口,那么另外的程序就不可以再使用TCP的80端口。常用的端口号如表2所示。
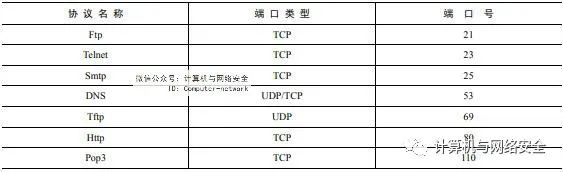
表2 常用端口号举例
除了小于1024的端口号外,还有一些比较知名的端口号,比如MS SQL Server的端口号是1433,Windows的远程桌面端口号是3389等。程序员在编写自己的网络应用程序时,要避免与这些常用的端口冲突。
02 面向连接协议与非面向连接协议所使用的函数
1. 面向连接的协议
在面向连接的协议中,两台计算机之间在进行数据收发前,必须先在两者之间建立一个通信信道,以确保两台计算机之间存在一条路径可以互相沟通。在数据传输完毕后,切断这条通信信道。该种方式相当于打电话,用户在手机上拨10086,当客服人员接听后,用户就可以开始通话,通话完毕后就可以挂电话了。
面向连接的协议使用的是TCP,服务器与客户端建立通信信道所需要的基本Winsock函数如下。
服务器端函数:
- socket()->bind()->listen()->accept()->send()/recv()->closesocket()
客户端函数:
- socket()->connet()->send()/recv()->closesocket()
2. 非面向连接的协议
在非面向连接的协议中,发送端只要直接将要发送的数据传出即可,不需要理会接收端是否能够收到数据。而接收端在接收到数据时,也不会响应信息通知发送给发送端。该种方式就相当于写信,将写好的信放到信箱中,但是却不能保证收信人真的能够收到这封信件。
非面向连接的协议使用的是UDP,服务器与客户端通信所需要的基本Winsock函数如下:
服务器端函数:
- socket()->bind()->sendto()/recvfrom()->closesocket()
客户端函数:
- socket()->sendto()/recvfrom()->closesocket()
03 Winsock网络编程知识
Winsock是Windows下网络编程的基础,下面介绍Winsock的常用函数。
1. Winsock的初始化与释放
在使用Winsock相关函数时需要对Winsock库进行初始化,而在使用完成后需要对Winsock库进行释放。完成Winsock库的初始化和释放的函数如下。
Winsock库的初始化函数的定义:
- int WSAStartup(WORD wVersionRequested, LPWSADATA lpWSAData);
该函数的第1个参数wVersionRequested是需要初始化Winsock库的版本号。第2个参数lpWSAData是一个指向WSADATA的指针。该函数的返回值为0,说明函数调用成功。如果函数调用失败,则返回其他值。在程序的开始处调用该初始化函数,在程序中就可以使用Winsock相关的所有API函数。
Winsock库的释放函数的定义:
- int WSACleanup (void);
该函数没有参数,在程序的结束处直接调用该函数,即可释放Winsock库。
初始化与释放Winsock库的代码示例如下:
- WORD wVersionRequested;
- WSADATA wsaData;
- int err;
- wVersionRequested = MAKEWORD( 2, 2 );
- err = WSAStartup( wVersionRequested, &wsaData );
- if ( err != 0 )
- {
- return -1;
- }
- if ( LOBYTE( wsaData.wVersion ) != 2 ||
- HIBYTE( wsaData.wVersion ) != 2 )
- {
- WSACleanup( );
- return -1;
- }
- // ……
- WSACleanup();
2. 套接字的创建与关闭
套接字用于根据指定的协议类型来分配一个套接字描述符。该描述符主要用在客户端和服务器端进行通信连接,当套接字使用完毕时应该关闭套接字以释放资源。创建套接字与关闭套接字的函数为socket()和closesocket()。
创建套接字的函数定义如下:
- SOCKET socket(int af, int type, int protocol);
socket()函数共有3个参数,第1个参数af用来指定地址族,在Windows下可以使用的参数值有多个,但是真正可以使用的只有两个,分别是AF_INET和PF_INET。这两个宏在Winsock2.h下的定义是相同的,分别如下:
- #define AF_INET 2 /* internetwork: UDP, TCP, etc. */
- /*
- * Protocol families, same as address families for now.
- */
- #define PF_INET AF_INET
以上两个定义都摘自Winsock2.h头文件。从定义中可以看出,PF_INET和AF_INET是相同的。看PF_INET宏定义上面的注释,AF表示地址族(Address Family),而PF表示协议族(Protocol Family)。对于Windows来说,两者相同;对于Unix/Linux来说,两者是不相同的。一般情况下,在调用socket()函数时应该使用PF_INET,而在设置地址时使用AF_INET。FP_INET上面的那句注释,同样也是出自Winsock2.h头文件中。“Protocol families,same as address families for now.”,也就是说,目前PF和AF是相同的。注释中说目前是相同的,可能这样定义是为以后预留的,为了保持良好的兼容性。调用socket()函数时,应该使用PF_INET宏,而尽量避免或不去使用AF_INET宏。
socket()函数的第 2 个参数 type 是指定新套接字描述符的类型。这里可以使用的值通常有3个,分别是 SOCK_STREAM、SOCK_DGRAM 和 SOCK_RAW,分别表示流套接字、数据包套接字和原始协议接口。
socket()函数的第 3 个参数 protocol 用来指定应用程序所使用的通信协议,这里可以选择使用 IPPROTO_TCP、IPPROTO_UDP、IPPROTO_ICMP 等协议,这个参数的值根据第 2 个参数的值进行选择。第2 个参数如果使用SOCK_STREAM,那么第3 个参数应该使用IPPROTO_TCP;如果第 3 个参数使用了 SOCK_DGRAM,那么第 3 个参数应该使用 IPPROTO_UDP。为了书写简单,如果第 2 个参数是 SOCK_STREAM 或 SOCK_DGRAM,那么第 3 个参数可以默认为 0。如果第 2 个参数指定的是 SOCK_RAW,那么第 3 个参数就必须指定,而不能使用 0 值。
socket()函数调用成功返回值为一个新的套接字描述符,如果调用失败,则返回 INVALID_SOCKET。调用失败后,想要知道调用失败的原因,那么紧接着调用 WSAGetLastError()函数得到错误码。
所有的Winsock函数出错后,都可以调用WSAGetLastError()函数得到错误码,但是WSAStartup()不能通过WSAGetLastError()得到错误码,因为WSAStartup()未调用成功,不能调用WSAGetLastError()函数。
关闭套接字的函数定义如下:
- int closesocket(SOCKET s);
closesocket()函数的参数是 socket()函数创建的套接字描述符。
对于WSAStartup()/WSACleanup()和socket()/closesocket()这样的函数,最好保持成对出现。也就是说,在写完一个函数时,立刻写出另外一个函数的调用,以免忘记资源的释放。
3. 面向连接协议的函数
bind()、listen()、accept()、connect()、send()和recv(),这些函数是常用的面向连接的函数,它们都是Winsock面向连接的最基本的函数。下面介绍几个函数的使用方法。
通过socket()函数可以创建一个新的套接字描述符,但是它只是一个描述符,它为网络的一些资源做准备。要真正在网络上进行通信,需要本地的地址与本地的端口号信息。当然,本地地址与端口号信息要去套接字描述符进行关联进行绑定。在Winsock函数中,使用bind()函数完成套接字与地址端口信息的绑定。bind()函数的定义如下:
- int bind(SOCKET s, const struct sockaddr FAR *name, int namelen);
该函数有3个参数,第1个参数s是新创建的套接字描述符,也就是用socket()函数创建的描述符,第2个参数name是一个sockaddr的结构体,提供套接字一个地址和端口信息,第3个参数namelen是sockaddr结构体的大小。
其中第2个参数中的sockaddr结构体定义如下:
- struct sockaddr {
- u_short sa_family;
- char sa_data[14];
- };
该结构体共有16字节,在该结构体之前所使用的结构体为sockaddr_in,该结构体的定义如下:
- struct sockaddr_in {
- short sin_family;
- u_short sin_port;
- struct in_addr sin_addr;
- char sin_zero[8];
- };
sockaddr结构体是为了保持各个特定协议之间的结构体兼容性而设计的。为bind()函数指定地址和端口时,向sockaddr_in结构体填充相应的内容,而调用函数时应该使用sockaddr结构体。
在sockaddr_in结构体中,还有一个结构体in_addr,该结构体在winsock2.h中的定义如下:
- struct in_addr {
- union {
- struct { u_char s_b1,s_b2,s_b3,s_b4; } S_un_b;
- struct { u_short s_w1,s_w2; } S_un_w;
- u_long S_addr;
- } S_un;
- };
该结构体中是一个共用体S_un,包含两个结构体变量和1个u_long类型变量。一般使用的IP地址是使用点分十进制表示的,而in_addr结构体中却没有提供用来保存点分十进制表示IP地址的数据类型,这时需要使用转换函数,把点分十进制表示的IP地址转换成in_addr结构体可以接受的类型。这里使用的转换函数是inet_addr(),该函数的定义如下:
- unsigned long inet_addr(const char FAR *cp);
该函数是将点分十进制表示IP地址转换成unsigned long类型的数值。该函数的参数cp是指向点分十进制IP地址的字符指针。同时该函数有一个逆函数,是将unsigned long型的数值型IP地址转换为点分十进制的IP地址字符串,该函数的定义如下:
- char FAR * inet_ntoa(struct in_addr in);
sockaddr_in 结构体中的 sin_port 表示端口,这个端口需要使用大尾方式字节序存储(大尾方式和小尾方式是两种不同的存储方式)。在 Intel X86 架构下,数值存储方式默认都是小尾方式字节序,而 TCP/IP 的数值存储方式都是大尾方式的字节序。为了实现方便的转换,winsock2.h中提供了方便的函数,即 htons()和 htonl()两个函数,并且提供了它们的逆函数 ntohs()和 ntohl()。
htons()和 htonl()函数的定义分别如下:
- u_short htons(u_short hostshort);
- u_long htonl(u_long hostlong);
ntohs()和 ntohl()函数的定义分别如下:
- u_short ntohs(u_short netshort);
- u_long ntohl(u_long netlong);
这4个函数中,前两个函数是将主机字节序转换为网络字节序(host to network),后两个函数是将网络字节序转换为主机字节序(network to host)。在有些架构系统下,主机字节序和网络字节序是相同的,那样转换函数不进行任何转换,但是为了代码的移植性,还是会进行转换函数的调用。
具体bind()函数的使用方法如下:
- // 创建套接字
- SOCKET sLisent = socket(PF_INET, SOCK_STREAM, IPPROTO_TCP);
- // 对 sockaddr_in 结构体填充地址、端口等信息
- struct sockaddr_in ServerAddr;
- ServerAddr.sin_family = AF_INET;
- ServerAddr.sin_addr.S_un.S_addr = inet_addr("10.10.30.12");
- ServerAddr.sin_port = htons(1234);
- // 绑定套接字与地址信息
- bind(sLisent, (SOCKADDR *)&ServerAddr, sizeof(ServerAddr));
对于服务器端的地址可以指定为INADDR_ANY宏,表示“任意地址”或“所有地址”。当客户端发起连接时,服务器操作系统接收到客户端的连接,根据网络的配置情况会自动选择一个IP地址和客户端进行通信。
当套接字与地址端口信息绑定以后,就需要让端口进行监听,当端口处于监听状态以后就可以接受其他主机的连接了。监听端口和接受连接请求的函数分别为listen()和accept()。
监听端口的函数定义如下:
- int listen(SOCKET s, int backlog);
该函数有两个参数,第1个参数s是指定要监听的套接字描述符,第2个参数backlog是允许进入请求连接队列的个数,backlog的最大值由系统指定,在winsock2.h中,其最大值由SOMAXCONN表示,该值的定义如下:
- #define SOMAXCONN 0x7fffffff
接受连接请求的函数定义如下:
- SOCKET accept(SOCKET s, struct sockaddr FAR *addr, int FAR *addrlen);
该函数从连接请求队列中获得连接信息,创建新的套接字描述符,获取客户端地址。新创建的套接字用于和客户端进行通信,在服务器和客户端通信完成后,该套接字也需要使用closesocket()函数进行关闭,以释放相应的资源。该函数有3个参数,第1个参数s是处于监听的套接字描述符,第2个参数addr是一个指向sockaddr结构体的指针,用来返回客户端的地址信息,第3个参数addrlen是一个指向int型的指针变量,用来传入sockaddr结构体的大小。
上面介绍的是面向连接的服务器端的函数,完成了一系列服务器应有的基本的动作,具体如下。
① bind()函数将套接字描述符与地址信息进行绑定。
② listen()函数将绑定过套接字描述符置于监听状态。
③ accept()函数获取连接队列中的连接信息,创建新的套接字描述符,以便与客户端通信。
面向连接的客户端只需要完成与服务器的连接这样一个动作就可以实现和服务器端的通信了。创建套接字描述符后,使用connect()函数就可以完成与服务器的连接。
connect()函数的定义如下:
- int connect(SOCKET s, const struct sockaddr FAR *name, int namelen);
该函数的作用是将套接字进行连接。该函数有3个参数,第1个参数s表示创建好的套接字描述符,第2个参数name是指向sockaddr结构体的指针,sockaddr结构体中保存了服务器的IP地址和端口号,第3个参数namelen是指定sockaddr结构体的长度。
当客户端使用connect()函数与服务器连接后,客户端和服务器就可以进行通信了。通信时主要就是信息的发送和信息的接收。这里介绍的函数有两个,分别是send()和recv()。
发送函数send()的定义如下:
- int send(SOCKET s, const char FAR *buf, int len, int flags);
该函数有4个参数,第1个参数s是套接字描述符,该套接字描述符对于服务器端而言,使用的是accept()函数返回的套接字描述符,对于客户端而言,使用的是socket()函数创建的套接字描述符,第2个参数buf是发送消息的缓冲区,第3个参数len是缓冲区的长度,第4个参数flags通常赋为0值。
接收函数recv()的定义如下:
- int recv(SOCKET s, char FAR *buf, int len, int flags);
该函数有4个参数。该函数的使用方法与send()函数的使用方法相同,这里不再进行介绍。
从send()和recv()两个函数的名称来看分别是发送和接受的意思,但是实际上对于数据的发送和接收依靠的是网络协议来完成的,send()函数和recv()函数只是完成了将数据从网络协议所使用的缓冲区中进行拷贝的一个动作。
4. 非面向连接协议的函数
在面向连接的TCP中,服务器端将套接字描述符与地址进行绑定后,需要将端口进行监听,等待接受客户端的连接请求,而在客户端则需要连接服务器,完成这些步骤就可以保证面向连接的TCP的可靠传输,在调用connect()函数的过程中也完成了TCP的“三次握手”的过程。非面向连接的UDP协议在开发上基本与面向连接TCP的协议相同。在非面向连接的UDP开发中,服务器端不需要对端口进行监听,也就不需要等待接受客户端的连接请求,而客户端也不需要完成与服务器端的连接。中间的“三次握手”过程也就省略了,这样UDP相对于TCP来讲就显得不可靠了,但是在效率方面却要快于TCP。
在非面向连接协议开发中,服务器端不再需要调用listen()、accept()函数,客户端不再需要调用connect()函数。而服务器和客户端的通信函数使用sendto()和recvfrom()函数即可。
sendto()函数的定义如下:
- int sendto(
- SOCKET s,
- const char FAR *buf,
- int len,
- int flags,
- const struct sockaddr FAR *to,
- int tolen
- );
该函数是来用在UDP通信双方进行发送数据的函数,该函数有6个参数,第1个参数s是套接字描述符,第2个参数buf是要发送数据的缓冲区,第3个参数len是指定第2个参数的长度,第4个参数通常赋0值,第5个参数to是一个指向sockaddr结构体的指针,这里给出接收消息的地址信息,第6个参数tolen是指定第5个参数的长度。
recvfrom()函数的定义如下:
- int recvfrom(
- SOCKET s,
- char FAR* buf,
- int len,
- int flags,
- struct sockaddr FAR *from,
- int FAR *fromlen
- );
该函数是用来在UDP通信双方进行接收数据的函数。该函数的用法与sendto()相同,这里不再进行介绍。
sendto()函数和recvfrom()函数的功能与send()函数和recv()函数类似,它们都是用于向网络协议缓冲区进行数据复制的函数,并不是真正的去完成数据的发送和接收的。
04 字节顺序
字节序的存在是由于不同架构CPU在访问数据时所采取的顺序不同,在计算机内存中对数值的存储有一定的标准,而该标准随着系统架构的不同而不同。了解字节存储顺序对于逆向工程是一项基础的知识,在动态分析程序的时候,往往需要观察内存数据的变化情况,如果不了解字节存储顺序,那么可能会迷失在内存的汪洋大海中而无法继续逆向航行。
1. 字节序基础
通常情况下,数值在内存中存储的方式有两种,一种是大尾方式(大尾字节序就是网络字节序),另一种是小尾方式。
先来看一个简单的例子,比如0x01020304这样一个数值,如果用大尾方式存储,其存储方式为01 02 03 04,而用小尾方式存储则是04 03 02 01。这样表示也许不直观,用表格的形式展示其具体的区别,如表3所示。
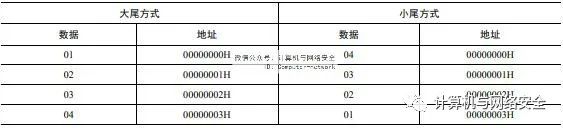
表3 字节顺序的对比表
从表中可以得到如下结论。
大尾存储方式:内存高位地址存放数据低位字节数据,内存低位地址存放数据高位字节数据;
小尾存储方式:内存高位地址存放数据高位字节数据,内存低位地址存放数据低位字节数据。
2. 主机字节序与网络字节序
主机字节序与网络字节序是相对的概念。
所谓主机字节序,是指主机在存储数据时的字节顺序,主机字节序根据系统架构的不同而不同。通常情况下,Windows操作系统兼容的CPU为小尾方式,而UNIX操作系统所兼容的CPU多为大尾方式。因此,主机字节序并非固定的字节序,需要根据不同的系统架构进行确定。
所谓网络字节序,是指网络传输相关协议所规定的字节传输顺序,TCP/IP所使用的字节序为大尾方式。
3. 字节序相关函数
涉及字节序常用的相关函数有htons()、htonl()、ntohs()和ntohl()。这4个函数的定义分别如下:
- u_short htons(u_short hostshort);
- u_long htonl(u_long hostlong);
- u_short ntohs(u_short netshort);
- u_long ntohl(u_long netlong);
在Windows下,使用以上4个转换函数会改变值的大小,因为其在内存中的存放方式改变了。如果在UNIX系统下,使用以上4个转换函数是不会发生任何改变的。无论是何种系统,在进行网络开始时都需要调用这些函数进行转换,因为这样做可以有效的保证在网络中传输的确实是网络字节序。
4. 编程判断主机字节序
“编程判断主机字节序”是很多杀毒软件公司或者是安全开发职位的一道面试题,因为这题比较基础。这里给出对于该题目的实现方法。完成该题目有两种方法,第1种方法是“取值比较法”,第2种方法是“直接转换比较法”。
方法一:取值比较法
所谓取值比较法,首先定义一个4字节的十六进制数。因为使用调试器查看内存最直观的就是十六进制值,所以定义十六进制数是一个操作起来比较直观的方法。而后通过指针方式取出这个十六进制数在“内存”中的某一字节,最后和实际数值中相对应的数进行比较。由于字节序的问题,内存中的某字节与实际数值中对应的字节可能不同,这样就可以确定字节序了。
代码如下:
- int main(int argc, char* argv[])
- {
- DWORD dwSmallNum = 0x01020304;
- if ( *(BYTE *)&dwSmallNum == 0x04 )
- {
- printf("Small Sequence. \r\n");
- }
- else
- {
- printf("Big Sequence. \r\n");
- }
- return 0;
- }
以上代码中,定义了0x01020304这个十六进制数,其在小尾方式内存中的存储顺序为04 03 02 01。取*(BYTE *)&dwSmallNum内存中低地址位的值,如果是小尾方式的话,那么低地址位存储的值为0x04,如果是大尾方式则为0x01。
方法二:直接转换比较法
所谓直接转换比较法,是利用字节序转换函数将所定义的值进行转换,然后用转换后的值和原值进行比较。如果原值与转换后的值相同,说明为大尾方式,否则为小尾方式。
代码如下:
- int main(int argc, char* argv[])
- {
- DWORD dwSmallNum = 0x01020304;
- if ( dwSmallNum == htonl(dwSmallNum) )
- {
- printf("Big Sequence. \r\n");
- }
- else
- {
- printf("Small Sequence. \r\n");
- }
- return 0;
- }
这种方法比较直接,如果转换后的结果与原值相等,就说明是大尾方式,因为转换后的结果是网络字节序,网络字节序等同于大尾方式。
关于字节序的内容大家一定要自行调试体会一下,因为在网络开发中只需要进行简单的转换即可,不需要过多的关心它的细节。而如果是做逆向工程时,在内存中要进行数据的查找时,这时字节序的知识会使用到了。