随着 Web 项目日趋复杂,除了不断还原 UI 稿、搞好各端与各机型兼容外,如何解决用户在访问页面时实际遇到的各种“疑难杂症”,逐渐成为开发者需要面临的问题之一。
传统手段上,我们有各式各样的埋点方案,无痕埋点、全链路监控、用户行为上报、接口状态监控等等,但这些都是针对真实用户行为以及表现的采样,遇到问题时他们并不一定能发挥最大用处,很多时候还需要程序员的参与介入。有什么办法可以最完整的将用户问题展现在我们面前呢?无外乎我们可以完整、真实地重现用户当时的操作行为与结果,要是在用户端能安装一个随时随地的录屏软件就好了。

本文通过各类调研以及实际项目开发中总结的经验,以记录在实现前端监控回放系统的过程中会用到的一些 Web API 与新技术能力,为大家提供一些可行的实现思路。本文未涉及到的方面也欢迎评论告知补充。
本文结构如下:
- 实现方案思路
- 关键技术基础
- 应用与状态的序列化
- 记录 DOM 变化与交互的快照
- 回放重演
- 沙箱
- 技术项拆分与相关 Web API
- 结语
1 / 实现方案思路
要想给用户的访问做一次完整的应用状态监控录制与回放,除了录制视频外,通过 Web API 实现大致有两类主流的解决思路。
第一种方案是通过记录 DOM 的每次变更,并将内容序列化下来,然后在沙箱中还原并回放这些 UI 变化。这种方案的优点之一是能够给 DOM 创建快照的概念,在应用每一次状态变化后进行收集,把这个序列串起来后我们便可以灵活掌握回放速度、并针对关键性节点进行自定义回放。在社区开源方案中,这类技术最成熟的莫过于 rrweb https://github.com/rrweb-io/rrweb ,此外若干互联网企业也有提供一些商业解决方案,但技术设计上大同小异,大致都可以拆分为 DOM 序列化、构建快照序列、反序列化回放以及运行沙箱环境等四方面。
另一种可行方案,从我们的调研结果来看,是将用户侧所有数据收集起来,然后在一个可控运行环境下严格按照校准时间对用户事件操作进行派发,从而控制回放。这里主要分为两部分,一方面因为我们通过派发事件来重演用户的行为,便需要高精度计时器以及完善的用户事件收集策略;另一方面,由于要保证应用状态在两端的变化一致性,只严格触发用户的操作还不够,我们还要将任何应用与网络之前的交互操作(请求与响应内容)精准对齐,所以我们需要拦截所有请求、即时的前端构建产物以及用户操作序列等等。
第二种方案由于可以近乎模拟用户侧运行时的状态变化,相当于将当时的用户整个搬到了我们面前,因此可以方便开发同学进一步调试。在社区开源方案中,我们没有找到类似的实现,但商业方案中 https://logrocket.com/ 最接近这个思路,其提供的不少功能甚至比这里提及的功能要更强大。
但本文中,我们只讨论当需要实现这样一个系统时的涉及技术项。所以接下来,来看看我们在调研中记录的一些有用的 Web API,希望对你们实现有帮助。
2 / 关键技术基础
本章主要介绍要实现这样一个前端监控回放系统的四个环节,关于这些内容,rrweb 的描述篇幅会更加翔实,可以更进一步查阅他们的文档描述。
2.1 应用与状态的序列化
如何回放一个应用的状态变化?首先,我们要将应用的内容以及状态变化收集起来。如果用 jQuery 我们可以这样实现 body 内容的收集与替换:
- // record
- const snapshot = $('body').clone();
- // replay
- $('body').replaceWith(snapshot);
如果换用MediaRecorder API,利用 ondataavailable 和 onstop 两个事件处理 API,我们还可以将 DOM 转变成可播放的媒体文件,比如这样:
- startRecording() {
- const stream = (this.canvas as any).captureStream();
- this.recorder = new MediaRecorder(stream, { mimeType: 'video/webm' });
- const data = [];
- this.recorder.ondataavailable = (event) => {
- if (event.data && event.data.size) {
- data.push(event.data);
- }
- };
- this.recorder.onstop = () => {
- const url = URL.createObjectURL(new Blob(data, { type: 'video/webm' }));
- this.videoUrl$.next(
- this.sanitizer.bypassSecurityTrustUrl(url)
- );
- };
- this.recorder.start();
- this.recordVideo$.next(true);
- }
但这些内容是没法序列化的,而媒体体积又过于庞大且无法进一步分析。举个例子,一个 input 标签,如果我们不做任何额外处理只将其转化成文本进行存储(类似 innerHTML),那么其中包含的 value 等状态便会丢失,这便是我们首先需要将 DOM 及其视图状态进行序列化的原因所在。关于如何序列化 DOM 也有不少开源方案比如 https://github.com/inikulin/parse5 ,rrweb 在文档中有提到为什么没有采用的原因,而我这里简单列一下在序列化环节中需要考虑的几点细节:
- 如何将 DOM 树转化成一个带视图状态的树状结构,包括未反映在 HTML 中的视图状态;
- 如何定义唯一标识,方便应用状态变化(快照)的溯源;
- 如何处理特殊标签诸如 script 以及样式等内容,因方案而异;
简而言之,这部分的目的是完成一个 DOM 树至可存储状态的数据结构映射。
2.2 记录 DOM 变化与交互的快照
如果只是记录 DOM 变更的话,我们可以很方便的利用 MutationObserver API 达到变更监听与记录这一目的,但此外我们还需要考虑如何将 Mutation 的批量序列转化为快照上的增量更新。
比如,为了方便针对 Node 进行增删时可以唯一确定其在树形结构中的位置,我们最好设计一个合适的 DOM 唯一标记策略,此外,如何优化诸如 mousemove 以及大量频繁 input 输入导致的视图变更等。前者的设计可以继续用在增量快照的实现上,而后者的表现则直接影响用户体验,容易导致 DOM 在更改时 Node 记录的出现顺序错误。
这一环节,主要依赖 DOM 的序列化方案继续处理。在添加一些其他必要信息诸如时间序列编号等,便可以进行存储等操作了。
2.3 回放重演
简单来说,重演就是将收集到的数据按照顺序依次“播放”一遍,视频文件的播放需要音视频解码器,而我们的重演环节要做的工作就可以简单理解成一个 Web 应用解码器,从用户端收集上来的数据结构除了要做清洗和存储外,还不能直接被回放侧使用,其中有不少需要考虑的细节。
举个简单的例子,我们利用 Web API 是没法达到派发 hover 事件的,但是我们的项目中一定存在大量的 hover 样式,那么如何针对这些交互做额外处理,对 Node 状态变化做相应样式的补全,便成为一个需要考虑的环节结合 mousedown 和 mouseup 两个事件的触发时机是否够用?事件收集的挂载节点如何圈定?这些都是需要考虑的地方。再比如,回放中想跳过被认为无意义的操作片段,如何设计才能保持应用在前后两个时间节点上不因为跳过的操作而缺失视图状态?
这一环节,目的是为了实现对快照存储下来的数据结构进行回放。因为要保证回放侧与收集侧的严格一致,诸如高精度计时、DOM 补全以及交互效果模拟等细节,都需要详细设计。
2.4 沙箱
沙箱,是为了给回放提供一个安全可控的运行环境。如何采用 DOM 快照方案,那么便需要考虑如何禁止一些“不安全”的 DOM 操作。例如应用内链接跳转、我们不太可能会直接给用户打开一个新的 tab,为了保证快照状态依次回放,我们还需要考虑如何安全准确的反序列化构建 DOM。如果实现上考虑通过派发事件的思路来实现,那么如何准确定位派发的 Node 节点、如何匹配数据请求并响应等等都是需要重点考虑的。
两种思路都有一些需要共同考虑的事情,比如如何保证运行环境符合浏览器的安全限制、需要展示和用户操作保持一致的渲染层等等。这部分在技术项拆分一节,会提到两个解决方案,分别是 iframe 以及 puppeteer,此处不再赘述。
3 / 技术项拆分与相关 Web API
Web 有强大的 API List,本章节针对可能用到的 API 与相关技术做一一讲解。
3.1 MutationObserver
MutationObserver API 可以用于监听观察 DOM 对象的变化并予以记录数组的形式返回,这可以用在应用初始化和增量快照的记录部分。关于 MutationObserver 的方法与入参这里不做详细介绍,简单来看,要用 MutationObserver API 监听一个 Node 的变更大致分为这么几步:
- 利用 document.getElementById 等 API 定位你所需要的 Node
- 定义一个 MutationObserverInit 对象,此对象的配置项描述了 DOM 的哪些变化应该提供给当前观察者的回调函数
- 定义上述回调函数被调用时的执行逻辑
- 创建一个观察器实例并传入回调函数
- 调用 MutationObserver 的 observe() 方法开始观察
以下节选自 MDN 的一段示例代码用于释义:
- const targetNode = document.getElementById('some-id');
- const config = { attributes: true, childList: true, subtree: true };
- const callback = function(mutationsList, observer) {
- for(let mutation of mutationsList) {
- if (mutation.type === 'childList') {
- console.log('A child node has been added or removed.');
- }
- }
- };
- const observer = new MutationObserver(callback);
- observer.observe(targetNode, config);
3.2 iframe 标签
iframe 大家肯定都用过,它能够将另一个 HTML 页面嵌入到当前页面中。利用 iframe ,我们可以快速构建一个安全的沙箱机制,比如将其用于限制 JavaScript 执行等。除了我们平时直接给 iframe 的 src 属性赋值外,iframe 还有不少其他值得了解的属性,这些在完善运行沙箱环境上都会有所帮助,比如其中的 sandbox 属性便可以对呈现在 iframe 中的内容启用一些额外的限制条件。
此外,要实现沙箱中不同容器的的通信,可以通过 postMessage API 来完成。这里有一篇非常详细的文章介绍了 iframe 的方方面面,可以进一步查阅 https://blog.logrocket.com/the-ultimate-guide-to-iframes/ 。
3.3 HTTP Archive
HTTP 请求与响应汇集,即我们常说的 HAR 格式数据。打开 chrome devtools,network tab 下的每一条数据流都代表一个请求,从 http 到 weoscket,request 到 response,包含 request 入参、headers、连接耗时、发起时间、响应时间、TTFB、内容大小等等。如同前面所述,如果要在回放侧派发用户操作的话,那么即需要在采集时将所有请求拦截并标号进行存储,如此一来,直接收集 HAR 便成了最佳的选择。
但想要收集 HAR 会遇到一些限制,比如这类数据只在 chrome devtools API 中开放,所以要实现这块数据的收集,必须采用类似 chrome 插件的形式进行开发,但这样一来,如何进行用户无感知的数据收集与上报又成了一个难题。
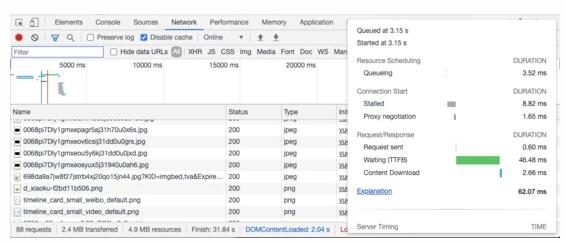
3.4 network 与 webRequest API
利用 chrome.webRequest API 可以允许我们观察和分析流量,并在运行中拦截、阻止或修改它。从上文描述来看,要收集 HAR 只能通过这个 API 来实现,下面给出一个调用 network 对请求拦截处理的示例,详细用法可参照文档 https://developer.chrome.com/extensions/webRequest
- chrome.devtools.network.onRequestFinished.addListener(function (req) {
- // Only collect Resource when XHR option is enabled
- if (document.getElementById('check-xhr').checked) {
- console.log('Resource Collector pushed: ', req.request.url);
- req.getContent(function (body, encoding) {
- if (!body) {
- console.log('No Content Detected!, Resource Collector will ignore: ', req.request.url);
- } else {
- reqs[req.request.url] = {
- body,
- encoding
- };
- }
- setResourceCount();
- });
- setResourceCount();
- }
- });
3.5 Service Worker 与 proxy
我们都知道 Servcie Worker 的 cache API 在 PWA 应用中广泛使用,但其实除了可以将其用于离线应用体验增强外,由于 Servcie Worker 拥有更精细、更完整的控制特性,它完全可以作为一个页面与服务器之间的代理中间层,用于捕获它所负责的页面请求,并返回相应资源。
一般来说,基于框架 HTTPClient (Angular) 或者原生 XMLHttpRequest 的监听,对页面的请求拦截都或多或少存在一些无法捕获的盲区,但 Service Worker 不会,你所需要注意的是需要将它放在你的应用根目录下,或者通过入参在注册时指定 scope 以使你的 Service Worker 在指定范围内生效。
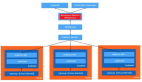
关于它,除了理解其生命周期外,还有些细节需要注意,比如作用域 scope。单个 Service Worker 可以控制多个页面,每个页面不会有自己独有的 worker,所以请注意 scope 的生效范围;在你 scope 范围内的页面在加载完时,Service Worker 便可以开始控制它,所以请小心定义 Service Worker 脚本里的全局变量。
当然,为了方便开发,你可以使用 TypeScript、Babel、webpack 等语言和工具,来加速你的开发体验。MDN 有一篇教程对 Service Worker 入门介绍的挺详细,可以一看 https://developer.mozilla.org/en-US/docs/Web/API/Service_Worker_API/Using_Service_Workers

上图为 Service Worker 的生命周期
3.6 Web Worker
Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行。在主线程运行的同时,Worker 线程在后台运行,两者互不干扰。等到 Worker 线程完成计算任务,再把结果返回给主线程。这样的好处是,一些计算密集型或高延迟的任务,被 Worker 线程负担了,主线程(通常负责 UI 交互)就会很流畅,不会被阻塞或拖慢。—— 阮一峰的网络日志
用于收集数据上报的计算工作,由于重计算逻辑且需要频繁做数据处理,最好不要在主线程操作,否则很影响交互体验。Web Worker 是一个很好的解决方案,在采用它之后,其余涉及到 BOM/DOM 的相关操作还可以将需要的数据直接事件传递通知或者 SharedArrayBuffer 共享。
那么,如何构建一个 Web Worker 呢?一个 worker 文件由简单的 JavaScript 代码组成,在写完之后,你需要在主线程中传入 URI 来构建这么一个 worker 线程,如下图所示:
- const myWorker = new Worker('worker.js');
在 worker 中,除了完善用于计算的逻辑代码外,我们还可以引入脚本、通过 postMessage 与主线程通信等等:
- // 引入脚本
- importScripts('foo.js', 'bar.js');
- // 在 Web Worker 中监听消息与向外通信
- onmessage = function(e) {
- console.log('Message received from main script');
- var workerResult = 'Result: ' + (e.data[0] * e.data[1]);
- console.log('Posting message back to main script');
- postMessage(workerResult);
- }
上面提到的 Service Worker 也可以算作 Web Worker 的一个相似品,但与一般的 Web Worker 不同,Service Worker 有一些额外的特性来实现代理的目的。只要它们被安装且被激活,Service Worker 就可以拦截主线程中发起的任何网络请求。
此外,还有一个特别的 Worker 叫做 Worklet,这些 API 都挺有意思,值得另开篇幅介绍,但与本文暂不相关,便不详述。
3.7 空闲调度与 requestIdleCallback
window.requestIdleCallback() 方法将在浏览器的空闲时段内调用的函数排队。这使开发者能够在主事件循环上执行后台和低优先级工作,而不会影响延迟关键事件,如动画和输入响应。函数一般会按先进先调用的顺序执行,然而,如果回调函数指定了执行超时时间 timeout,则有可能为了在超时前执行函数而打乱执行顺序。 —— MDN
由于系统需要对用户数据进行全量收集,除了计算逻辑的负担分摊外,包含序列化节点、快照等结构数据的上传势必又会成为项目潜在的瓶颈与需要考虑的优化点。利用 requestIdleCallback API,我们可以保证数据在处理后的上报(网络请求)不对用户交互造成影响,例如使用户页面卡顿等。
更为人熟知的一个 Web API 是 requestAnimationFrame,这个 API 可以告诉浏览器在下次重绘之前执行传入的回调函数,由于是每帧执行一次,所以其每秒的执行次数与浏览器屏幕刷新次数一致,通常是每秒60次。而 requestIdleCallback 与其相反,它会在每帧的最后执行,但并不是每一帧都保证会执行 requestIdleCallback。这个原因很简单,我们无法保证每一帧结束时我们还有时间,所以并不能保证 requestIdleCallback 的执行时间。
requestIdleCallback API 的设计很简单,一个空闲调度函数,一个可选配置项参数。
- const handle = window.requestIdleCallback(callback[, options])
举个例子,假设我们现在需要追踪用户的点击事件,并将数据上报服务器,利用这个 API 我们可以这样完成数据收集以及上报调度:
- const btns = btns.forEach(btn =>
- btn.addEventListener('click', e => {
- // 其他交互
- putIntoQueue({
- type: 'click'
- // 收集数据
- }));
- schedule();
- });
- function schedule() {
- requestIdleCallback(
- deadline => {
- while (deadline > 0) {
- const event = queues.pop();
- send(event);
- }
- },
- { timeout: 1000 }
- );
- }
3.8 本地持久化存储 - localStorage 与 IndexedDB
既然要上报,那么就要考虑在数据未完成上报时用户的意外退出或者网络断开等。在这些情况下,浏览器的本地存储方案便派上了用场。由于需要保证数据上报的完整性,持久化存储推荐 localStorage API 以及 IndexedDB API。
利用 localStorage API,我们可以快速的存取字符串形式的键值对,但受浏览器限制,存储大小一般有限,仅几兆而已。
利用 IndexedDB API,我们可以在客户端存储大量的结构化数据(也包括文件/二进制大型对象等),IndexedDB 被浏览器存在本地磁盘中,于是,你可以将其存储上限近似看成计算机的剩余存储容量。
IndexedDB 是一个事务型数据库系统,类似于基于 SQL 的 RDBMS。 然而,不像 RDBMS 使用固定列表,IndexedDB 是一个基于 JavaScript 的面向对象数据库。IndexedDB 允许您存储和检索用键索引的对象;可以存储结构化克隆算法支持的任何对象。您只需要指定数据库模式,打开与数据库的连接,然后检索和更新一系列事务。
localStorage 与 IndexedDB 的使用都相对容易,MDN 上有较为完善的入门指导,此处便不贴代码了。
3.9 puppeteer - Headless Chrome Node.js API
假设我们不使用 iframe 来做便捷沙箱环境,那么一个更强大的解决方案便是 puppeteer。
puppeteer 是谷歌官方出品的一个通过 DevTools 协议控制 headless Chrome 的 Node 库,我们可以通过 puppeteer 提供的 API 直接控制 Chrome,进而模拟大部分用户在浏览器上的操作,来进行 UI Test 或者作为爬虫访问页面来收集数据。有关 puppeteer 的使用可以参考文档 https://pptr.dev/
回到我们的场景,当需要重演用户的操作时,我们可以便捷的利用 page API 来做,比如下面这个例子:
- const puppeteer = require('puppeteer');
- (async () => {
- const browser = await puppeteer.launch()
- const page = await browser.newPage()
- await page.goto('https://hijiangtao.github.io/')
- await page.setViewport({ width: 2510, height: 1306 })
- await page.waitForSelector('.ant-tabs-nav-wrap > .ant-tabs-nav-scroll > .ant-tabs-nav > div')
- await page.click('.ant-tabs-nav-wrap > .ant-tabs-nav-scroll > .ant-tabs-nav > div > .ant-tabs-tab:nth-child(2)')
- await page.waitForSelector('.ant-tabs-nav-wrap > .container')
- await page.click('.ant-tabs-nav-wrap > .ant-tabs-nav-scroll > .ant-tabs-nav > div > .ant-tabs-tab:nth-child(1)')
- await browser.close()
- })()
当然,puppeteer 存在广泛的使用场景,比如生成页面截图或者 PDF、进行自动化 UI 测试、构建爬虫系统、捕获页面时间轴进行性能诊断等等,曾经写过一篇文章介绍如何利用 puppeteer 实现网页自动分页截图,感兴趣的朋友可以戳此《 用 puppeteer 实现网站自动分页截取的趣事 》查看,本文不再对其余细节做详细解读。
4 / 结语
本文通过组合介绍了各类 Web API 及一些新技术,试图通过技术调研以及实际项目开发中总结的经验,为大家在考虑解决「如何实现一个前端监控回放系统」这一问题上提供思路,本文介绍中若有未涉及到的缺漏之处,也欢迎评论告知补充。