












机器学习的快速发展,为智能语音处理奠定了坚实的理论和技术基础。智能语音处理的主要特点是从大量的语音数据中学习和发现其中蕴含的规律,可以有效解决经典语音处理难以解决的非线性问题,从而显著提升传统语音应用的性能,也为语音新应用提供性能更好的解决方案。
01 智能语音处理的基本概念
为简化处理,经典的语音处理方法一般都建立在线性平稳系统的理论基础之上,这是以短时语音具有相对平稳性为前提条件的。但是,严格来讲,语音信号是一种典型的非线性、非平稳随机过程,这就使得采用经典的处理方法难以进一步提升语音处理系统的性能,如语音识别系统的识别率等。
随着机器人技术的不断发展,以机器人智能语音交互为代表的语音新应用迫切要求发展新的语音处理技术与手段,以提高语音处理系统的性能水平。
近十年来,人工智能技术正以前所未有的速度向前发展,机器学习领域不断涌现的新技术、新算法,特别是新型神经网络和深度学习技术等极大地推动了语音处理的发展,为语音处理的研究提供了新的方法和技术手段,智能语音处理应运而生。
至今为止,智能语音处理还没有一个精确的定义。广义上来说,在语音处理算法或系统实现中全部或部分采用智能化的处理技术或手段均可称为智能语音处理。
02 智能语音处理的基本框架
“声源-滤波器”模型虽然能够有效地区分声源激励和声道滤波器,对它们进行高效的估计,但语音产生时发声器官存在着协同动作,存在紧耦合关系,采用简单的线性模型无法准确描述语音的细节特征。
同时,语音是一种富含信息的信号载体,它承载了语义、说话人、情绪、语种、方言等诸多信息,分离、感知这些信息需要对语音进行十分精细的分析,对这些信息的判别也不再是简单的规则描述,单纯对发声机理、信号的简单特征采用人工手段去分析并不现实。
类似于人类语言学习的思路,采用机器学习手段,让机器通过“聆听”大量的语音数据,并从语音数据中学习蕴含其中的规律,是有效提升语音信息处理性能的主要手段。与经典语音处理方法仅限于通过提取人为设定特征参数进行处理不同,智能语音处理最重要的特点就是在语音处理过程或算法中体现从数据中学习规律的思想。
图1-5给出了智能语音处理的三种基本框架,图中虚线框部分有别于经典语音处理方法,包含了从数据中学习的思想,是智能语音处理的核心模块。
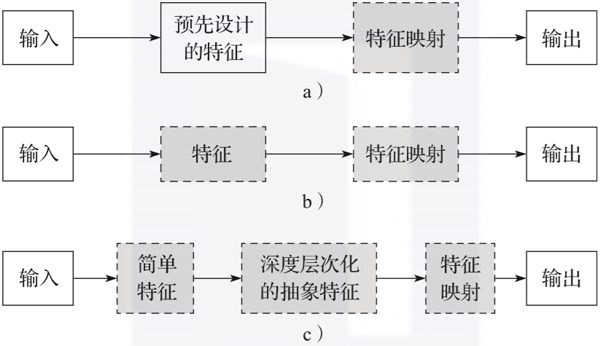
▲图1-5 智能语音处理的基本框架
其中,图1-5a是在经典语音处理特征提取的基础上,在特征映射部分融入了智能处理,是机器学习的经典形式,图1-5b和图1-5c是表示学习的基本框架,其中图1-5c是深度学习的典型框架,“深度层次化的抽象特征”是通过分层的深度神经网络结构来实现的。
03 智能语音处理的基本模型
智能语音处理是智能信息处理的一个重要研究领域,智能信息处理涉及的模型、方法、技术均可应用于智能语音处理。智能语音处理的基本模型和技术主要来源于人工智能,机器学习作为人工智能的重要领域,是目前智能语音处理中最常用的手段,而机器学习中的表示学习和深度学习则是智能语音处理中目前最为成功的智能处理技术。
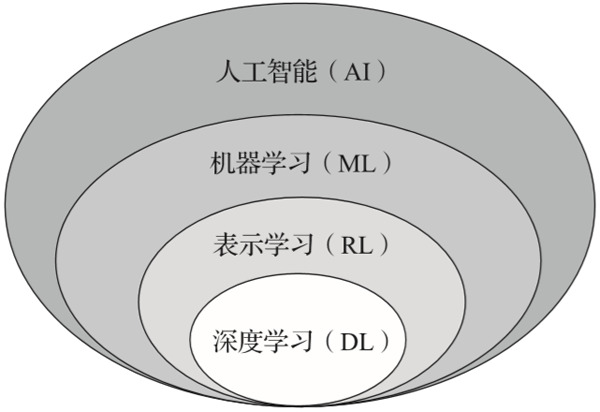
▲图1-6 AI/ML/RL/DL的关系图
图1-6展示了人工智能(Artificial Intelligence,AI)、机器学习(Machine Learning,ML)、表示学习(Representation Learning,RL)及深度学习(Deep Learning,DL)的相互关系。
下面列出了近年来在智能语音处理中常见的模型和技术。
1. 稀疏与压缩感知
一个事物的表示形式决定了认知该事物的难度。在信息处理中,具有稀疏特性的信号表示更易于被感知和辨别,反之则难以辨别。因此,寻找信号的稀疏表示是高效解决信息处理问题的一个重要手段。
利用冗余字典,可以学习信号自身的特点,构造信号的稀疏表示,并进一步降低采样和处理的难度。这种字典学习方法为信息处理提供了新的视角。对语音信号采用字典学习,构造语音的稀疏表示,为语音编码、语音分离等应用提供了新的研究思路。
2. 隐变量模型
语音的所有信息都包含在语音波形中,隐变量模型假设这些信息是隐含在观测信号之后的隐变量。通过利用高斯建模、隐马尔可夫建模等方法,隐变量模型建立了隐变量和观测变量之间的数学描述,并给出了从观测变量学习各模型参数的方法。
通过参数学习,可以将隐变量的变化规律挖掘出来,从而得到各种需要的隐含信息。隐变量模型大大提高了语音识别、说话人识别等应用的性能,在很长一段时间内都是智能语音处理的主流手段。
3. 组合模型
组合模型认为语音是多种信息的组合,这些信息可以采用线性叠加、相乘、卷积等不同方式组合在一起。具体的组合方式中需要采用一系列模型参数,这些模型参数可以通过学习方式从大量语音数据中学得。这类模型的提出,有效改善了语音分离、语音增强等应用的性能。
4. 人工神经网络与深度学习
人类面临大量感知数据时,总能以一种灵巧的方式获取值得注意的重要信息。模仿人脑高效、准确地表示信息一直是人工智能领域的核心挑战。
人工神经网络(Artificial Neural Network,ANN)通过神经元连接成网的方式,模拟了哺乳类动物大脑皮层的神经通路。和生物的神经系统一样,ANN通过对环境输入的感知和学习,可以不断优化性能。
随着ANN的结构越来越复杂、层数越来越多,网络的表示能力也越来越强,基于ANN进行深度学习成为ANN研究的主流,其性能相对于很多传统的机器学习方法有较大幅度的提高。但同时,深度学习对输入数据的要求也越来越高,通常需要有海量数据的支撑。
ANN很早就应用到了语音处理领域,但由于早期受到计算资源的限制,神经网络层数较少,语音处理应用性能难以提升,直到近年来深层神经网络的计算资源、学习方法有了突破之后,基于神经网络的语音处理性能才有了显著的提升。
深度神经网络可以学到语音信号中各种信息间的非线性关系,解决了传统语音处理方法难以解决的问题,已经成为当前智能语音处理的重要技术手段。
本文摘编自《智能语音处理》,经出版方授权发布。


















