介绍
Monasca 是一个多租户监控即服务工具,可以帮助IT团队分析日志数据并设置告警和通知。
OpenStack环境中的监控需求是巨大,多样且高度复杂的。Monasca的项目任务是提供一种多租户,高度可扩展,高性能和容错的监控即服务解决方案。
Monasca为高级监控提供了可扩展的平台,运营商和租户均可使用该平台来获取有关其基础架构和应用的运行状态。
Monasca使用REST API进行高速的日志处理和查询。它集成了流告警引擎,通知引擎和聚合引擎。
您可以使用Monasca实现的用例非常多样。Monasca遵循微服务架构,其中几个服务分布在多个存储库中。每个模块旨在为整个监控解决方案提供离散服务,并且可以根据运营商/客户的需求进行部署。
- 使用Rest API接口来存储、查询性能和历史数据,不同于其他监控工具使用特殊的协议和传输方法,如nagios的NSCA,Monasca只利用了http
- 多租户认证,指标的提交和认证使用Keystone组件。存储关联租户ID
- 指标使用(key,value)的键值来定义,称作量度(dimensions)
- 对系统指标进行实时阈值和告警
- 复合告警设置使用简单的语法,由子告警表达式和逻辑操作器组成
- 监控代理支持内置的系统和服务的检查结果,同时也只nagios的checks和statsd
- 根据开源技术搭建的开源监控方案
架构
下图概述了Monasca的指标管道以及所涉及组件的交互。
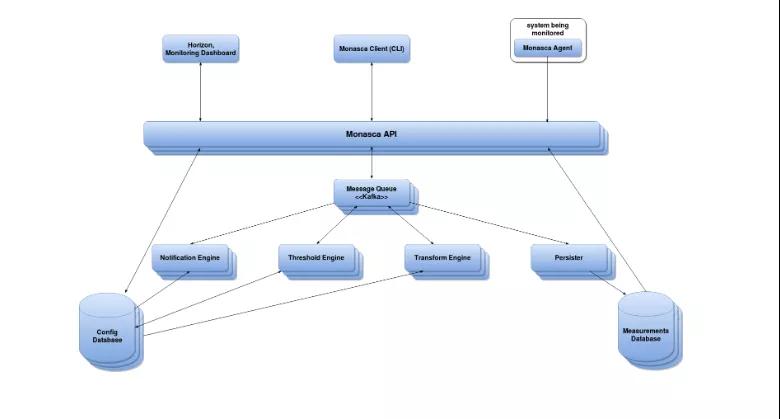
核心组件
- monasca-agent:监控代理,python编写,包含了多个子组件,支持各种cpu使用率、可用内存、nagios插件、statsd、以及许多服务如mysql、rabbitMQ等监控
- monasca-api::一个用于监控的RESTful API接口,针对在以下概念和区域:
- 指标:对于实时的大量指标的存储和查询
- 统计:查询指标的统计数据
- 告警定义:告警定义的增删查改
- 告警:查询和删除告警历史
- 通知方式:创建和删除通知方式,当告警状态改变时可以直接邮件通知用户—monasca API可以通过python或JAVA来实现
- manasca-persister:消息队列传送指标或告警的消费者(RPC传输中的概念consumer),并将指标和告警存入对应的数据库
- monasca-transform:一个转换聚合引擎,转换指标的名字和值,生成新的指标传递给消息队列
- Anomaly and Prediction Engine:目前还是原型阶段
- monasca-thresh:对指标进行计算,当超过阈值是发布告警给消息队列,基于Apache storm项目(开源实时分布式计算系统)
- monasca-notification:接受从消息队列传来的告警,并发送通知,如发送告警邮件,Notification Engine基于Python
- monasca-analytics:分析引擎,接受从消息队列传来的告警,进行异常检测和告警关联
- 消息队列:以前是支持RabbitMQ的,由于性能、规模、持续性和高可用的限制,转向了Kafka
- Metrics and Alarms Database:支持Vertica和infuxDB,对Cassandra的支持正在进行中
- Config Database:配置信息数据库,目前使用Mysql,对PostgreSQL的支持正在进程中
- python-monascaclient:python实现的命令行客户端,对monasca API进行操控
- Monitoring UI:Horizon dashboard的可视化
- Ceilometer publisher:提供给Ceilometer的multi-publisher插件
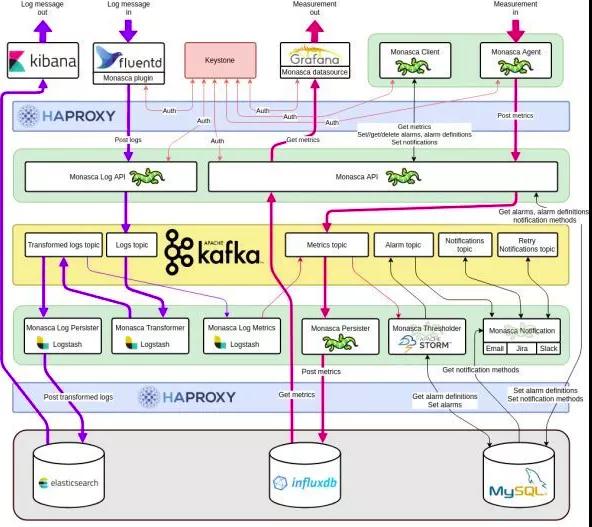
除了直接向API发送请求之外,还可以使用以下工具与Monasca进行交互:
- Monasca client:CLI和Python客户端
- Horizon plugin:该插件将监控面板添加到Horizon
- Grafana app:Grafana插件可查看和配置告警定义,告警和通知
Libraries:
- monasca-common:Monasca组件中使用的通用代码
- monasca-statsd:StatsD兼容的库,用于从已检测的应用程序发送指标
Grafana集成:
- monasca-grafana-datasource:用于Grafana的多租户Monasca数据源
- grafana:Grafana 4.1.2的分支版本,添加了Keystone身份验证
第三方技术与工具
Monasca使用多种第三方技术:
- 内部处理和中间件
- Apache Kafka(http://kafka.apache.org):是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等
- Apache Storm(http://storm.incubator.apache.org/):Apache Storm是一个免费的开源分布式实时计算系统。通过Storm,可以轻松可靠地处理无限数据流,从而可以进行实时处理,而Hadoop可以进行批处理
- ZooKeeper(http://zookeeper.apache.org/):由Kafka和Storm使用
- Apache Spark:由Monasca Transform用作聚合引擎
- 配置数据库:
- MySQL:支持将MySQL作为配置数据库
- PostgreSQL:通过Hibernate和SQLAlchemy支持Config数据库的POSTgres
- Vagrant(http://www.vagrantup.com/):Vagrant提供了易于配置,可重复的便携式工作环境,该环境建立在行业标准技术之上,并由一个一致的工作流程控制,可帮助您最大程度地提高生产力和灵活性
- Dropwizard(https://dropwizard.github.io/dropwizard/):Dropwizard将Java生态系统中稳定,成熟的库汇集到一个简单,轻巧的程序包中,使您可以专注于完成自身的工作任务中。Dropwizard对复杂的配置,应用程序指标,日志记录,操作工具等提供了开箱即用的支持,使您和您的团队可以在最短的时间内发布高质量的Web服务
- 时间序列数据库:
- InfluxDB(http://influxdb.com/):一个没有外部依赖性的开源分布式时间序列数据库。Metrics数据库支持InfluxDB
- Vertica(http://www.vertica.com):具有高度可扩展性的商业企业级SQL分析数据库。它提供了内置的自动高可用性功能,并且擅长数据库内分析以及压缩和存储大量数据。提供了Vertica的免费社区版本,该版本可以存储最大1 TB的数据,没有时间限制,网址为https://my.vertica.com/community/。虽然不再经常用Vertrica,但Metrics数据库支持它
- Cassandra(https://cassandra.apache.org):Mestrics数据库支持Cassandra
安装
手工安装
monasca的所有组件都可以安装在一个节点上,例如openstack控制器节点上,也可以将其部署在多节点上。本文中,将在我的openstack集群中创建的新VM中安装monasca-api,该VM具有关联的浮动ip。Monasca-agent已安装在控制器节点上。代理节点通过浮动ip将指标发布到api节点。它们在同一子网中。
安装我们需要的软件包和工具
apt-get install -y git
apt-get install openjdk-7-jre-headless python-pip python-dev
- 1.
- 2.
安装mysql数据库如果您在openstack控制器节点中安装了monasca-api,则可以跳过安装,将已安装的msyql用于openstack服务。
apt-get install -y mysql-server
- 1.
创建monasca数据库架构,在此处下载mon.sql( https://raw.githubusercontent.com/stackforge/cookbook-monasca-schema/master/files/default/mysql/mon.sql)
mysql -uroot -ppassword < mon_mysql.sql
- 1.
安装Zookeeper安装Zookeeper并重新启动它。我使用本地主机接口,并且只有一个Zookeeper,因此默认配置文件不需要配置。
apt-get install -y zookeeper zookeeperd zookeeper-bin
service zookeeper restart
- 1.
- 2.
安装和配置kafka
wget http://apache.mirrors.tds.net/kafka/0.8.1.1/kafka_2.9.2-0.8.1.1.tgz
mv kafka_2.9.2-0.8.1.1.tgz /opt
cd /opt
tar zxf kafka_2.9.2-0.8.1.1.tgz
ln -s /opt/kafka_2.9.2-0.8.1.1/ /opt/kafka
ln -s /opt/kafka/config /etc/kafka
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
创建kafka系统用户,kafka服务将以该用户身份启动。
useradd kafka -U -r
- 1.
在/etc/init/kafka.conf中创建kafka启动脚本,将以下内容复制 到/etc/init/kafka.conf中并保存。
description "Kafka"
start on runlevel [2345]
stop on runlevel [!2345]
respawn
limit nofile 32768 32768
# If zookeeper is running on this box also give it time to start up properly
pre-start script
if [ -e /etc/init.d/zookeeper ]; then
/etc/init.d/zookeeper restart
fi
end script
# Rather than using setuid/setgid sudo is used because the pre-start task must run as root
exec sudo -Hu kafka -g kafka KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" JMX_PORT=9997 /opt/kafka/bin/kafka-server-start.sh /etc/kafka/server.properties
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
配置kafka,vim /etc/kafka/server.properties,确保配置了以下内容:
host.name=localhost
advertised.host.name=localhost
log.dirs=/var/kafka
- 1.
- 2.
- 3.
创建 kafka log目录
mkdir /var/kafka
mkdir /var/log/kafka
chown -R kafka. /var/kafka/
chown -R kafka. /var/log/kafka/
- 1.
- 2.
- 3.
- 4.
启动kafka服务
service kafka start
- 1.
下一步就是创建 kafka topics
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 64 --topic metrics
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 12 --topic events
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 12 --topic raw-events
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 12 --topic transformed-events
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 12 --topic stream-definitions
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 12 --topic transform-definitions
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 12 --topic alarm-state-transitions
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 12 --topic alarm-notifications
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 12 --topic stream-notifications
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic retry-notifications
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
安装和配置 influxdb
curl -sL https://repos.influxdata.com/influxdb.key | apt-key add -
echo "deb https://repos.influxdata.com/ubuntu trusty stable" > /etc/apt/sources.list.d/influxdb.list
apt-get update
apt-get install -y apt-transport-https
apt-get install -y influxdb
service influxdb start
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
创建 influxdb database, user, password, retention policy, 同时修改密码。
influx
CREATE DATABASE mon
CREATE USER monasca WITH PASSWORD 'tyun'
CREATE RETENTION POLICY persister_all ON mon DURATION 90d REPLICATION 1 DEFAULT
exit
- 1.
- 2.
- 3.
- 4.
- 5.
安装与配置 storm
wget http://apache.mirrors.tds.net/storm/apache-storm-0.9.6/apache-storm-0.9.6.tar.gz
mkdir /opt/storm
cp apache-storm-0.9.6.tar.gz /opt/storm/
cd /opt/storm/
tar xzf apache-storm-0.9.6.tar.gz
ln -s /opt/storm/apache-storm-0.9.6 /opt/storm/current
useradd storm -U -r
mkdir /var/storm
mkdir /var/log/storm
chown -R storm. /var/storm/
chown -R storm. /var/log/storm/
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
修改storm.yaml, vim current/storm/conf/storm.yaml
### base
java.library.path: "/usr/local/lib:/opt/local/lib:/usr/lib"
storm.local.dir: "/var/storm"
### zookeeper.*
storm.zookeeper.servers:
- "localhost"
storm.zookeeper.port: 2181
storm.zookeeper.retry.interval: 5000
storm.zookeeper.retry.times: 29
storm.zookeeper.root: "/storm"
storm.zookeeper.session.timeout: 30000
### supervisor.* configs are for node supervisors
supervisor.slots.ports:
- 6701
- 6702
- 6703
- 6704
supervisor.childopts: "-Xmx1024m"
### worker.* configs are for task workers
worker.childopts: "-Xmx1280m -XX:+UseConcMarkSweepGC -Dcom.sun.management.jmxremote"
### nimbus.* configs are for the masteri
nimbus.host: "localhost"
nimbus.thrift.port: 6627
mbus.childopts: "-Xmx1024m"
### ui.* configs are for the master
ui.host: 127.0.0.1
ui.port: 8078
ui.childopts: "-Xmx768m"
### drpc.* configs
### transactional.* configs
transactional.zookeeper.servers:
- "localhost"
transactional.zookeeper.port: 2181
transactional.zookeeper.root: "/storm-transactional"
### topology.* configs are for specific executing storms
topology.acker.executors: 1
topology.debug: false
logviewer.port: 8077
logviewer.childopts: "-Xmx128m"
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
创建storm supervisor 启动脚本,vim /etc/init/storm-supervisor.conf
# Startup script for Storm Supervisor
description "Storm Supervisor daemon"
start on runlevel [2345]
console log
respawn
kill timeout 240
respawn limit 25 5
setgid storm
setuid storm
chdir /opt/storm/current
exec /opt/storm/current/bin/storm supervisor
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
创建Storm nimbus 启动脚本。vim /etc/init/storm-nimbus.conf
# Startup script for Storm Nimbus
description "Storm Nimbus daemon"
start on runlevel [2345]
console log
respawn
kill timeout 240
respawn limit 25 5
setgid storm
setuid storm
chdir /opt/storm/current
exec /opt/storm/current/bin/storm nimbus
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
启动supervisor 与 nimbus
service storm-supervisor start
service storm-nimbus start
- 1.
- 2.
安装monasca api python软件包
一些monasca组件同时提供python和java代码,主要是我选择python代码进行部署。
pip install monasca-common
pip install gunicorn
pip install greenlet # Required for both
pip install eventlet # For eventlet workers
pip install gevent # For gevent workers
pip install monasca-api
pip install influxdb
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
vim /etc/monasca/api-config.ini,将主机修改为您的IP地址
[DEFAULT]
name = monasca_api
[pipeline:main]
# Add validator in the pipeline so the metrics messages can be validated.
pipeline = auth keystonecontext api
[app:api]
paste.app_factory = monasca_api.api.server:launch
[filter:auth]
paste.filter_factory = keystonemiddleware.auth_token:filter_factory
[filter:keystonecontext]
paste.filter_factory = monasca_api.middleware.keystone_context_filter:filter_factory
[server:main]
use = egg:gunicorn#main
host = 192.168.2.23
port = 8082
workers = 1
proc_name = monasca_api
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
vim /etc/monasca/api-config.conf,修改以下内容
[DEFAULT]
# logging, make sure that the user under whom the server runs has permission
# to write to the directory.
log_file = monasca-api.log
log_dir = /var/log/monasca/api/
debug=False
region = RegionOne
[security]
# The roles that are allowed full access to the API.
default_authorized_roles = admin, user, domainuser, domainadmin, monasca-user
# The roles that are allowed to only POST metrics to the API. This role would be used by the Monasca Agent.
agent_authorized_roles = admin
# The roles that are allowed to only GET metrics from the API.
read_only_authorized_roles = admin
# The roles that are allowed to access the API on behalf of another tenant.
# For example, a service can POST metrics to another tenant if they are a member of the "delegate" role.
delegate_authorized_roles = admin
[kafka]
# The endpoint to the kafka server
uri = localhost:9092
[influxdb]
# Only needed if Influxdb database is used for backend.
# The IP address of the InfluxDB service.
ip_address = localhost
# The port number that the InfluxDB service is listening on.
port = 8086
# The username to authenticate with.
user = monasca
# The password to authenticate with.
password = tyun
# The name of the InfluxDB database to use.
database_name = mon
[database]
url = "mysql+pymysql://monasca:tyun@127.0.0.1/mon"
[keystone_authtoken]
identity_uri = http://192.168.1.11:35357
auth_uri = http://192.168.1.11:5000
admin_password = tyun
admin_user = monasca
admin_tenant_name = service
cafile =
certfile =
keyfile =
insecure = false
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
注释掉[mysql]部分,其他部分保持默认。
创建monasca系统用户并进入目录
useradd monasca -U -r
mkdir /var/log/monasca
mkdir /var/log/monasca/api
chown -R monasca. /var/log/monasca/
- 1.
- 2.
- 3.
- 4.
在openstack控制器节点上,创建monasca用户密码,为租户服务中的用户monasca分配管理员角色。
openstack user create --domain default --password tyun monasca
openstack role add --project service --user monasca admin
openstack service create --name monasca --description "Monasca monitoring service" monitoring
create endpoint
openstack endpoint create --region RegionOne monasca public http://192.168.1.143:8082/v2.0
openstack endpoint create --region RegionOne monasca internal http://192.168.1.143:8082/v2.0
openstack endpoint create --region RegionOne monasca admin http://192.168.1.143:8082/v2.0
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
192.168.1.143是我的api虚拟机地址的浮动IP,请将其更改为您的IP。
创建monasca api启动脚本,vim /etc/init/monasca-api.conf
# Startup script for the Monasca API
description "Monasca API Python app"
start on runlevel [2345]
console log
respawn
setgid monasca
setuid monasca
exec /usr/local/bin/gunicorn -n monasca-api -k eventlet --worker-connections=2000 --backlog=1000 --paste /etc/monasca/api-config.ini
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
安装monasca-persister
创建monasca-persister启动脚本
vim /etc/init/monasca-persister.conf
# Startup script for the Monasca Persister
description "Monasca Persister Python app"
start on runlevel [2345]
console log
respawn
setgid monasca
setuid monasca
exec /usr/bin/java -Dfile.encoding=UTF-8 -cp /opt/monasca/monasca-persister.jar monasca.persister.PersisterApplication server /etc/monasca/persister-config.yml
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
启动monasca-persister
service monasca-persister start
- 1.
安装monasca-notificatoin
pip install --upgrade monasca-notification
apt-get install sendmail
- 1.
- 2.
将notification.yaml复制到/etc/monasca/创建启动脚本,vim /etc/init/monasca-notification.conf
# Startup script for the monasca_notification
description "Monasca Notification daemon"
start on runlevel [2345]
console log
respawn
setgid monasca
setuid monasca
exec /usr/bin/python /usr/local/bin/monasca-notification
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
启动通知服务
service monasca-notification start
- 1.
安装monasca-thresh复制monasca-thresh到/etc/init.d/复制monasca-thresh.jar到/opt/monasca-thresh/复制thresh-config.yml到/etc/monasca /并修改主机以及数据库信息启动monasca-thresh
service monasca-thresh start
- 1.
安装monasca-agent
在openstack控制器节点上安装monasca-agent,以便它可以监控openstack服务进程。
sudo pip install --upgrade monasca-agent
- 1.
设置monasca-agent,将用户域ID和项目域ID更改为默认值。
monasca-setup -u monasca -p tyun --user_domain_id e25e0413a70c41449d2ccc2578deb1e4 --project_domain_id e25e0413a70c41449d2ccc2578deb1e4 --user monasca \
--project_name service -s monitoring --keystone_url http://192.168.1.11:35357/v3 --monasca_url http://192.168.1.143:8082/v2.0 --config_dir /etc/monasca/agent --log_dir /var/log/monasca/agent --overwrite
- 1.
- 2.
加载认证脚本admin-rc.sh,然后运行monasca metric-list。
DevStack安装
运行Monasca DevStack至少需要一台具有10GB RAM的主机。
可在此处找到安装和运行Devstack的说明:
https://docs.openstack.org/devstack/latest/
- 1.
要在DevStack中运行Monasca,请执行以下三个步骤。
克隆DevStack代码库。
git clone https://git.openstack.org/openstack-dev/devstack
- 1.
将以下内容添加到devstack目录根目录中的DevStack local.conf文件中。如果local.conf不存在,则可能需要创建它。
# BEGIN DEVSTACK LOCAL.CONF CONTENTS
[[local|localrc]]
DATABASE_PASSWORD=secretdatabase
RABBIT_PASSWORD=secretrabbit
ADMIN_PASSWORD=secretadmin
SERVICE_PASSWORD=secretservice
SERVICE_TOKEN=111222333444
LOGFILE=$DEST/logs/stack.sh.log
LOGDIR=$DEST/logs
LOG_COLOR=False
# The following two variables allow switching between Java and Python for the implementations
# of the Monasca API and the Monasca Persister. If these variables are not set, then the
# default is to install the Python implementations of both the Monasca API and the Monasca Persister.
# Uncomment one of the following two lines to choose Java or Python for the Monasca API.
MONASCA_API_IMPLEMENTATION_LANG=${MONASCA_API_IMPLEMENTATION_LANG:-java}
# MONASCA_API_IMPLEMENTATION_LANG=${MONASCA_API_IMPLEMENTATION_LANG:-python}
# Uncomment of the following two lines to choose Java or Python for the Monasca Pesister.
MONASCA_PERSISTER_IMPLEMENTATION_LANG=${MONASCA_PERSISTER_IMPLEMENTATION_LANG:-java}
# MONASCA_PERSISTER_IMPLEMENTATION_LANG=${MONASCA_PERSISTER_IMPLEMENTATION_LANG:-python}
# Uncomment one of the following two lines to choose either InfluxDB or Vertica.
# default "influxdb" is selected as metric DB
MONASCA_METRICS_DB=${MONASCA_METRICS_DB:-influxdb}
# MONASCA_METRICS_DB=${MONASCA_METRICS_DB:-vertica}
# This line will enable all of Monasca.
enable_plugin monasca-api https://git.openstack.org/openstack/monasca-api
# END DEVSTACK LOCAL.CONF CONTENTS
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
从devstack目录的根目录运行“ ./stack.sh”。
如果要使用最少的OpenStack组件运行Monasca,可以将以下两行添加到local.conf文件中。
disable_all_services
enable_service rabbit mysql key
- 1.
- 2.
如果您还希望安装Tempest测试,请添加 tempest
enable_service rabbit mysql key tempest
- 1.
要启用Horizon和Monasca UI,请添加 horizon
enable_service rabbit mysql key horizon tempest
- 1.
使用Vagrant
Vagrant可用于使用Vagrantfile部署运行有Devstack和Monasca的VM。安装Vagrant后,只需在../monasca-api/devstack目录中运行vagrant up命令。
要在devstack安装中使用本地代码库,请将更改提交到本地存储库的master分支,然后在配置文件中修改与要使用的本地存储库相对应的变量file://my/local/repo/location。要使用monasca-api repo的本地实例,请将更改enable_plugin monasca-api https://git.openstack.org/openstack/monasca-api为enable_plugin monasca-api file://my/repo/is/here。这两个设置仅在重建devstack VM时生效。
1.使用Vagrant将Vertica启用为Metrics DB
Monasca支持同时使用InfluxDB和Vertica来存储指标和告警状态历史记录。默认情况下,在DevStack环境中启用InfluxDB。
Vertica是Hewlett Packard Enterprise的商业数据库。可以下载免费的Community Edition(CE)安装程序,要启用Vertica,请执行以下操作:
- 注册并下载Vertica Debian安装程序https://my.vertica.com/download/vertica/community-edition/,并将其放在您的主目录中。不幸的是,DevStack安装程序没有可以自动使用的URL,因此必须单独下载该URL,并将其放置在安装程序运行时可以找到它的位置。安装程序假定此位置是您的主目录。使用Vagrant时,您的主目录通常将以“ /vagrant_home”挂载在VM内。
- 修改local.conf中MONASCA_METRICS_DB变量,配置Vertica的支持,如下所示:
MONASCA_METRICS_DB=${MONASCA_METRICS_DB:-vertica}
2.使用PostgreSQL或MySQL
Monasca支持使用PostgreSQL和MySQL,因此该devstack插件也支持。启用postgresql或mysql。
要使用MySQL设置环境,请使用:
enable_service mysql
- 1.
另外,对于PostgreSQL,请使用:
enable_service postgresql
- 1.
3.使用ORM支持
ORM支持可以通过MONASCA_DATABASE_USE_ORM变量来控制。但是,如果启用了PostgreSQL(也称为数据库后端),则将强制提供ORM支持
enable_service postgresql
4.加强Apache镜像
如果由于某种原因APACHE_MIRROR而无法使用,则可以通过以下方式强制执行:
APACHE_MIRROR=http://www-us.apache.org/dist/
- 1.
5.使用WSGI
Monasca-api可以使用uwsgi和gunicorn与Apache一起部署。默认情况下,monasca-api在uwsgi下运行。如果您想使用Gunicorn,请确保其中devstack/local.conf包含:
MONASCA_API_USE_MOD_WSGI=False
- 1.
使用
Monasca Dashboard
安装完成Monasca Dashboard Plugin后,可以通过web控制台进行查看以及管理相应的监控与告警。
在操作控制台的“Monitoring”栏,单击“Launch Monitoring Dashboard“,这将打开在管理节点上运行的专用OpenStack Horizon门户。
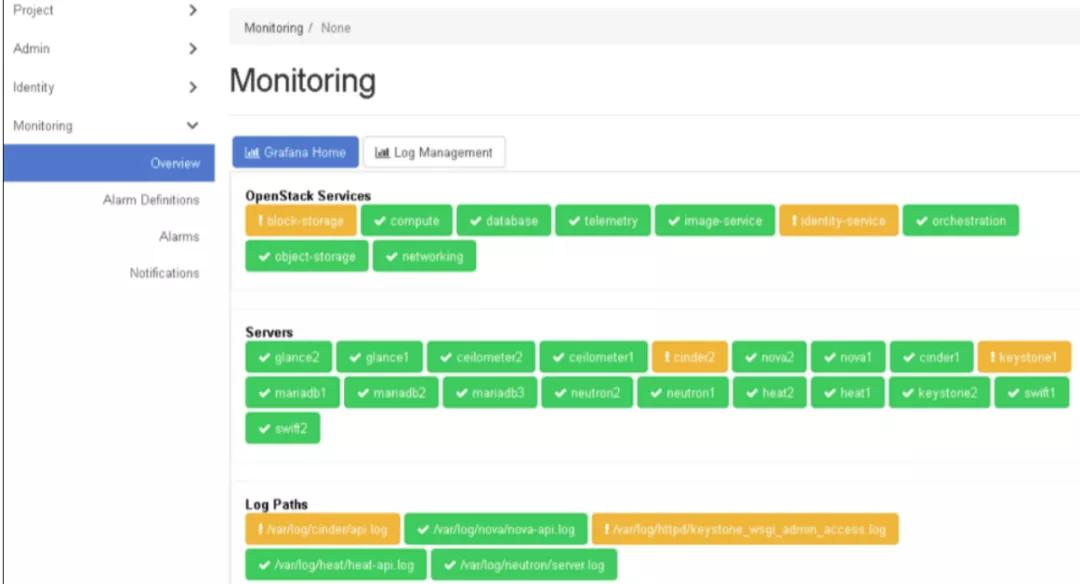
在该面板中,您可以:
- 单击OpenStack服务名称,以查看服务告警。
- 单击服务器名称以查看相关设备的告警。
监控信息存储在两个数据库中(Vertica/influxdb与mysql)。备份监控数据时,将同时备份两个数据库。看到
- 监控指标在Vertica中存储7天。
- 配置设置存储在MySQL中。
- 如果监控节点上的服务在高负载(例如15个控制网络和200个计算节点)下停止,则消息队列将在大约6个小时内开始清除。
查看监控信息
在操作控制台中,通过从主菜单中选择Monitoring Dashboard来打开监控UI 。
单击Launch Monitoring Dashboard。
将打开管理设备上OpenStack Horizon中的“Monitoring”仪表板。
使用您在首次安装过程中为操作控制台设置的用户名和密码登录。
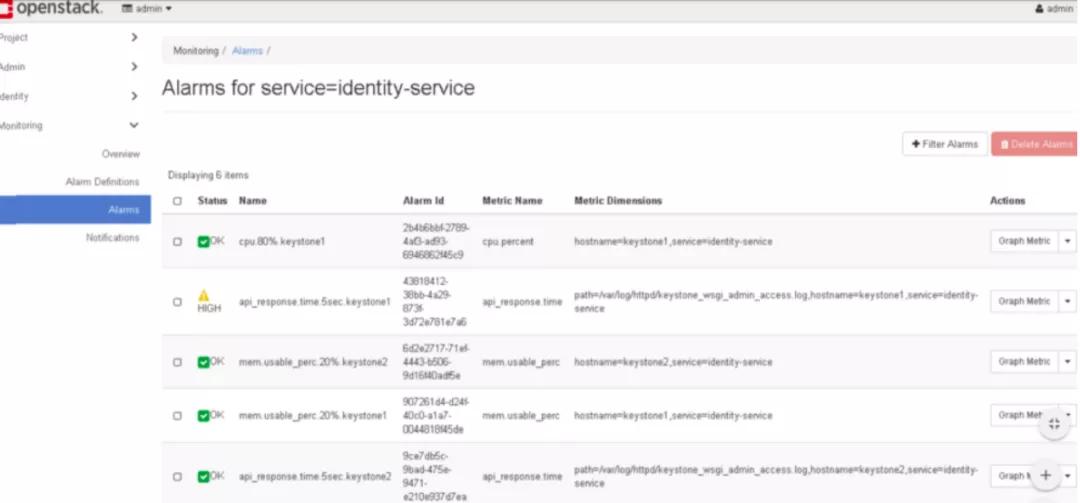
查看告警。您可以在屏幕上过滤结果。
- 点击告警左侧导航看到报警的所有服务和设备。
- 在每行右侧的“操作”菜单上,可以单击“Graph metrics”以查看告警明细,并且可以显示告警的历史记录和告警定义。您还可以在该告警的图形顶部看到指标名称。
- 点击OpenStack服务名称以查看服务告警。
- 单击服务器名称以查看有关设备的告警。
单击左侧导航中的”Alarm Definitions “以查看和编辑已启用的告警的类型。
注意:请勿更改或删除任何默认告警定义。但是,您可以添加新的告警定义。
您可以更改告警的名称,表达式和其他详细信息。
如果收到过多或不足的告警,则可能需要提高或降低告警阈值。
有关编写告警表达式的信息。
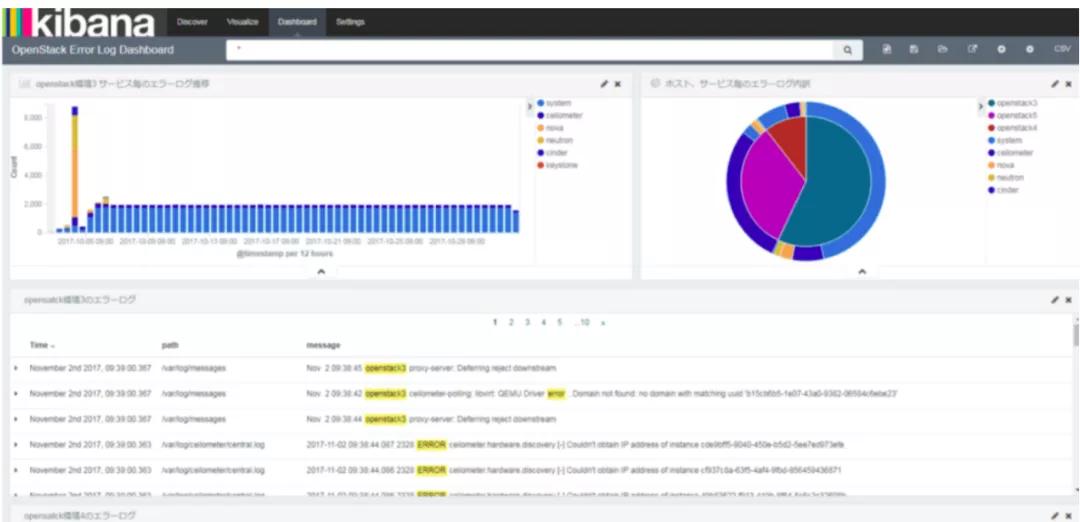
可选:单击Dashboard。
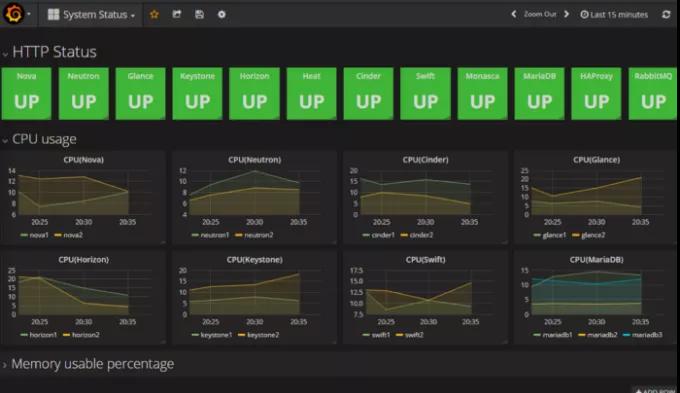
OpenStack仪表板(Grafana)打开。从该仪表板中,您可以看到OpenStack服务的运行状况以及每个节点的CPU和数据库使用情况的图形表示。
- 单击图形标题(例如,CPU),然后单击“编辑”。
- 更改功能以查看图中的其他类型的信息。
可选:单击Monasca Health。
将打开“ Monasca服务仪表板”。在此仪表板上,您可以看到Monasca服务运行状况的图形表示。
总结
Monasca作为Openstack的monitoring-as-a-service组件,目前社区和网上的资料还是比较少。本文通过作者的实践,记录了Monasca相关的安装和配置以及使用的方法,
Monasca是一个可以实现IAAS到PAAS的高扩展,高性能的监控系统,其体系架构决定了它能够轻松驾驭大集群,高负载的监控。当前我们已经逐步摈弃了ceilometer+gnocchi+aodh的组合,全面转向Monasca。当前监控的不仅仅是云主机,云网络,同时也监控着我们Openstack集群内部的Kubernetns集群,数据库集群,对象存储等PAAS软件。
参考文章:
https://docs.openstack.org/monasca-api/latest/
https://wiki.openstack.org/wiki/Monasca