介绍
Redis是一个内存数据库,当Redis使用的内存超过物理内存的限制后,内存数据会和磁盘产生频繁的交换,交换会导致Redis性能急剧下降。所以在生产环境中我们通过配置参数maxmemoey来限制使用的内存大小。
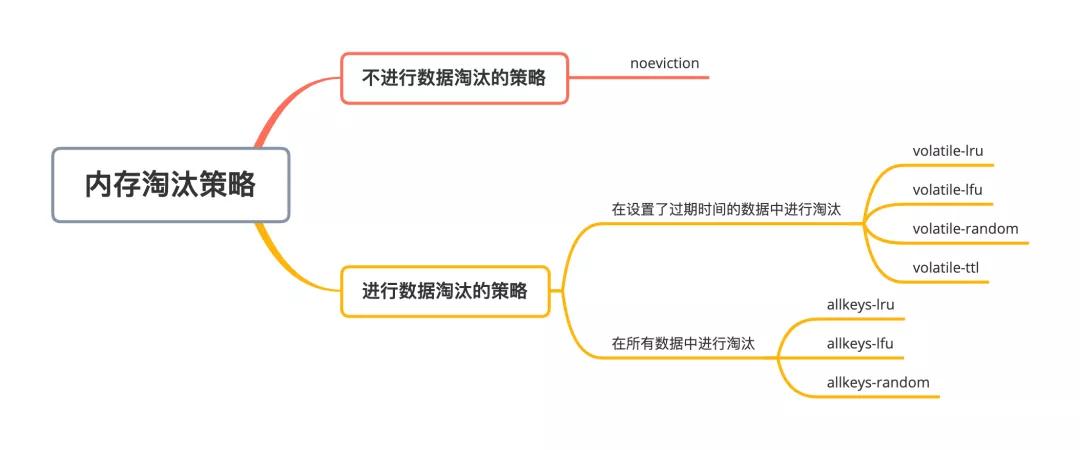
当实际使用的内存超过maxmemoey后,Redis提供了如下几种可选策略。
noeviction:写请求返回错误
volatile-lru:使用lru算法删除设置了过期时间的键值对 volatile-lfu:使用lfu算法删除设置了过期时间的键值对 volatile-random:在设置了过期时间的键值对中随机进行删除 volatile-ttl:根据过期时间的先后进行删除,越早过期的越先被删除
allkeys-lru:在所有键值对中,使用lru算法进行删除 allkeys-lfu:在所有键值对中,使用lfu算法进行删除 allkeys-random:所有键值对中随机删除
我们来详细了解一下lru和lfu算法,这是2个常见的缓存淘汰算法。「因为计算机缓存的容量是有限的,所以我们要删除那些没用的数据,而这两种算法的区别就是判定没用的纬度不一样。」
LRU算法
「lru(Least recently used,最近最少使用)算法,即最近访问的数据,后续很大概率还会被访问到,即是有用的。而长时间未被访问的数据,应该被淘汰」
lru算法中数据会被放到一个链表中,链表的头节点为最近被访问的数据,链表的尾节点为长时间没有被访问的数据
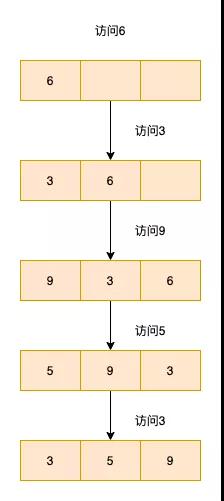
「lru算法的核心实现就是哈希表加双向链表」。链表可以用来维护访问元素的顺序,而hash表可以帮我们在O(1)时间复杂度下访问到元素。
「至于为什么是双向链表呢」?主要是要删除元素,所以要获取前继节点。数据结构图示如下
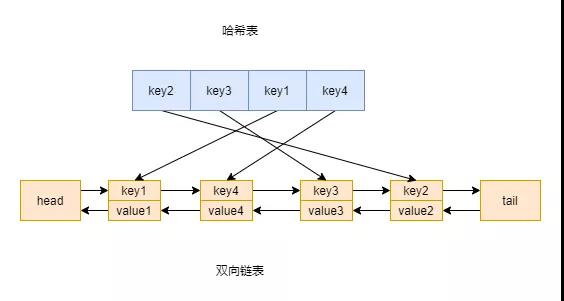
使用双向链表+HashMap
双向链表节点定义如下
public class ListNode<K, V> {
K key;
V value;
ListNode pre;
ListNode next;
public ListNode() {}
public ListNode(K key, V value) {
this.key = key;
this.value = value;
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
封装双向链表的常用操作
public class DoubleList {
private ListNode head;
private ListNode tail;
public DoubleList() {
head = new ListNode();
tail = new ListNode();
head.next = tail;
tail.pre = head;
}
public void remove(ListNode node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
public void addLast(ListNode node) {
node.pre = tail.pre;
tail.pre = node;
node.pre.next = node;
node.next = tail;
}
public ListNode removeFirst() {
if (head.next == tail) {
return null;
}
ListNode first = head.next;
remove(first);
return first;
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
封装一个缓存类,提供最基本的get和put方法。「需要注意,这两种基本的方法都涉及到对两种数据结构的修改」。
public class MyLruCache<K, V> {
private int capacity;
private DoubleList doubleList;
private Map<K, ListNode> map;
public MyLruCache(int capacity) {
this.capacity = capacity;
map = new HashMap<>();
doubleList = new DoubleList();
}
public V get(Object key) {
ListNode<K, V> node = map.get(key);
if (node == null) {
return null;
}
// 先删除该节点,再接到尾部
doubleList.remove(node);
doubleList.addLast(node);
return node.value;
}
public void put(K key, V value) {
// 直接调用这边的get方法,如果存在,它会在get内部被移动到尾巴,不用再移动一遍,直接修改值即可
if ((get(key)) != null) {
map.get(key).value = value;
return;
}
// 如果超出容量,把头去掉
if (map.size() == capacity) {
ListNode listNode = doubleList.removeFirst();
map.remove(listNode.key);
}
// 若不存在,new一个出来
ListNode node = new ListNode(key, value);
map.put(key, node);
doubleList.addLast(node);
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
这里我们的实现为最近访问的放在链表的尾节点,不经常访问的放在链表的头节点
测试一波,输出为链表的正序输出(代码为了简洁没有贴toString方法)
MyLruCache<String, String> myLruCache = new MyLruCache<>(3);
// {5 : 5}
myLruCache.put("5", "5");
// {5 : 5}{3 : 3}
myLruCache.put("3", "3");
// {5 : 5}{3 : 3}{4 : 4}
myLruCache.put("4", "4");
// {3 : 3}{4 : 4}{2 : 2}
myLruCache.put("2", "2");
// {4 : 4}{2 : 2}{3 : 3}
myLruCache.get("3");
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
「因为LinkedHashMap的底层实现就是哈希表加双向链表,所以你可以用LinkedHashMap替换HashMap和DoubleList来改写一下上面的类」。
我来演示一下更骚的操作,只需要重写一个构造函数和removeEldestEntry方法即可。
使用LinkedHashMap实现LRU
public class LruCache<K, V> extends LinkedHashMap<K, V> {
private int cacheSize;
public LruCache(int cacheSize) {
/**
* initialCapacity: 初始容量大小
* loadFactor: 负载因子
* accessOrder: false基于插入排序(默认),true基于访问排序
*/
super(cacheSize, 0.75f, true);
this.cacheSize = cacheSize;
}
/**
* 当调用put或者putAll方法时会调用如下方法,是否删除最老的数据,默认为false
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > cacheSize;
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
注意这个缓存并不是线程安全的,可以调用Collections.synchronizedMap方法返回线程安全的map
LruCache<String, String> lruCache = new LruCache(3);
Map<String, String> safeMap = Collections.synchronizedMap(lruCache);
- 1.
- 2.
Collections.synchronizedMap实现线程安全的方式很简单,只是返回一个代理类。代理类对Map接口的所有方法加锁
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<>(m);
}
- 1.
- 2.
- 3.
LFU算法
「LRU算法有一个问题,当一个长时间不被访问的key,偶尔被访问一下后,可能会造成一个比这个key访问更频繁的key被淘汰。」
即LRU算法对key的冷热程度的判断可能不准确。而LFU算法(Least Frequently Used,最不经常使用)则是按照访问频率来判断key的冷热程度的,每次删除的是一段时间内访问频率较低的数据,比LRU算法更准确。
使用3个hash表实现lfu算法
那么我们应该如何组织数据呢?
为了实现键值的对快速访问,用一个map来保存键值对
private HashMap<K, Integer> keyToFreq;
- 1.
还需要用一个map来保存键的访问频率
private HashMap<K, Integer> keyToFreq;
- 1.
「当然你也可以把值和访问频率封装到一个类中,用一个map来替代上述的2个map」
接下来就是最核心的部分,删除访问频率最低的数据。
- 为了能在O(1)时间复杂度内找到访问频率最低的数据,我们需要一个变量minFreq记录访问最低的频率
- 每个访问频率有可能对应多个键。当空间不够用时,我们要删除最早被访问的数据,所以需要如下数据结构,Map<频率, 有序集合>。每次内存不够用时,删除有序集合的第一个元素即可。并且这个有序集合要能快速删除某个key,因为某个key被访问后,需要从这个集合中删除,加入freq+1对应的集合中
- 有序集合很多,但是能满足快速删除某个key的只有set,但是set插入数据是无序的。「幸亏Java有LinkedHashSet这个类,链表和集合的结合体,链表不能快速删除元素,但是能保证插入顺序。集合内部元素无序,但是能快速删除元素,完美」
下面就是具体的实现。
public class LfuCache<K, V> {
private HashMap<K, V> keyToVal;
private HashMap<K, Integer> keyToFreq;
private HashMap<Integer, LinkedHashSet<K>> freqTokeys;
private int minFreq;
private int capacity;
public LfuCache(int capacity) {
keyToVal = new HashMap<>();
keyToFreq = new HashMap<>();
freqTokeys = new HashMap<>();
this.capacity = capacity;
this.minFreq = 0;
}
public V get(K key) {
V v = keyToVal.get(key);
if (v == null) {
return null;
}
increaseFrey(key);
return v;
}
public void put(K key, V value) {
// get方法里面会增加频次
if (get(key) != null) {
// 重新设置值
keyToVal.put(key, value);
return;
}
// 超出容量,删除频率最低的key
if (keyToVal.size() >= capacity) {
removeMinFreqKey();
}
keyToVal.put(key, value);
keyToFreq.put(key, 1);
// key对应的value存在,返回存在的key
// key对应的value不存在,添加key和value
freqTokeys.putIfAbsent(1, new LinkedHashSet<>());
freqTokeys.get(1).add(key);
this.minFreq = 1;
}
// 删除出现频率最低的key
private void removeMinFreqKey() {
LinkedHashSet<K> keyList = freqTokeys.get(minFreq);
K deleteKey = keyList.iterator().next();
keyList.remove(deleteKey);
if (keyList.isEmpty()) {
// 这里删除元素后不需要重新设置minFreq
// 因为put方法执行完会将minFreq设置为1
freqTokeys.remove(keyList);
}
keyToVal.remove(deleteKey);
keyToFreq.remove(deleteKey);
}
// 增加频率
private void increaseFrey(K key) {
int freq = keyToFreq.get(key);
keyToFreq.put(key, freq + 1);
freqTokeys.get(freq).remove(key);
freqTokeys.putIfAbsent(freq + 1, new LinkedHashSet<>());
freqTokeys.get(freq + 1).add(key);
if (freqTokeys.get(freq).isEmpty()) {
freqTokeys.remove(freq);
// 最小频率的set为空,key被移动到minFreq+1对应的set了
// 所以minFreq也要加1
if (freq == this.minFreq) {
this.minFreq++;
}
}
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
测试一下
LfuCache<String, String> lfuCache = new LfuCache(2);
lfuCache.put("1", "1");
lfuCache.put("2", "2");
// 1
System.out.println(lfuCache.get("1"));
lfuCache.put("3", "3");
// 1的频率为2,2和3的频率为1,但2更早之前被访问,所以被清除
// 结果为null
System.out.println(lfuCache.get("2"));
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.