十大经典排序算法-希尔排序,归并排序,快速排序前言这是十大经典排序算法详解的第二篇,这是之前第一篇文章的链接:十大经典排序算法详解(一)冒泡排序,选择排序,插入排序,没有看过的小伙伴可以看一下.
每次讲解都是「先采用文字」的方式帮助大家先熟悉一下算法的基本思想,之后我会在通过「图片的方式」来帮助大家分析排序算法的动态执行过程,这样就能够帮助大家更好的理解算法.
每次的图画起来都比较的繁琐,真的很耗费时间.所以如果你觉得文章写得还可以或者说对你有帮助的话,你可以选择一键三连,或者选择关注我的公众号:「萌萌哒的瓤瓤」 ,这对我真的很重要.UP在此谢谢各位了.
废话不多说了,下面开始我们的正文部分吧!!!
1-希尔排序
算法思想:
其实希尔排序的思想很简单,因为希尔排序的基本思想就是第一篇中间讲解的关于插入排序的基本思想,「只是希尔排序相比较与插入排序多加了一步就是确定步长」.之前在插入排序的过程中,我们的步长是固定的即为1,在希尔排序中我们的步长是不固定的,「一开始数组长度的一半,之后每次分组排序之后步长就再减半,直到步长到1为止」.这时候我们的排序就已经完成了.
说完了,那我们接下来还是通过图解的方式来帮助大家更好的理解希尔排序吧:
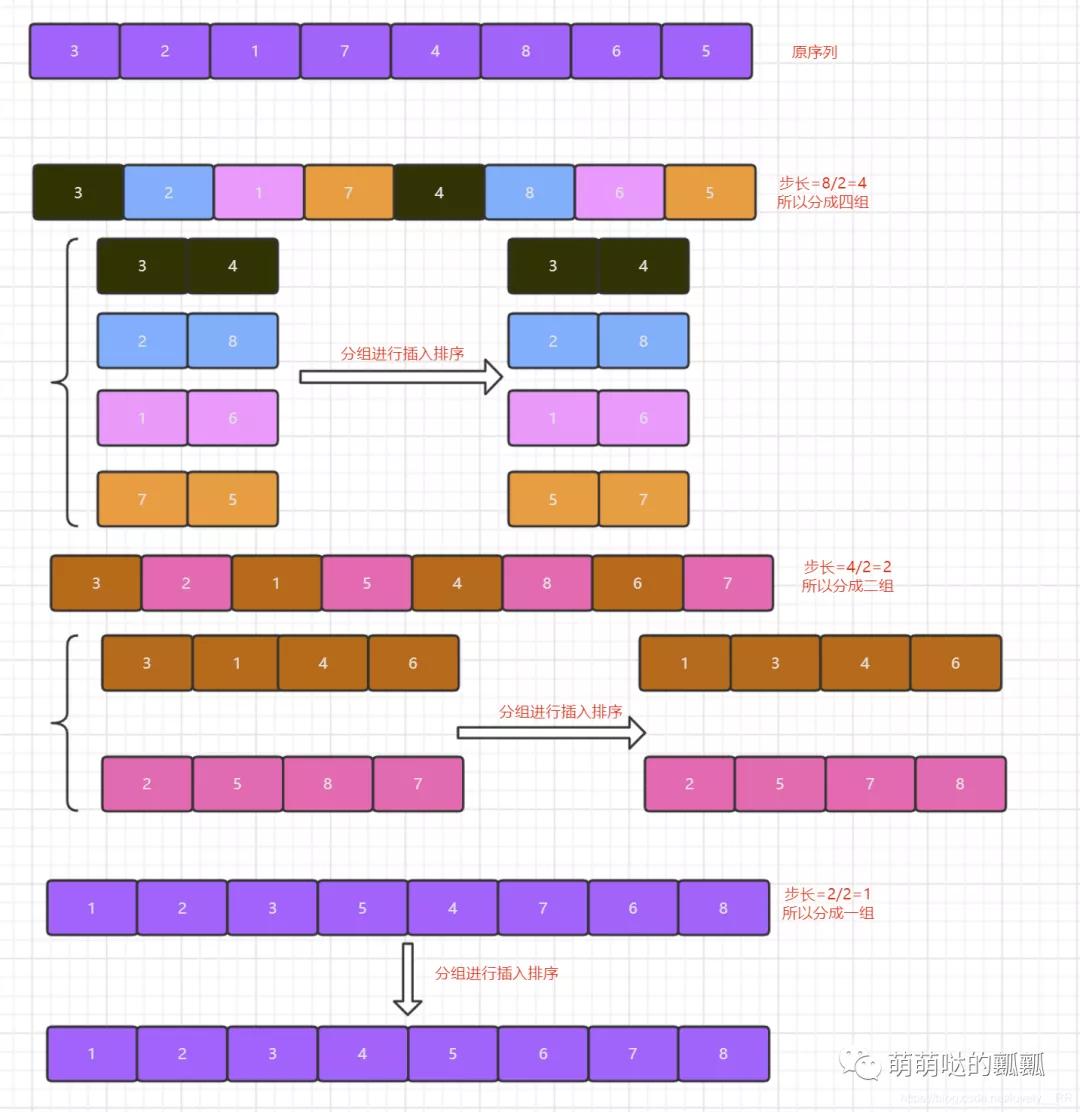
看完上面的图之后相信大家就基本了解希尔排序算法的思想了,那么接下来我们还是来分析一下希尔排序算法的特点吧:
- 希尔排序算法是不稳定的,这里大家可能会产生这样的疑问,本身希尔排序算法的本质就是插入排序,只不过是多了一步确定步长的过程,为什么插入排序就是稳定的,但是希尔排序缺失不稳定的呢?其实重点就是在分组之后,大家都知道在一个分组里面进行一次插入排序肯定是稳定的,关键就在于希尔排序的过程中会出现多次分组,那么就会出现在之前的分组里面是稳定的,但是到下一次分组的时候就会出现不稳定的情况.
说这么多还不如直接来个例子给大家看一下,大家就知道了:
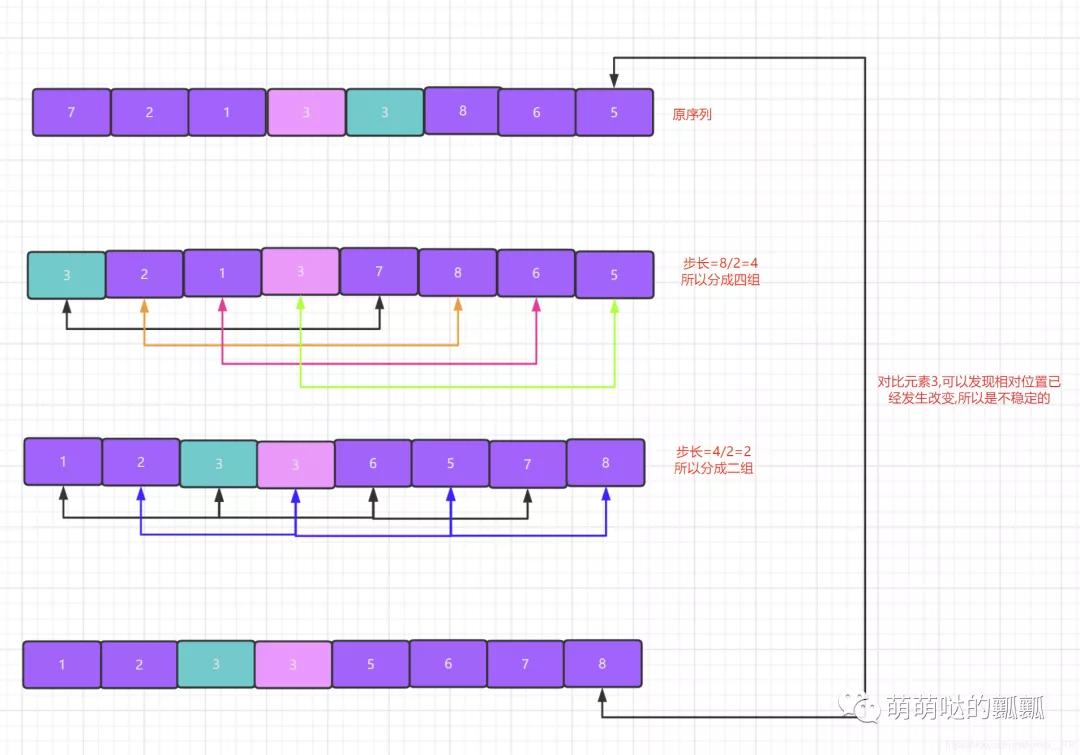
- 希尔排序是 「第一个」 在时间复杂度上突破O(N*N)的算法,这一点是非常有意义的.时间复杂度仅为O(N*log N)
算法图解:
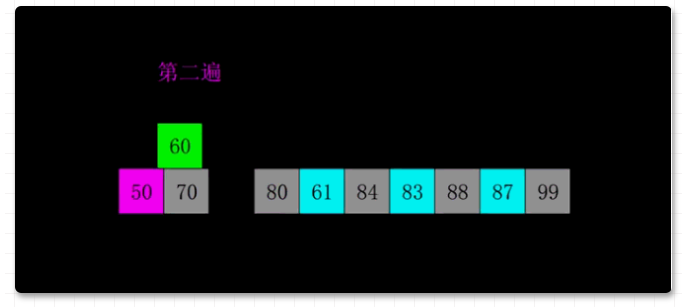
在这里插入图片描述
示例代码:
「按照算法思想不改动的版本」:
- public static void main(String[] args) {
- int []num ={7,4,9,3,2,1,8,6,5,10};
- long startTime=System.currentTimeMillis();
- //规定步长
- for(int step=num.length/2;step>0;step/=2) {
- System.out.println("步长为"+step+"的分组排序:");
- //步长确定之后就需要分批次的对分组进行插入排序
- for(int l=0;l<step;l++) {
- //插入排序的代码
- for(int i=l+step;i<num.length;i+=step) {
- int temp=num[i];
- int j=i;
- while(j>0&&temp<num[j-step]) {
- num[j]=num[j-step];
- j-=step;
- //这里需要注意一点就是j-step可能会越界,所以我们需要继续进行判断
- //之前在插入排序中,步长始终是1,所以在while循环那里就会阻断,但是现在步长会发生变化
- //所以我们需要在这里提前进行判断,否则金辉发生数组越界的情况
- if(j-step<0)
- break;
- }
- if(j!=i) {
- num[j]=temp;
- }
- }
- System.out.println(" "+l+"号分组排序:");
- for(int k=0;k<num.length;k++)
- System.out.print(num[k]+" ");
- System.out.println();
- }
- System.out.println();
- }
- long endTime=System.currentTimeMillis();
- System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
- }

但是大家会发现如果真的按照希尔排序的思想这样做得的话,我们会发现用了三层for循环,那么很显然时间复杂度就会达到我们目前遇到的最坏的情况即O(N*N*N),所以我们需要进行改进,主要就是改进分组排序的过程,之前我们是确定完步长之后,就通过for循环进行循环分组的排序,这里我们修改成直接和下一个for循环一起,直接进行循环分组
「改进后的代码」:
- public static void main(String[] args) {
- int []num ={7,4,9,3,2,1,8,6,5,10};
- long startTime=System.currentTimeMillis();
- for(int step=num.length/2;step>0;step/=2) {
- System.out.println("步长为"+step+"的分组排序:");
- System.out.println("循环分组排序:");
- for(int j=step;j<num.length;j++) {
- int temp=num[j];
- int k=j;
- while(k-step>=0&&temp<num[k-step]) {
- num[k]=num[k-step];
- k-=step;
- }
- num[k]=temp;
- for(int l=0;l<num.length;l++)
- System.out.print(num[l]+" ");
- System.out.println();
- }
- }
- long endTime=System.currentTimeMillis();
- System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
- }

改进之后的算法之使用了两层for循环,真的让时间复杂度达到了O(N*log N)
复杂度分析: 理解完希尔排序的基本思想之后,我们就需要来分析一下他的时间复杂度,空间复杂度.
- 时间复杂度
希尔排序的时间复杂度在各情况下,主要就取决于元素的个数以及分组的次数,我们分析得到分组的次数刚好就是log N,所以我们可以得到希尔排序的时间复杂度仅为O(N*log N)
- 空间复杂度
这个我们可以看到我们整个排序的过程中只增加一个存储Key的位置,所以希尔排序的空间复杂是常量级别的仅为O(1).
2-归并排序
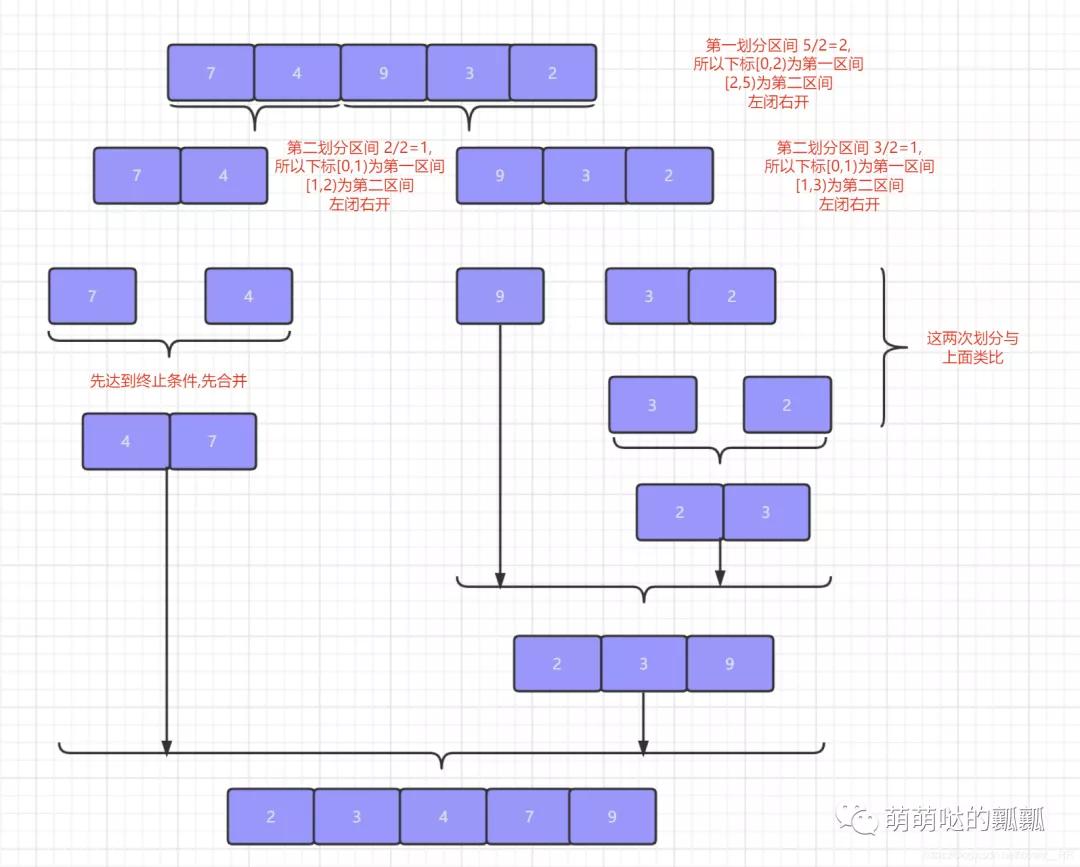
算法思想: 归并排序的思想本质就是进行分冶.把 「整个序列拆分成多个序列」,先将每个序列排好序,这个就是「分冶思想中分」,同样也是「归并排序中归」 的思想.
之后再将各个序列整合到一起这就是「分冶中的冶同样也是归并排序的并」.思想说完了,但是呢说不能解决问题,我们还是通过下面的图来帮助大家理解:
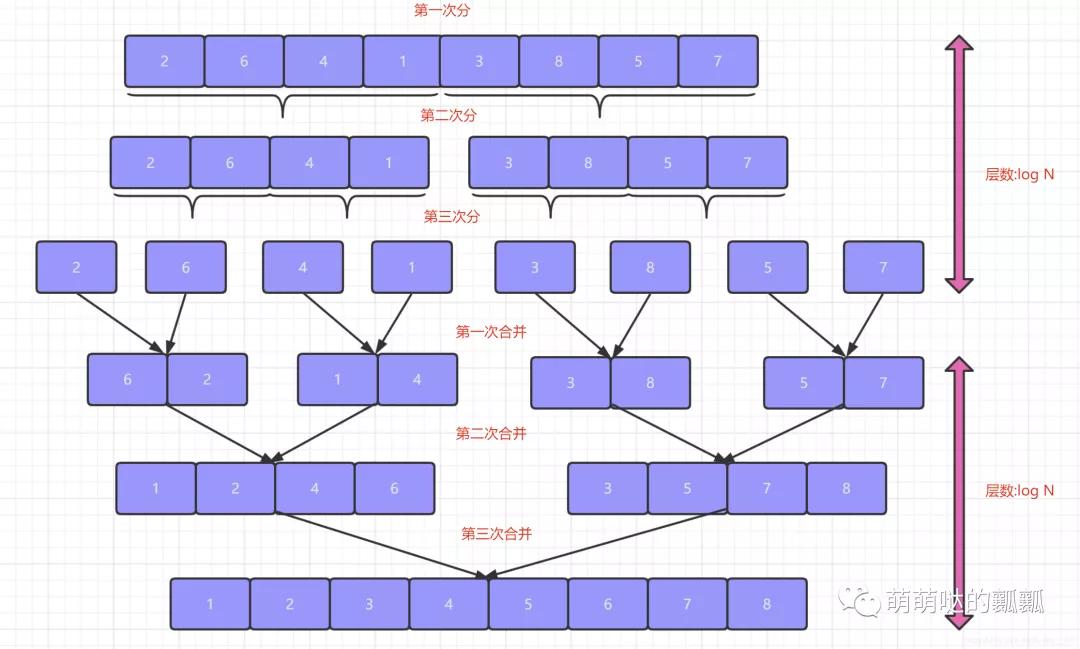
看到图之后,我们就会发现上面分和合并的过程都特别像递归对不对,都是按照一定的终止条件一直执行下去.所以呢这就暗示了我们的归并排序是可以通过「递归」的思想来编写的.
现在我们基本上已经基本了解归并排序的基本思想了,现在我们再来看看归并排序由那些特点吧
归并排序是稳定的,这个大家看过我上面的演示过程就能看出来了.
归并排序需要消耗大量的内存空间.这个内存空间是对比冒泡排序之类的排序算法而言的,因为他们的内存空间都是只存在于常量级别的,但是归并排序却是需要消耗线性级别的内存空间,所以才会使用大量这个形容词.消耗的内存空间就是等同于待排序序列的长度.即O(n)的复杂度.
算法图解:
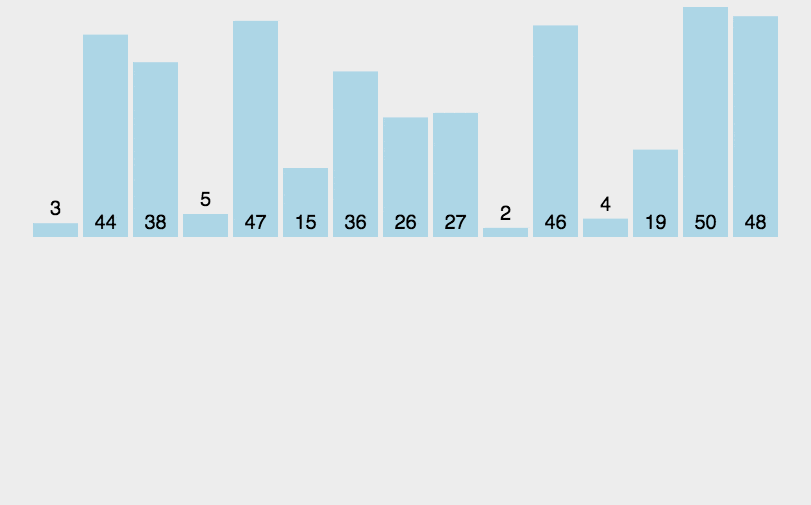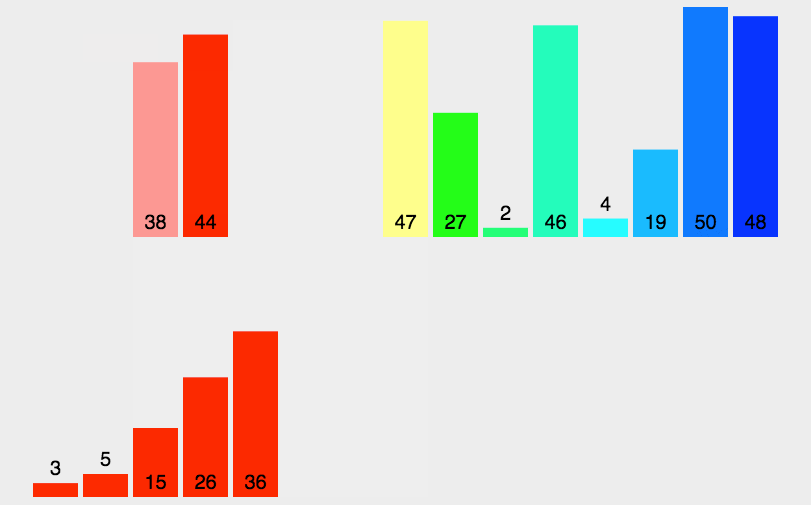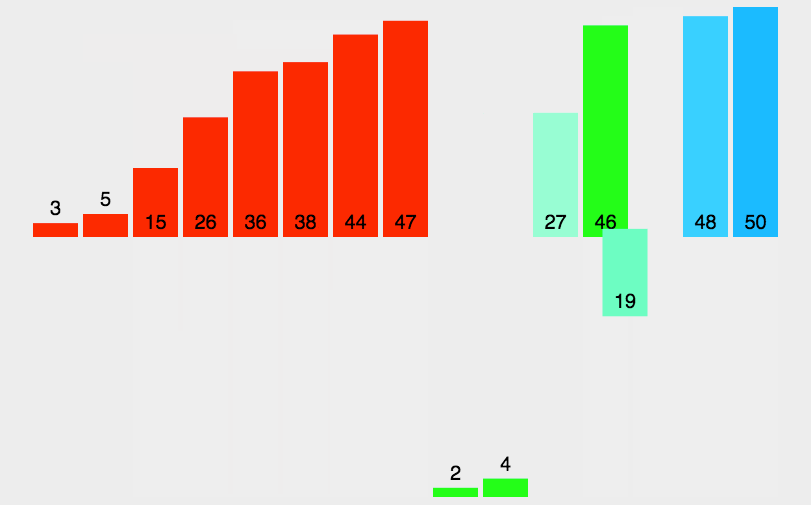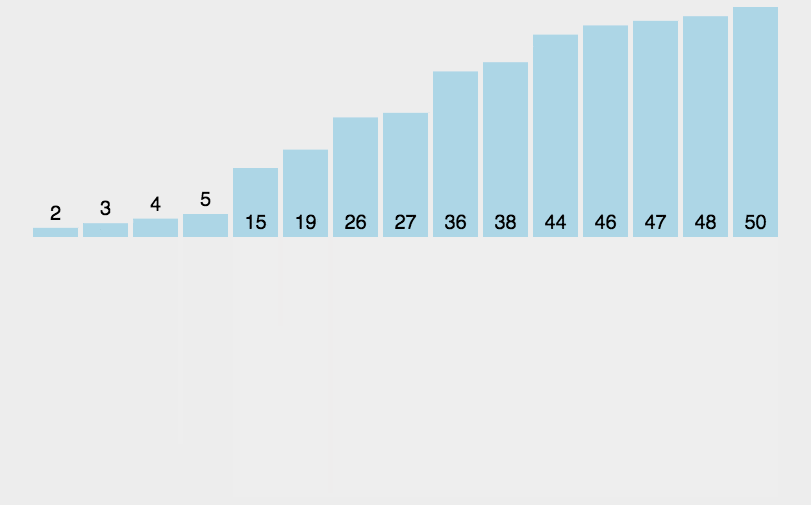
在这里插入图片描述
示例代码:
重要代码我已经添加了注释能够更加方便读者们理解.
- public static int[] sort(int []num) {
- //分裂之后的数组如果只有1个元素的话,
- //那么就说明可以开始合并的过程了,所以直接返回.
- if(num.length<2)
- return num;
- int middle=num.length/2;
- //截取左右两个序列
- int []left=Arrays.copyOfRange(num, 0, middle);
- int []right=Arrays.copyOfRange(num, middle, num.length);
- return merge(sort(left), sort(right));
- }
- public static int[] merge(int []left,int []right) {
- int []num=new int [left.length+right.length];
- int i=0,j=0,k=0;
- //注意终止条件是&&,只要有一个不满足,循环就结束
- while(i<left.length&&j<right.length) {
- if(left[i]<right[j])
- num[k++]=left[i++];
- else
- num[k++]=right[j++];
- }
- //上面的循环跳出之后,就说明有且仅会有一个序列还有值了
- //所以需要再次检查各个序列,并且下面的两个循环是互斥的,只会执行其中的一个
- //或者都不执行
- while(i<left.length) {
- num[k++]=left[i++];
- }
- while(j<right.length) {
- num[k++]=right[j++];
- }
- for(int l=0;l<num.length;l++)
- System.out.print(num[l]+" ");
- System.out.println();
- return num;
- }
- public static void main(String[] args) {
- int []num ={7,4,9,3,2,1,8,6,5,10};
- long startTime=System.currentTimeMillis();
- num=sort(num);
- // for(int i=0;i<num.length;i++) {
- // System.out.print(num[i]+" ");
- // }
- // System.out.println();
- long endTime=System.currentTimeMillis();
- System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
- }

这里呢就不演示全部的元素了,这里就简单和大家演示一下左半边区间元素排序的过程,右半边大家可以自行脑补,这个应该不难.
这样大家应该就能理解了,主要就是如果「序列长度不是2的次方」的话,后续划分序列的时候就会出现上述与我们类似的情况.毕竟我们划分区间的 整个过程就类似于「将区间中心划分成一个二叉树」.
复杂度分析:
理解完归并排序的基本思想之后,我们就需要来分析一下他的时间复杂度,空间复杂度.
- 时间复杂度
其实我们从上面的算法中能明显看出来我们没有使用for循环,而是通过递归的方式来解决我们的循环问题的.所以更加的高效. 就像我们上面的演示过程里面写的一样,这个执行的层数为2 * log N,并且每层操作的元素是N个,所以我们的时间复杂度即为2 * N * log N,但是常数可以忽略不计,所以我们的时间复杂度就控制在了O(N*log N),对比我们之前算法的时间复杂度O(N*N),可以看到「时间复杂度明显降低很多」,并且这个时间复杂度「不仅仅只是适用于平均情况,针对最坏的情况,同样也能适用」.
- 空间复杂度
这个我们也可以看到我们整个排序的过程中需要增加一个等同于排序序列的长度的空间来存储我们为二次排序之后的序列,所以我们需要的空间复杂度就是线性级别的O(n),这个复杂度对比我们之前的几种排序算法,可以看得出来的确是较为大了一点.但是也可以明显看出来整个的时间复杂度明显降低了很多,这就是一种跟明显通过牺牲空间换取时间的方法.对比我们第一篇讲的HashMap.
3-快速排序
算法思想:
快速排序的算法思想也比较好理解.但是呢用文字讲述出来可能会有点难以理解,这里我尽可能的讲的简单些.就算还是看不懂的话也没事,我们还是会通过图片演示的形式来加深大家的理解的.
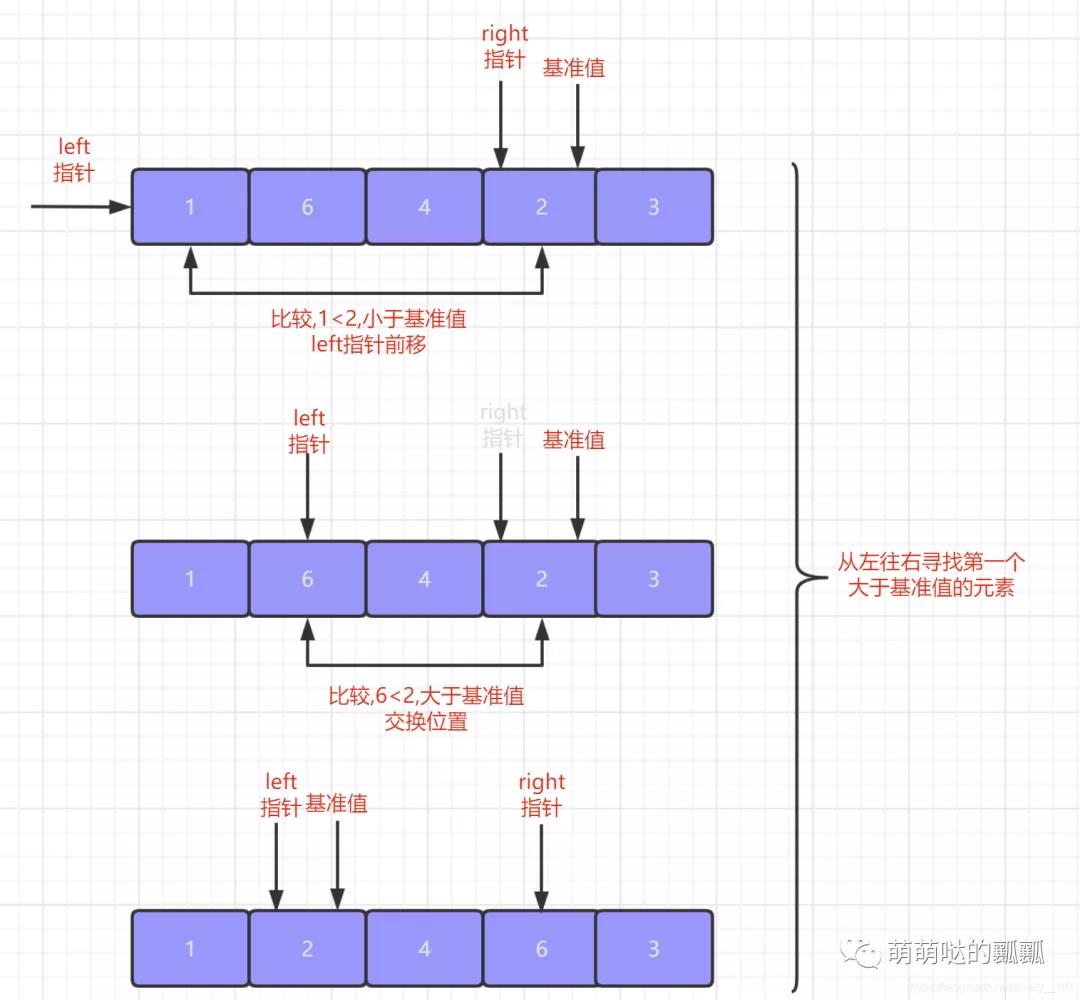
快速排序的思想就是每次排序都「选定一个基准值」 ,当我们在选定完这个基准值之后,我们就另外在需要两个""指针"",这个指针并不是我们C++中的指针,但是作用也差不多,主要就是帮助我们标记位置的.「这两个指针分别指向待排序序列的队头元素和队尾元素」.
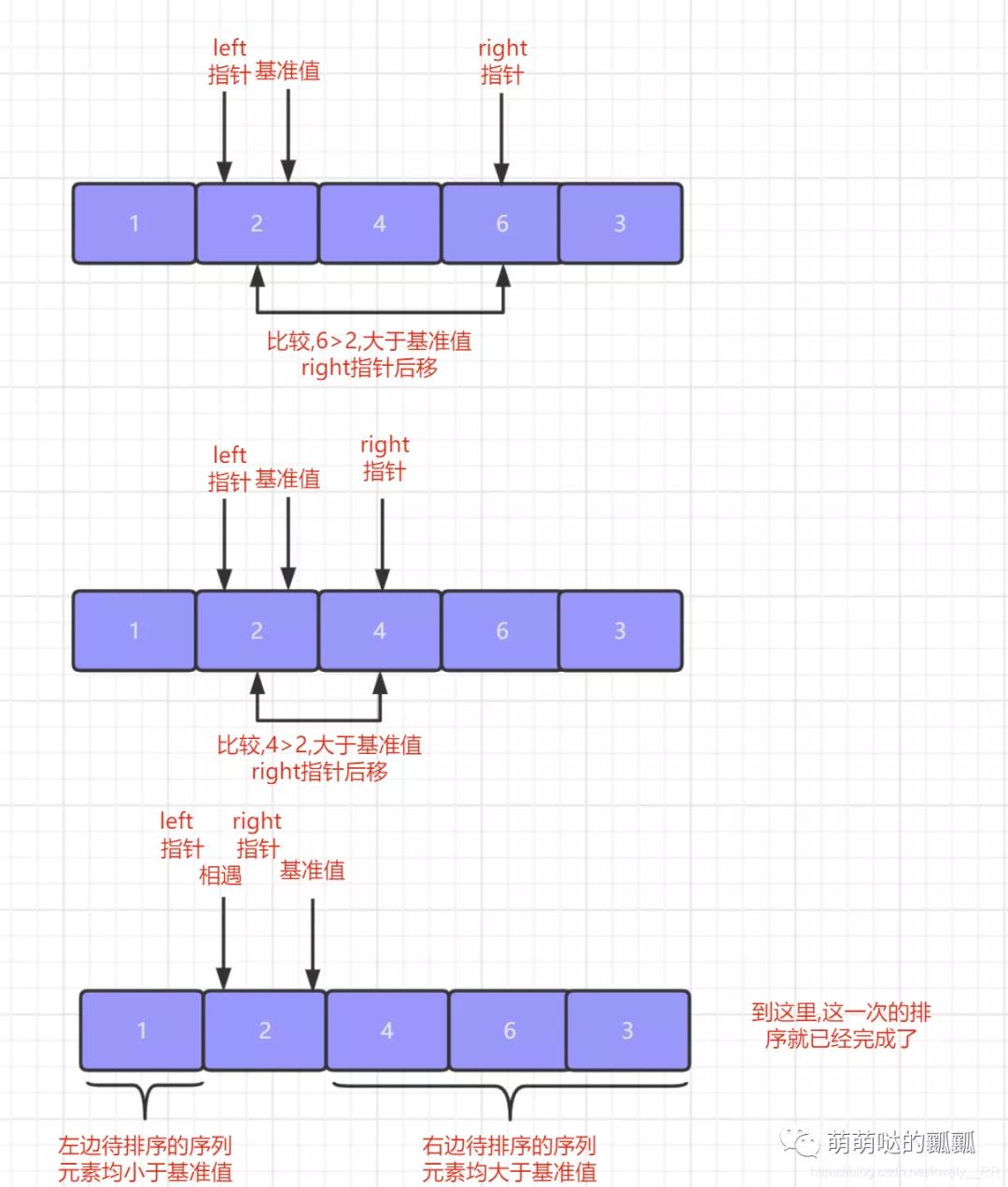
我们首先先「从队尾元素开始从右往左查找出第一个不大于该基准值的元素」,找到之后首先将之前指向队尾元素的指针指向该元素位置,之后再将基准值与我们刚才查找到的元素交换位置.
在这个步骤结束之后,我们就需要「从队头元素开始从左往右查找第一个不小于基准值的元素」,查找到该元素之后还是按照我们上面的步骤.先将之前指向队头元素的指针指向该元素,之后再将基准值与该元素交换位置.
重复上面这个步骤,「直到队头指针与队尾指针相遇,相遇之后就代表我们的第一次排序就已经完成了」,并且在第一次排序完成之后我们就会发现序列是这样的状态,「基准值左边的元素全部小于等于该基准值,基准值右边的元素全部大于等于该基准值.」
之后的排序就只需要对基准值左右两边的序列在进行上述的操作即可.
好了关于算法的文字讲解已经完成了,当然了,这时候很多小伙伴肯定会想 「"你这都说的啥啊"」 ,没关系老样子还是用图来说话:
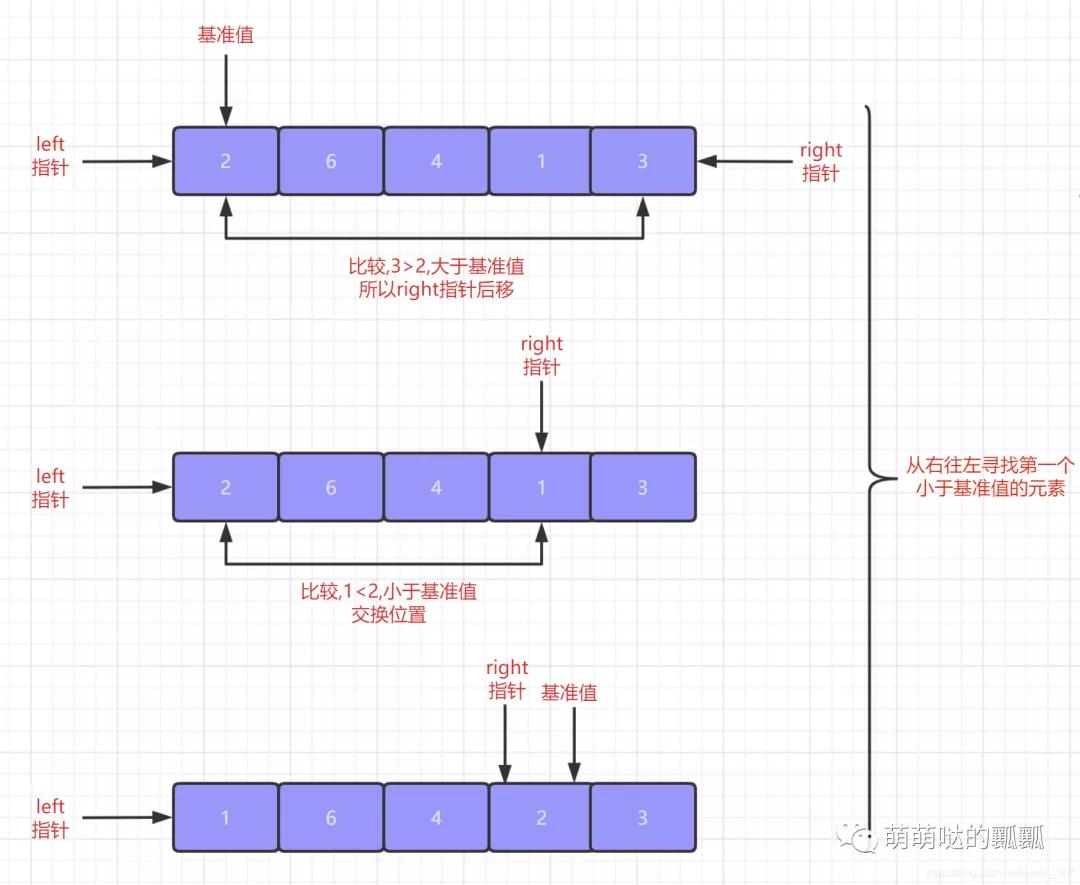
这里我只演示了第一次排序的过程,后续的相信大家可以自行脑补的. 理解完快速排序的基本算法思想之后,我们就需要来稍微聊聊快速排序的特点了.
快速排序本身是不稳定的,我们首先先来了解一下不稳定的快排是什么样的演示过程.
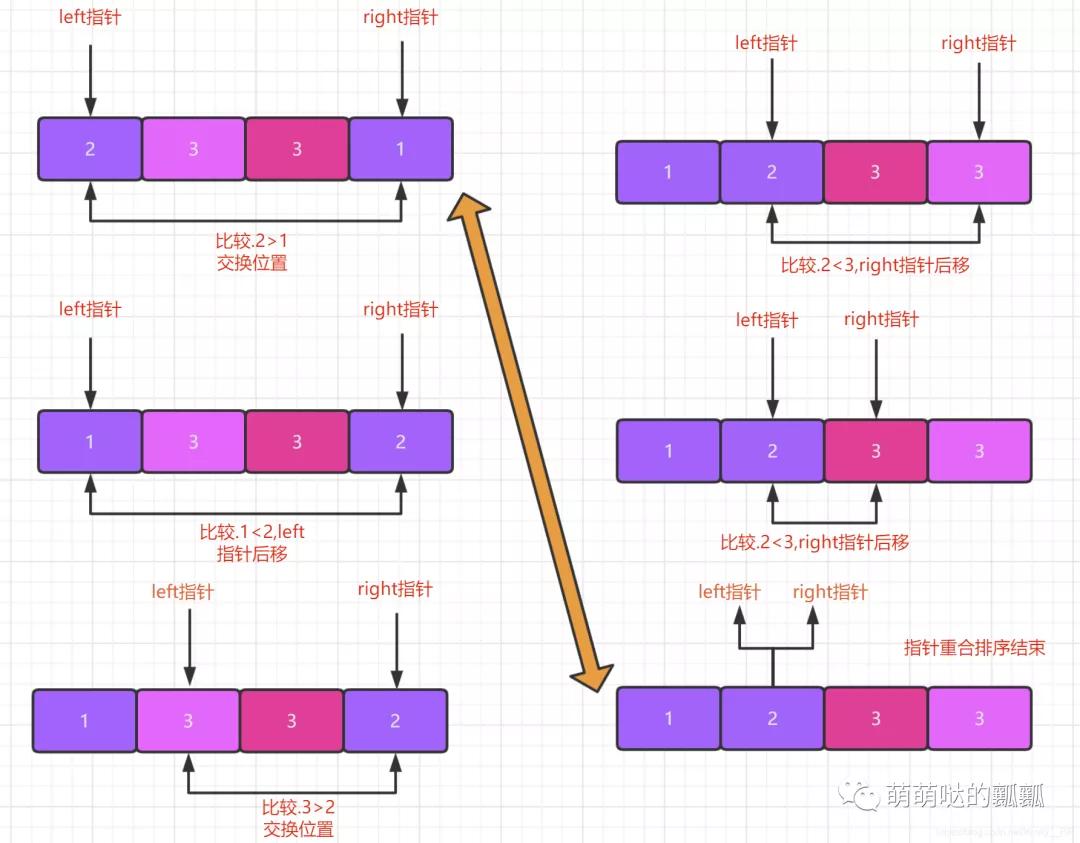
通过上面的图大家就能知道快排为啥是不稳定的了.
「快速排序也有一个极端情况」,就是快排在对 「已经有序的序列进行排序」的时候,时间复杂度会直接飙到O(n*n),也就是最坏的时间复杂度,这个情况大家其实自己模拟以下就能知道了. 这里我们就不在过多讲解了.算法图解:
在这里插入图片描述
示例代码:
重要代码我已经添加了注释能够更加方便读者们理解.
- public static void sort(int []num,int left,int right) {
- if(left<right) {
- int key=num[left];
- int i=left;
- int j=right;
- //这部分便是算法的核心思想
- while(i<j) {
- //从右向左找到第一个不大于基准值的元素
- while(i<j&&num[j]>=key) {
- j--;
- }
- if(i<j) {
- num[i]=num[j];
- }
- //从左往右找到第一个不小于基准值的元素
- while (i<j&&num[i]<=key) {
- i++;
- }
- if(i<j) {
- num[j]=num[i];
- }
- }
- num[i]=key;
- for(int k=0;k<num.length;k++) {
- System.out.print(num[k]+" ");
- }
- System.out.println();
- //递归继续对剩余的序列排序
- sort(num, left, i-1);
- sort(num, i+1, right);
- }
- }
- public static void main(String[] args) {
- int []num ={7,4,9,3,2,1,8,6,5,10};
- long startTime=System.currentTimeMillis();
- sort(num, 0, num.length-1);
- long endTime=System.currentTimeMillis();
- System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
- }
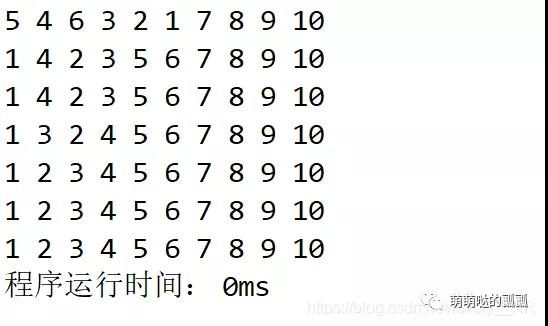
因为上面的动态演示图已经演示的很清楚了,所以就不在画图演示了.
复杂度分析:
理解完快速排序的基本思想之后,我们就需要来分析一下他的时间复杂度,空间复杂度.
- 时间复杂度
其实我们从上面的算法中能明显看出来我们没有使用for循环,而是通过递归的方式来解决我们的循环问题的.所以更加的高效.
就像我们上面所演示的一样,平均情况下的时间复杂度即为O(N * log N),但是也想我们所说的那样,快速排序存在着一个极端情况就是 「已经有序的序列进行快排」 的话很刚好形成是类似于冒泡排序一样的时间复杂度即为O(N * N),这是我们需要注意的,但是在大多数情况下,快排还是我们效率最高的排序算法.
- 空间复杂度
这个我们也可以看到我们整个排序的过程中每次排序的一个循环里面就需要添加一个空间来存储我们的key,并且快排其实和我们上面的归并排序也是有异曲同工之妙的,也有点类似于使用了二叉树的概念,所以他的空间复杂度就是O(log N)
到这里十大经典排序算法详解的第二期内容就已经结束了.如果觉得UP的文章写得还可以或者对你有帮助的话,可以关注UP的公众号,新人UP需要你的支持!!!