












一位小伙伴来问一道谷歌的笔试题,关于单链表操作的,问到底有多少种解决方案,今天我们就来聊聊。
题目的大致意思是:
假设存在一个无序单链表,将重复结点去除后,并保原顺序。
去重前:1→3→1→5→5→7
去重后:1→3→5→7
顺序删除
通过双重循环直接在链表上执行删除操作。外层循环用一个指针从第一个结点开始遍历整个链表,然后内层循环用另外一个指针遍历其余结点,将与外层循环遍历到的指针所指结点的数据域相同的结点删除,如下图所示。
假设外层循环从outerCur开始遍历,当内层循环指针innerCur遍历到上图实线所示的位置(outerCur.data==innerCur.data)时,此时需要把innerCur指向的结点删除。
具体步骤如下:
- 用tmp记录待删除的结点的地址。
- 为了能够在删除tmp结点后继续遍历链表中其余的结点,使innerCur指针指向它的后继结点:innerCur=innerCur.next。
- 从链表中删除tmp结点。
实现代码如下:
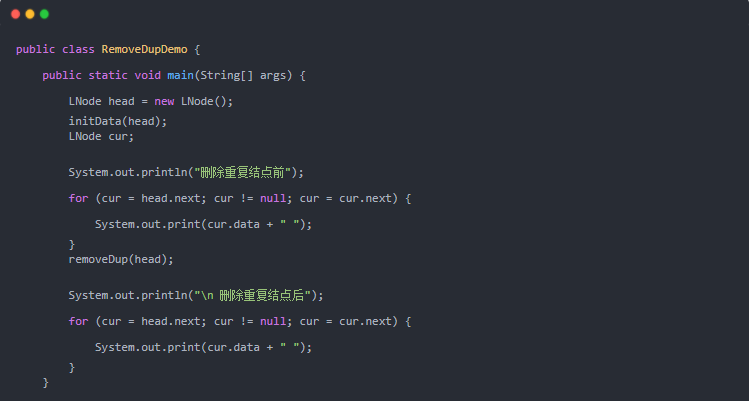
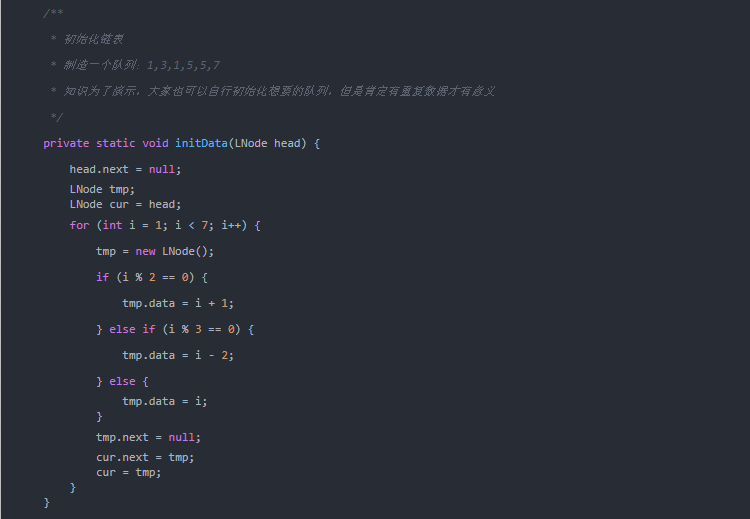
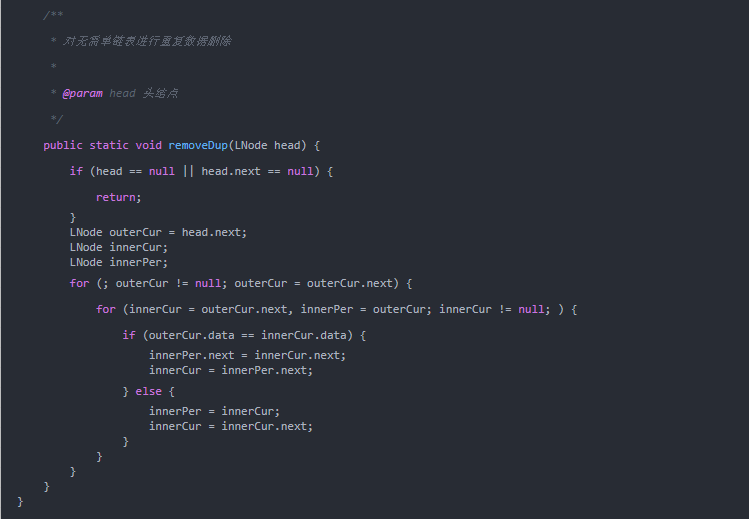
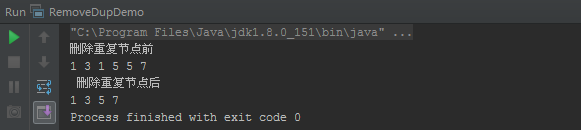
运行结果:
算法性能分析
由于这种方法采用双重循环对链表进行遍历,因此,时间复杂度为O(N^2)。其中,N为链表的长度。在遍历链表的过程中,使用了常量个额外的指针变量来保存当前遍历的结点、前驱结点和被删除的结点,因此,空间复杂度为O(1)。
递归法
主要思路为:对于结点cur,首先递归地删除以cur.next为首的子链表中重复的结点,接着从以cur.next为首的子链表中找出与cur有着相同数据域的结点并删除。
实现代码如下:
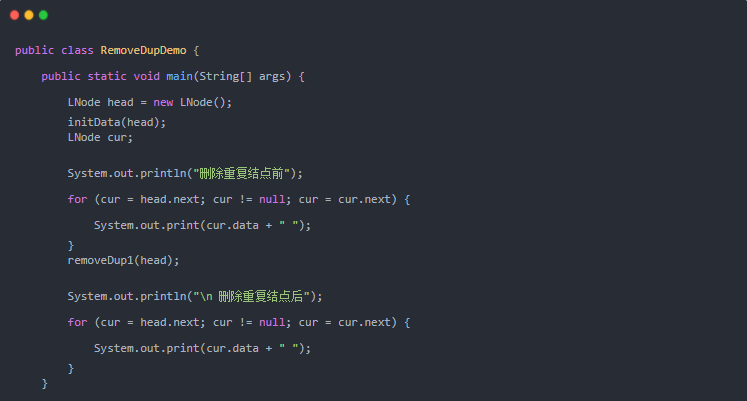
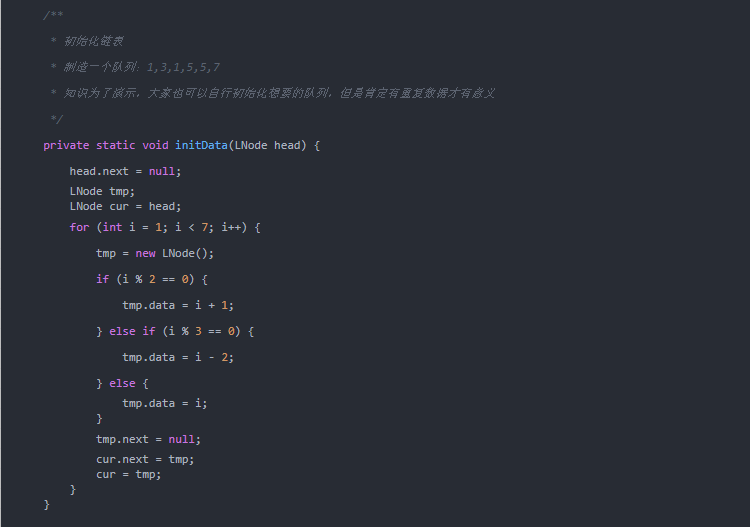
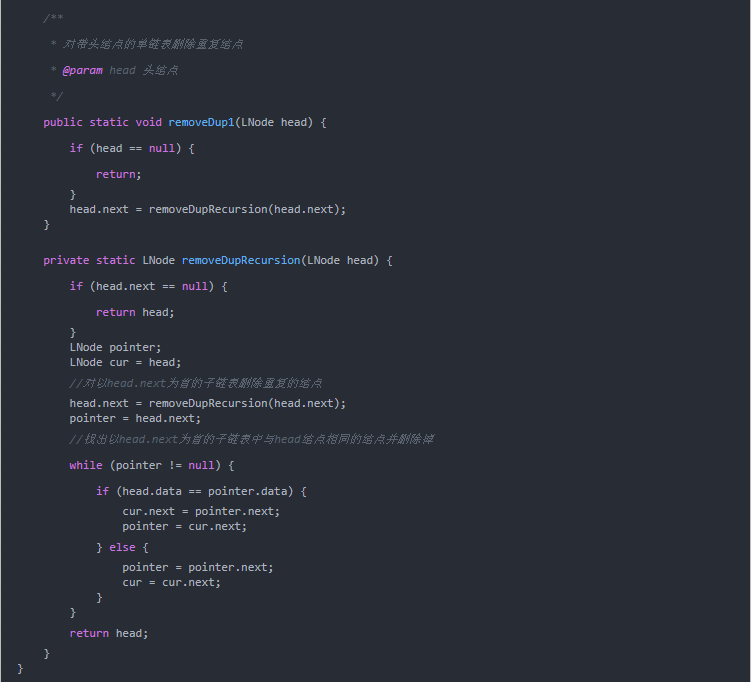
算法性能分析
这种方法与方法一类似,从本质上而言,由于这种方法需要对链表进行双重遍历,因此,时间复杂度为O(N^2)。其中,N为链表的长度。由于递归法会增加许多额外的函数调用,因此,从理论上讲,该方法效率比前面的方法低。
空间换时间
通常情况下,为了降低时间复杂度,往往在条件允许的情况下,通过使用辅助空间实现。
具体而言,主要思路如下。
- 建立一个HashSet,HashSet中的内容为已经遍历过的结点内容,并将其初始化为空。
- 从头开始遍历链表中的所以结点,存在以下两种可能性:
- 如果结点内容已经在HashSet中,则删除此结点,继续向后遍历。
- 如果结点内容不在HashSet中,则保留此结点,将此结点内容添加到HashSet中,继续向后遍历。
「引申:如何从有序链表中移除重复项?」
如链表:1,3、5、5、7、7、8、9
去重后:1,3、5、7、8、9
分析与解答
上述介绍的方法也适用于链表有序的情况,但是由于以上方法没有充分利用到链表有序这个条件,因此,算法的性能肯定不是最优的。本题中,由于链表具有有序性,因此,不需要对链表进行两次遍历。所以,有如下思路:用cur 指向链表第一个结点,此时需要分为以下两种情况讨论。
- 如果cur.data==cur.next.data,那么删除cur.next结点。
- 如果cur.data!=cur.next.data,那么cur=cur.next,继续遍历其余结点。
总结
对于无序单链表中,想要删除其中重复的结点(多个重复结点保留一个)。删除办法有按照顺序删除、使用递归方式删除以及可以使用空间换时间(HashSet中元素的唯一性)。
最近有读者想要分布式的项目,还有想要商城的,还有想要springboot,springcloud,k8s等等,这次直接分享几乎涵盖了我们java程序员的大部分技术桟,可以说真的非常全面了。强烈建议大家都上手做一做,而且以后肯定用的上。






















