












本文转载自公众号“读芯术”(ID:AI_Discovery)
这可能是你第一次听说“可解释人工智能”一词,但你一定很快就能理解它:可解释人工智能(XAI)是指构建人工智能应用程序的技术和方法,人们可以由此理解这些系统做出特定决策的“原因”。
换句话说,如果我们能从一个人工智能系统得到关于其内部逻辑的解释,那么这个系统就被认为是一个XAI系统。可解释性是人工智能界开始流行的一个新属性,我们将在下文讨论其在近几年出现的缘由。
首先,让我们深入探究这一问题的技术根源。
人工智能促进我们的生活
科技的进步必然使我们能够更方便地享受更好的服务。科技是生活中不可缺少的一部分,且肯定利大于弊,无论你喜欢科技与否,它对我们生活的影响只会与日俱增。
计算机、互联网和移动设备的发明使生活更加便捷高效。继计算机和互联网之后,人工智能已经成为生活新的增强剂。从50年代和60年代数学领域的努力尝试到90年代的专家系统,我们才取得了今天的成就。
我们可以在汽车上使用自动驾驶仪,使用谷歌翻译与外国人交流,使用无数的应用程序来润色我们的照片,使用智能推荐算法找到最好的餐厅。人工智能对生活的影响不断增强,现在已经成为生活中不可或缺的、毋庸置疑的助力。
另一方面,人工智能系统已经变得如此复杂,普通用户几乎不可能理解它如何运作。我敢说只有不足1%的谷歌翻译用户知道它是如何运行的,但是我们仍然信任这个系统,并且广泛使用。
我们应该了解这一系统是如何工作的,或者至少,应该能够在必要的时候获取它的相关信息。
过于注重准确性
数学家和统计学家们研究传统的机器学习算法已有数百年历史,如线性回归、决策树和贝叶斯网络。这些算法都非常直观,其发展先于计算机的发明。当你依据其中一种传统算法进行决策时,很容易生成解释。
然而,它们只在一定程度上达到了准确度。因此,传统算法的可解释度很高,但也算不上很成功。
后来,麦卡洛克-皮茨(McCulloch-Pitts)神经元发明后,发生了翻天覆地的变化。这一发展促使了深度学习领域的创立。深度学习是人工智能的一个分支领域,主要研究利用人工神经网络来复制大脑中神经元细胞的工作机制。
由于运算能力的提高以及开源深度学习框架的优化,我们逐渐能够构建高精确度性能的复杂神经网络。人工智能研究人员们开始竞争,以尽可能达到最高精确度水平。而这种竞争无疑帮助我们构建了伟大的人工智能产品,但同时付出的代价是:低解释性。
神经网络非常复杂且难以理解。它们可以用数十亿个参数来构建。例如,Open AI的革命性NLP模型,GPT-3,就拥有超过1750亿个机器学习参数;从这样一个复杂的模型中推导出任何一个推理都极具挑战。
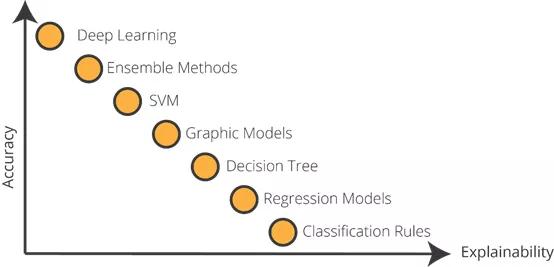
机器学习算法运行的精准度VS.可解释性
如你所见,一个人工智能开发人员依靠传统算法而非深度学习模型的损失良多。所以,我们看到越来越多的精确模型与日俱增,而其可解释性却越来越低。但是,我们需要可解释性更甚于以往。
越来越多的人工智能系统被应用于某些敏感领域
还记得以前人们在战争中使用真刀真枪吗。是的,一切都在改变,远超你的想象。智能AI无人机已经可以在没有人为干预的情况下干掉任何人。一些军队也已经有能力实施这些系统;但是,他们也对未知的结果感到担忧。他们不想依赖那些自己都不清楚运作原理的系统。事实上,美国国防部高级研究计划局已经有一个正在进行的XAI项目。
无人驾驶汽车是另一个例子。现在已经可以在特斯拉汽车上使用自动驾驶仪了。这对司机来说是极大的便利。但是,与之而来也有巨大的责任。当你的汽车遇到道德困境时,它会怎么做;在道德困境中,它必须在两个罪恶的抉择中选择损失较小的一个。
例如,自动驾驶仪是否应该牺牲一条狗来拯救一个路上的行人?你也可以在麻省理工学院的道德机器上一睹集体道德和个人道德。
日复一日,人工智能系统在更大程度上影响着我们的社会生活。我们需要知道它们在一般情况和特殊事件中如何做出决定。
人工智能的指数级增长可能会造成生存威胁
我们都看过《终结者》,目睹了机器如何具有自我意识,并可能毁灭人类。人工智能是强大的,它可以帮助我们成为一个多星球物种,同时也可能完全摧毁我们,就如《启示录》中的场景一样。
事实上,研究表明,超过30%的人工智能专家认为,当我们实现通用人智能(ArtificialGeneral Intelligence)时,结果要么糟糕,要么极其糟糕。所以,防止灾难性后果的最有力武器就是了解人工智能系统的工作方法,这样我们就可以使用制衡机制,就如限制政府权利过度一样。
解决人工智能相关争议需要推理和解释
由于过去两个世纪人权和自由的发展,目前的法律及条例已经要求在敏感领域有一定程度的可解释性。法律论证和推理领域也涉及可解释性的界限。
人工智能的应用程序仅是接管了一些传统的职业,但这并非代表它们的控制器就不负责提供解释。它们必须遵守同样的规则,也必须为其服务提供解释。一般法律原则要求在发生法律纠纷时(例如,当自动驾驶的特斯拉撞上行人)对自动化决策作出解释。
但是,一般规则和原则并不是要求强制性解释的唯一理由。我们也有一些当代的法律法规,规范了不同形式的解释权。
欧盟的《通用数据保护条例》(GDPR)已经定义了解释权,当公民受到自动化决策的约束时,有必要对人工智能系统的逻辑进行合理的解释。
另一方面,在美国,公民有权获得拒绝其信贷申请的解释。事实上,这种权利迫使信用评分公司在给客户评分时采用回归模型(这一模型更易于解释),以便他们能够提供强制性的解释。
消除人工智能系统的历史偏见需要可解释性
自古以来人类就有歧视现象,这也反映在收集的数据中。当一个开发人员训练一个人工智能模型时,他会给历史数据灌以所有偏见和歧视性元素。而如果观测有种族偏见,模型在进行预测时也会映射这些偏见。
巴特利特(Bartlett)的研究表明,在美国,至少有6%的少数族裔的信贷申请纯粹是由于歧视性惯例而被拒绝。因此,用这些具有偏见的数据来训练一个信用申请系统将对少数民族产生毁灭性的影响。
对一个社会而言,我们必须了解算法是如何运行的,以及如何才能消除偏见,这样才能保证社会自由、平等和博爱。
自动化业务的决策需要可靠性和信任度
从金融角度来说可解释性也是有意义的。当使用一个支持人工智能的系统来为组织的销售和市场营销工作建议具体的行动时,你可能会好奇它为何会如此建议。
决策者们必须明白为什么他们需要采取特定行动,因为他们将为此行动负责。这对实体企业和金融企业都意义重大。尤其是在金融市场,一个错误的举动会让公司付出高昂的代价。
如你所见,这些观点有力论证了为何我们需要可解释的人工智能。这些观点来自不同的学科和领域,如社会学、哲学、法学、伦理学和商科。因此,我们需要人工智能系统的可解释性



























