Hadoop的MR结构和YARN结构是大数据时代的第一代产品,满足了大家在离线计算上的需求,但是针对实时运算却存在不足,为满足这一需求,后来的大佬研发了spark计算方法,大大的提高了运算效率。
Spark的计算原理
spark的结构为:
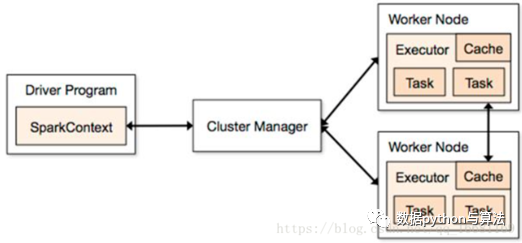
节点介绍:
- Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器负责分配资源,有点像YARN中ResourceManager那个角色,大管家握有所有的干活的资源,属于乙方的总包。
- WorkerNode:可以干活的节点,听大管家ClusterManager差遣,是真正有资源干活的主。从节点,负责控制计算节点,启动Executor或者Driver。
- Executor:在WorkerNode上起的一个进程,相当于一个包工头,负责准备Task环境和执行。
- Task:负责内存和磁盘的使用。Task是施工项目里的每一个具体的任务。
- Driver:统管Task的产生与发送给Executor的,运行Application 的main()函数,是甲方的司令员。
- SparkContext:与ClusterManager打交道的,负责给钱申请资源的,是甲方的接口人。
整个互动流程是这样的:
- 甲方来了个项目,创建了SparkContext,SparkContext去找ClusterManager申请资源同时给出报价,需要多少CPU和内存等资源。ClusterManager去找WorkerNode并启动Excutor,并介绍Excutor给Driver认识;
- Driver根据施工图拆分一批批的Task,将Task送给Executor去执行;
- Executor接收到Task后准备Task运行时依赖并执行,并将执行结果返回给Driver;
- Driver会根据返回回来的Task状态不断的指挥下一步工作,直到所有Task执行结束;
运行流程及特点为:
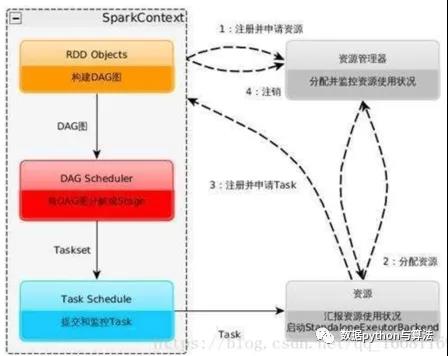
- Sparkcontext的作用:一是分发task,申请资源等功能外,更重要的一个功能是将RDD拆分成task,即绘制DAG图。
借用上图我们再来了解一下spark的运算过程:
- 构建Spark Application的运行环境,启动SparkContext;
- SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动StandaloneExecutorbackend;
- Executor向SparkContext申请Task;
- SparkContext将应用程序分发给Executor;
- SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行;
- Task在Executor上运行,运行完释放所有资源;
RDD计算案例
我们用一个案例来分析RDD的计算过程:
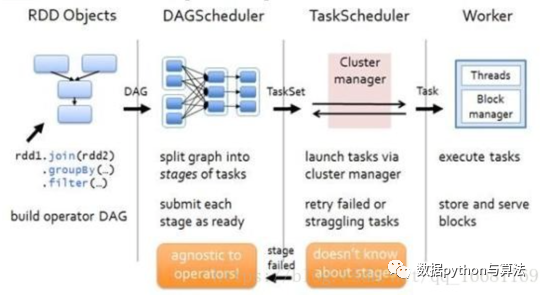
- 在客户端通过RDD构建一个RDD的图形,如图第一部分rdd1.join(rdd2).groupby(…).filter(…)。
- sparkcontext中的DAGScheduler会将上步的RDD图形构建成DAG图形,如图第二部分;
- TaskScheduler会将DAG图形拆分成多个Task;
- Clustermanager通过Yarn调度器将Task分配到各个node的Executer中,结合相关资源进行运算。
DAGScheduler对于RDD图形的划分是有一定规律的:
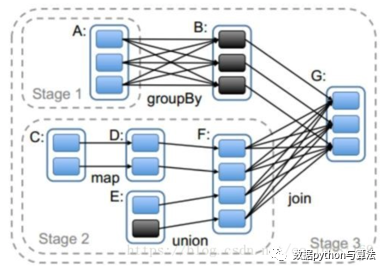
- stage的划分是触发action的时候从后往前划分的,所以本图要从RDD_G开始划分。
- RDD_G依赖于RDD_B和RDD_F,随机决定先判断哪一个依赖,但是对于结果无影响。
- RDD_B与RDD_G属于窄依赖,所以他们属于同一个stage,RDD_B与老爹RDD_A之间是宽依赖的关系,所以他们不能划分在一起,所以RDD_A自己是一个stage1;
- RDD_F与RDD_G是属于宽依赖,他们不能划分在一起,所以最后一个stage的范围也就限定了,RDD_B和RDD_G组成了Stage3;
- RDD_F与两个爹RDD_D、RDD_E之间是窄依赖关系,RDD_D与爹RDD_C之间也是窄依赖关系,所以他们都属于同一个stage2;
- 执行过程中stage1和stage2相互之间没有前后关系所以可以并行执行,相应的每个stage内部各个partition对应的task也并行执行;
- stage3依赖stage1和stage2执行结果的partition,只有等前两个stage执行结束后才可以启动stage3;
- 我们前面有介绍过Spark的Task有两种:ShuffleMapTask和ResultTask,其中后者在DAG最后一个阶段推送给Executor,其余所有阶段推送的都是ShuffleMapTask。在这个案例中stage1和stage2中产生的都是ShuffleMapTask,在stage3中产生的ResultTask;
- 虽然stage的划分是从后往前计算划分的,但是依赖逻辑判断等结束后真正创建stage是从前往后的。也就是说如果从stage的ID作为标识的话,先需要执行的stage的ID要小于后需要执行的ID。就本案例来说,stage1和stage2的ID要小于stage3,至于stage1和stage2的ID谁大谁小是随机的,是由前面第2步决定的。
Executor是最终运行task的苦力,他将Task的执行结果反馈给Driver,会根据大小采用不同的策略:
- 如果大于MaxResultSize,默认1G,直接丢弃;
- 如果“较大”,大于配置的frameSize(默认10M),以taksId为key存入BlockManager
- else,全部吐给Driver。