












在日常生活中,统计学无处不在,每个人、每件事似乎都可以使用统计数据加以说明。随着人类迈入大数据时代,统计学在方方面面更是发挥了不可或缺的作用。统计学思想,就是在统计实际工作、统计学理论的应用研究中,必须遵循的基本理念和指导思想。它们对统计学的发展起到了指导作用。
近日,哥伦毕业大学和阿尔托大学的两位知名统计学研究者撰文总结了过去 50 年最重要的统计学思想,包括反事实因果推理、bootstrapping 和基于模拟的推理、过参数化模型和正则化、多层次模型、通用计算算法、自适应决策分析、鲁棒性推理和探索性数据分析。除了详细描述这些统计学思想的具体概念和发展历程,研究者还概述了它们之间的共同特征、它们与现代计算和大数据之间的关系以及它们在未来如何发展和扩展。研究者表示,本文旨在激发人们对统计学和数据科学研究中更大主题的思考和讨论。

论文链接:https://arxiv.org/pdf/2012.00174.pdf
这篇论文在社区引起了热议,图灵奖得主、贝叶斯网络之父 Judea Pearl 等学者纷纷转推并发表自己的观点。他表示:「这篇论文将因果推理列入了统计学思想之一,与芝加哥大学统计系教授 Stephen Stigler 所著《统计学七支柱》中的观点截然不同。」
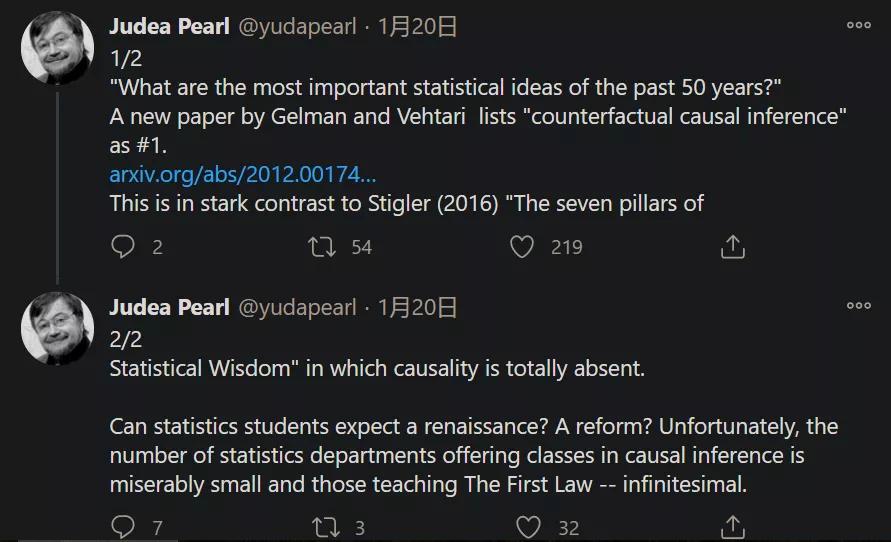
此外,需要指出的是,本文列出的 8 种统计学思想是根据经验和阅读文献进行分类的,并不是按照时间先后顺序或重要性进行排序。无论是在理论统计文献,还是在各个应用领域的实践中,这些统计学思想在 1970 年之前都有先例。但在过去的 50 年中,它们都得到了发展,并且已衍变出新的内容。下面一一阐述论文中列出的八个统计学思想。
过去 50 年最重要的统计学思想
反事实因果推理
该研究从统计学、计量经济学、心理测验学、流行病学和计算机科学中出现的一系列不同观点开始,这些观点都围绕着因果推理挑战展开。其主要思想是,因果识别是可能的,人们可以通过设计和分析严格地陈述这些假设,并以各种方式加以解决。关于如何将因果模型应用于实际数据的辩论仍在继续,但在过去的 50 年里,这一领域的研究使因果推断所需的假设更加精确,这又反过来促进了针对这些问题的统计方法的研究。
因果推理方法在不同的领域有不同的发展。在计量经济学领域,重点是从线性模型解释因果推理 (Imbens and Angrist, 1994);在流行病学中,重点是从观测数据进行因果推理(Greenland and Robins, 1986);心理学家已经意识到相互作用和不同的治疗效果之间的重要性(Cronbach, 1975);统计学中已经有了匹配和其他方法来调整和测量治疗组和对照组之间的差异 (Rosenbaum and Rubin, 1983);在计算机科学领域,已经有了很多关于因果推理的多维模型的研究(Pearl, 2009)。
这些研究中都有一个共同的主线,就是从反事实或潜在结果的角度对因果问题进行建模,这是一个很大的进步,超越了早期的评判标准,后者没有明确区分描述性推理和因果推理。主要研究包括 Neyman (1923)、Welch (1937)、 Rubin (1974)以及 Haavelmo (1973),还有 Heckman 和 Pinto (2015)的背景介绍。
Bootstrapping 和基于模拟的推理
在过去 50 年里,统计学的一个趋势是用计算取代数学分析。以 bootstrap 为例:在 bootstrap 中定义了一些估计器,并将其应用于一组随机重采样的数据集 (Efron, 1979, Efron and Tibshirani, 1993)。主要思想是将估计值视为数据的一个近似的充分统计量,并将 bootstrap 分布视为数据的抽样分布的近似。在概念层面上,有人呼吁将预测和重采样作为基本原则,从中可以得出偏差校正和收缩等统计操作(Geisser, 1975)。
计算资源的增加使得其他相关的重采样和基于模拟的方法也很流行。在置换测试中,通过对目标值进行随机变换,打破了预测值与目标值之间的依赖关系,生成重采样数据集。Parametric bootstrapping、前验和后验预测性检查 (Box, 1980, Rubin, 1984)、基于模拟的校准 (Talts et al., 2020) 都是从模型中创建复制的数据集,而不是直接从数据中重新采样。
过参数化模型和正则化
自 20 世纪 70 年代以来,统计学的一个重大变化是关于用大量参数拟合模型的思想,模型参数可能比数据点还多,并且使用一些正则化方法来获得稳定的估计和良好的预测。关于用大量的参数拟合模型的主要思想是获得非参数或高度参数化方法的灵活性,同时又能避免过拟合。正则化可以作为参数或预测曲线上的惩罚函数来实现(Good and Gaskins, 1971)。
参数丰富的模型的早期示例包括 Markov 随机场(Besag, 1974)、样条曲线(splines)(Wahba 和 Wold, 1975, Wahba, 1978)和高斯过程(O'Hagan, 1978),然后是分类树和回归树(Breiman 等人, 1984)、神经网络(Werbos, 1981;Rumelhart、Hinton 和 Williams, 1987;Buntine 和 Weigend, 1991;MacKay, 1992;Neal, 1996),小波收缩(wavelet shrinkage )(Donoho 和 Johnstone, 1994)、lasso/horseshoe 等其他最小二乘法的变体(Dempster、Schatzoff 和 Wermuth, 1977 年;Tibshirani, 1996 年;Carvalho、Polson 和 Scott, 2010 年),此外还有支持向量机(Cortes 和 Vapnik, 1995 年)以及相关理论(Vapnik, 1998 年) 。
所有这些模型都具有随样本量和参数而扩展的特征,这些参数并不总是可以直接解释,而只是较大预测系统的一部分。在贝叶斯方法中,可以先在函数空间中考虑先验,然后间接导出模型参数的相应先验。
在有足够的计算资源之前,以上许多模型的使用都受到限制。但在图像识别(Wu 等人,2004)和深度神经网络(Bengio、LeCun 和 Hinton, 2015 年;Schmidhuber, 2015 年)领域,过参数化模型得以继续发展。Hastie、Tibshirani 和 Wainwright(2015)将大部分此类工作归化为稀疏结构的估计,但作者认为归纳为正则化更为合适,因为它还包括适合于数据支持范围的密集模型。这类工作大部分是在统计之外完成的,方法包括非负矩阵分解(Paatero 和 Tapper, 1994)、非线性降维(Lee 和 Verleysen, 2007)、生成对抗网络(Goodfellow 等, 2014)和自动编码器(Goodfellow、Bengio 和 Courville, 2016 年):这些都是用于查找结构和分解的无监督学习方法。
随着统计方法的发展及其在更大数据集中的应用,研究人员开发了多种方法对各种拟合推断进行精调、适应和组合,包括 stacking(Wolpert, 1992)、贝叶斯模型平均(Hoeting 等, 1999)、boosting(Freund 和 Schapire, 1997)、梯度提升(Friedman, 2001)和随机森林(Breiman, 2001)。
多层次模型
多层或分层模型的参数会随组变化,从而使模型能够适应群集采样。纵向研究、时间序列横截面数据、元分析(meta-analysis)和其他结构化设置。在回归语境中,可以将多层次模型视为特定的参数化协方差结构,也可以视为概率分布,其中参数的数量与数据成比例地增加。
多层次模型可以视为贝叶斯模型,因为它们包括未知潜在特征或变化参数的概率分布。相反,贝叶斯模型具有多层次结构,具有给定参数的数据和给定超参数的参数分布。
通用计算算法
借助现代计算,建模方面的改进才成为了可能。这不仅包括更大的内存、更快的 CPU、高效的矩阵计算、用户友好的语言以及其他计算创新,还有十分关键的部分是用于高效计算的统计算法上的改进。
过去五十年来的创新统计算法是基于统计问题的结构而发展的。在统计学的历史上,数据分析、概率建模和计算的进步一直会相互结合,新模型让创新计算算法和新的计算技术打开了面向更复杂模型和新推论观点的大门。通用的自动推理算法允许解耦模型的开发,因此更改模型不需要更改算法的实现。
自适应决策分析
从 20 世纪 40 年代到 60 年代,决策理论通常通过效用最大化 (Wald, 1949, Savage, 1954)、错误率控制(Tukey, 1953, Scheff´e, 1959) 和经验贝叶斯分析 (Robbins, 1959, 1964) 作为统计的基础。近几十年来,在贝叶斯决策理论 (Berger, 1985) 和错误发现率分析 (Benjamini and Hochberg, 1995) 中都看到了后续工作的进展。决策理论也受到了外界关于启发式算法和人类决策偏见的心理学研究 (Kahneman, Slovic, and Tversky, 1982, Gigerenzer and Todd, 1999) 的影响。
人们还可以将决策视为统计应用领域,统计决策分析的一些重要发展涉及贝叶斯优化 (Mockus, 1974, 2012, Shariari et al., 2015) 和强化学习 (Sutton and Barto, 2018),这与行业中 A/B 测试实验设计的复兴和工程应用中的在线学习有关。计算科学的最新进展是能够使用诸如高斯过程和神经网络之类的高度参数化模型作为自适应决策分析功能的先验,并可以在模拟环境中进行大规模的强化学习,例如创建人工智能控制的机器人、生成文本和参与围棋(Silver et al., 2017) 之类的游戏。
鲁棒推理
鲁棒性的概念是现代统计的核心,它是一种即使在假设不正确的情况下也能使用模型的思想。开发在实际情况与假设不符的情况下也能良好使用的模型是统计理论中重要的一部分。Tukey (1960)总结了该领域的早期研究,Stigler (2010)的研究总结了历史性回顾。继 Huber (1972)等人的理论工作之后,研究者又开发出行之有效的方法,这些方法在实践中,尤其是在经济学中尤为重要,人们也对统计模型的不完善之处有了敏锐的认识。
一般而言,鲁棒性在统计研究中的主要影响并不在于开发特定方法,而在于它影响了在 Bernardo 和 Smith (1994)称为 M-open 世界(其中数据生成过程不属于拟合概率模型的类别)的情况下评估统计程序的思想。Greenland (2005)认为研究者应该明确说明在传统统计模型中不包含的误差源。鲁棒性问题与许多现代统计数据所特有的密集参数化模型有关,这更普遍地影响了模型评估(Navarro, 2018)。
探索性数据分析
继 Tukey (1962)之后,探索性数据分析的支持者重点说明了渐近理论的局限性以及开放式探索和通信 (Cleveland, 1985) 的好处,并且阐明了超越统计理论的更一般的数据科学观点(Chambers, 1993, Donoho, 2017)。这符合统计建模的观点,即更多的关注发现而不是检验固定假设。这不仅影响了图形化方法的发展,也将统计领域从定理证明走向更开放、更健康的角度,因为它是从科学领域的数据中学习。以医学统计学领域为例,Bland 和 Altman 于 1986 年发表的一篇高被引论文提出用于数据对比的图形化方法,替代了关联性和回归分析。
此外,研究人员试图形式化定义探索性数据分析:「探索性模型分析」(Unwin, Volinsky, and Winkler, 2003, Wickham, 2006)有时被用来捕获数据分析过程的实验属性,研究者们也一直致力于在模型构建和数据分析的过程中涵盖可视化的工作(Gabry et al., 2019, Gelman et al., 2020)。
这些统计学思想之间的关联
研究者认为,上述这八种统计学思想之所以重要,是因为它们既解决了现有问题,还创建了新的统计思考和数据分析方式。换言之,每一种思想都不失为一部「法典」,其方法超越狭义的统计学范畴,更像是一种「研究品味」或者「哲学思想」。
这些统计学思想彼此之间存在着哪些关联和交互呢?
Stigler (2016)曾说过,一些明显不同的统计学领域背后存在着某些相同的主题。这种互联的观点也可以应用于最近的研究发展。
举例而言,正则化过参数化模型可以使用机器学习元算法进行优化,反过来又可以获得对污染(contamination)具有鲁棒性的推理。这些关联可以通过其他方式表示,鲁棒性回归模型对应混合分布,而混合分布又可以被视为多层次模型,并且可以通过贝叶斯推理进行拟合。深度学习模型不仅与一种多层逻辑回归有关,还与样条曲线和支持向量机中使用的复现核心希尔伯特(Hilbert)空间相关。
此外,特定统计模型又与文中列出的八种统计学思想存在什么联系呢?研究者这里提及的是有影响力的研究工作,如风险回归、广义线性模型、空间自回归、结构方程模型、潜在分类、高斯过程和深度学习等。如上文所述,在过去 50 年里,统计推理和计算领域出现了许多重要的发展,这些进展都受到了文中谈论的新模型和推理思想的启发和推动。应该看到,模型、方法、应用和计算彼此结合,息息相关。
最后,研究者表示可以将统计学方法的研究与自然科学、工程学中的统计应用趋势联系起来。他们认为,生物学、心理学、经济学和其他科学领域可能出现复现危机或可复现性革命,而这些领域的巨大变化需要根据统计资料得出结论。
作者简介
Andrew Gelman,哥伦比亚大学统计学与政治学教授,著名的统计学家。他于 1990 年获得哈佛大学统计学博士学位。他曾三次荣获美国统计协会颁发的杰出统计应用奖(Outstanding Statistical Application award),2020 年当选美国 AAAS 院士。他还著有《贝叶斯数据分析》(Bayesian Data Analysis)等书籍。谷歌学术中论文总引用量超过 12 万。
Aki Vehtari,阿尔托大学计算概率建模副教授,主要研究兴趣包括贝叶斯概率理论与方法、贝叶斯工作流、概率规划、推理与模型诊断、模型评估与选择、高斯过程以及分层模型等。他还著有《Regression and other stories》和《Bayesian Data Analysis》等书籍。谷歌学术中论文总引用量近 4 万。

















