现在的模型动辄数百、数千亿参数,普通人训不动怎么办?
前不久,谷歌发布了参数量为 1.6 万亿的语言模型Swith Transformer,将 GPT-3 创下的参数量记录(1750 亿)推至新高。这些大模型的出现让普通研究者越发绝望:没有「钞能力」、没有一大堆 GPU 就做不了 AI 研究了吗?
在此背景下,部分研究者开始思考:如何让这些大模型的训练变得更加接地气?也就是说,怎么用更少的卡训练更大的模型?
为了解决这个问题,来自微软、加州大学默塞德分校的研究者提出了一种名为「 ZeRO-Offload 」的异构深度学习训练技术,可以在单个 GPU 上训练拥有 130 亿参数的深度学习模型,让普通研究者也能着手大模型的训练。与 Pytorch 等流行框架相比,ZeRO-Offload 将可训练的模型规模提升了 10 倍,而且不需要数据科学家对模型做出任何改变,也不会牺牲计算效率。

论文链接:https://arxiv.org/pdf/2101.06840.pdf
ZeRO-Offload 通过将数据和计算卸载(offload)至 CPU 来实现大规模模型训练。为了不降低计算效率,它被设计为最小化与 GPU 之间的数据往来,并在尽可能节省 GPU 内存的同时降低 CPU 的计算时间。因此,对于一个参数量为 100 亿的模型,ZeRO-Offload 可以在单个 NVIDIA V100 GPU 上实现 40 TFlops/GPU。相比之下,使用 PyTorch 训练一个参数量为 14 亿的模型仅能达到 30TFlops,这是在不耗尽内存的情况下所能训练的最大模型。ZeRO-Offload 还可以扩展至多 GPU 设置并实现线性加速,最多可在 128 个 GPU 上实现近似线性加速。
此外,ZeRO-Offload 还可以和模型并行一起使用,在一个 DGX-2 box AI 服务器上训练参数量超 700 亿的模型。与单独使用模型并行相比,这一参数量实现了 4.5 倍的规模提升。
在下文中,我们将结合 Medium 博主 LORENZ KUHN 的一篇博客来详细了解这篇论文。
ZeRO-Offload 是什么?
ZeRO-Offload 是一种通过将数据和计算从 GPU 卸载到 CPU,以此减少神经网络训练期间 GPU 内存占用的方法,该方法提供了更高的训练吞吐量,并避免了移动数据和在 CPU 上执行计算导致的减速问题。
借助 ZeRO-offload,使用相同的硬件能训练以往 10 倍大的模型,即使在单个 GPU 上也是如此。比如在一个 32GB RAM 的 V100 GPU 上训练百亿参数的 GPT-2。
此外,ZeRO-offload 还能实现在多 GPU 设置中的近似线性扩展。
对于研究者来说,ZeRO-offload 适用的情况包括:
想训练更大的模型,或者想更快地训练现在的模型,因为 ZeRO-offload 允许训练更大的 batch size;
你正在使用 PyTorch,并且愿意 / 能够使用微软的 DeepSpeed 库(ZeRO-offload 的其他实现形式暂未推出),你也可以尝试根据官方实现自行调整;
愿意接受一些建模时的限制,比如当前版本的 ZeRO-Offload 需要搭配使用 Adam 的混合精度训练。
如何使用?
ZeRO-Offload 在微软的 DeepSpeed 库中实现,官方实现地址:https://github.com/microsoft/DeepSpeed/blob/6e65c2cc084ecfc393c67a2f64639e8d08d325f6/deepspeed/runtime/zero/stage2.py。
在 DeepSpeed 中设置完毕后,使用 ZeRO-Offload 就不需要太多额外的工作了,只需要修改一些标志和配置文件。
目前,Hugging Face 的 transformers 库与 DeepSpeed 进行了实验性集成,使用方法和基准测试结果参见:https://huggingface.co/blog/zero-deepspeed-fairscale。
Facebook 研究院的 fairscale 有 ZeRO 的部分实现,ZeRO-Offload 正是基于 ZeRO 这一多 GPU 内存优化方法构建的。目前还不支持 CPU 卸载。
ZeRO-Offload 的工作原理
ZeRO-Offload 是基于 Zero Redundancy Optimizer (ZeRO) 构建的。ZeRO 是微软在 2020 年 2 月提出的一种万亿级模型参数训练方法,用于数据并行和模型并行训练中的内存优化,其中梯度、参数和优化器状态分布在多 GPU 内存中,没有任何冗余。这使得 GPU 之间的通信开销保持在比较低的状态。
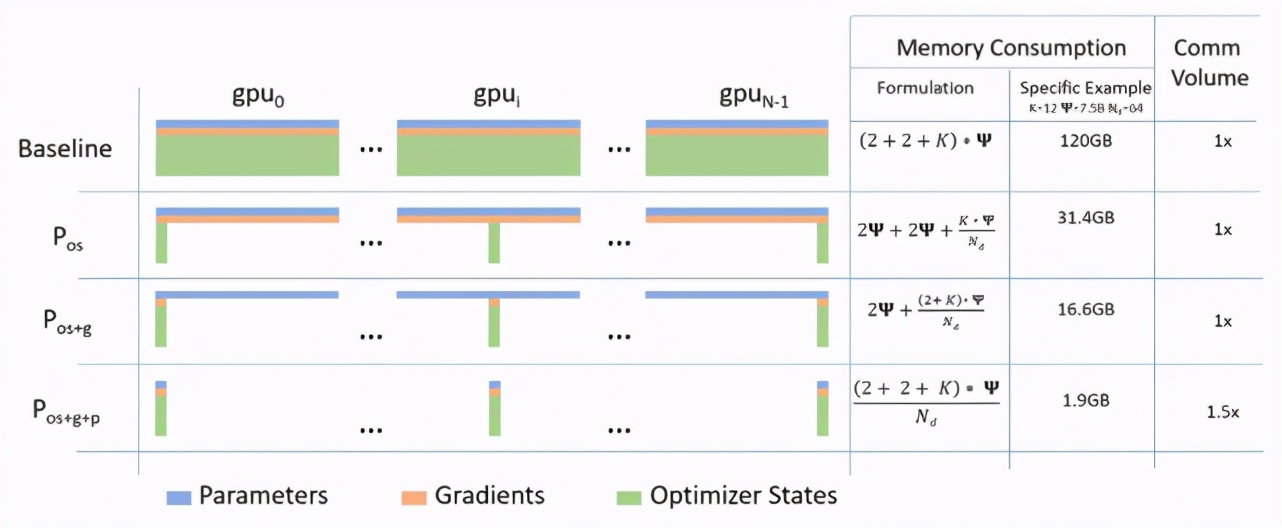
与标准数据并行基准相比,ZeRO 在三个阶段中节省的内存和通信用量。
让我们来回顾一下 ZeRO:
为了解决数据并行和模型并行存在的问题,ZeRO 提供了三阶段的优化方法,分别为优化器状态分割、梯度分割、参数分割,三个阶段按顺序实施。
在优化器分割状态:ZeRO 降低了 3/4 的内存,通信量和数据并行相同;
加入梯度分割:降低了 7/8 的内存,通信量和数据并行相同;
加入参数分割:内存减少与数据并行度呈线性关系。例如,在 64 个 GPU 上进行分割的时候,可以将内存降至 1/64。在通信量上有 50% 的提升。
在去年 9 月份的博客中,微软这么介绍 ZeRO-Offload:
ZeRO-Offload 继承了 ZeRO-2 的优化器状态和梯度分割。但与 ZeRO-2 不同的是,ZeRO-Offload 不在每块 GPU 上保持优化器状态和梯度的分割,而是将二者卸载至主机 CPU 内存。在整个训练阶段,优化器状态都保存在 CPU 内存中;而梯度则在反向传播过程中在 GPU 上利用 reduce-scatter 进行计算和求均值,然后每个数据并行线程将属于其分割的梯度平均值卸载到 CPU 内存中(参见下图 g offload),将其余的抛弃。一旦梯度到达 CPU,则每个数据并行线程直接在 CPU 上并行更新优化器状态分割(参见下图 p update)。
之后,将参数分割移回 GPU,再在 GPU 上执行 all-gather 操作,收集所有更新后的参数(参见下图 g swap)。ZeRO-Offload 还利用单独的 CUDA 流来穷尽通信与计算中的重叠,从而最大化训练效率。
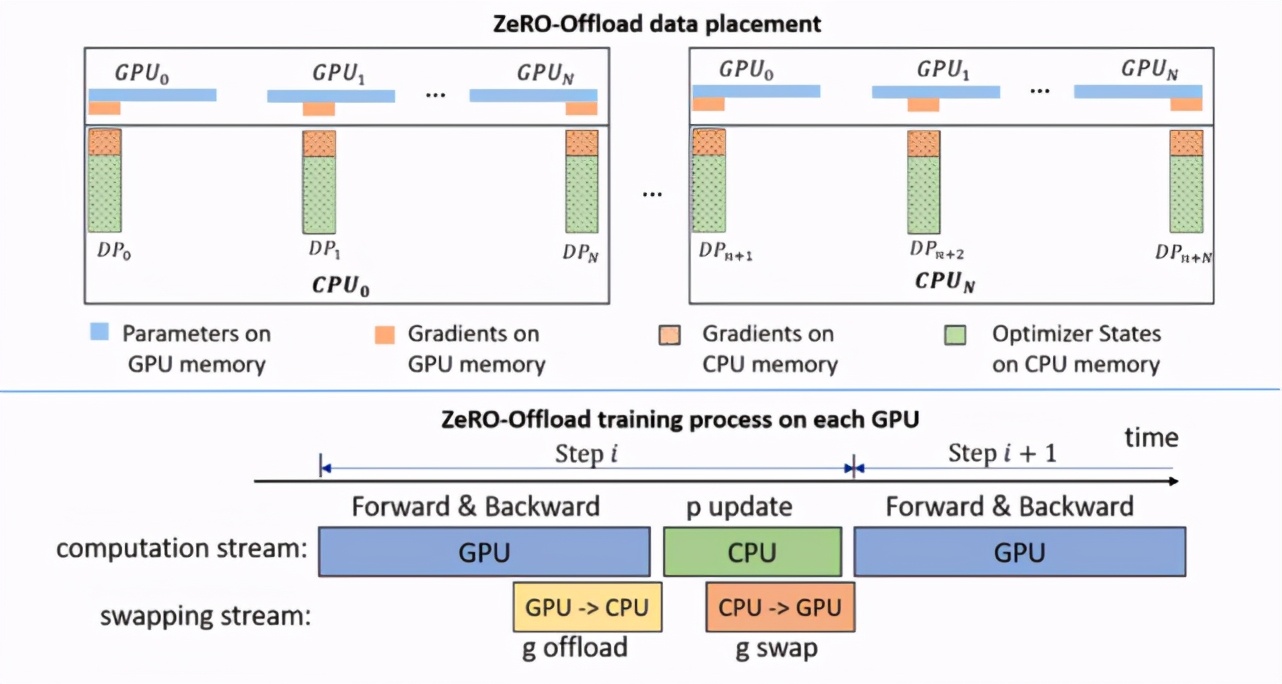
ZeRO-Offload 概览。
值得注意的是,ZeRO-Offload 专为使用 Adam 的混合精度训练而设计。也就是说,当前版本的 ZeRO-Offload 使用 Adam 的优化版本 DeepCPUAdam。其主要原因是避免 CPU 计算成为整个过程中的瓶颈。DeepCPUAdam 的速度是 Adam PyTorch 实现的 6 倍。
实验结果
最后来看一下 ZeRO-Offload 论文中提供的一些实验结果。
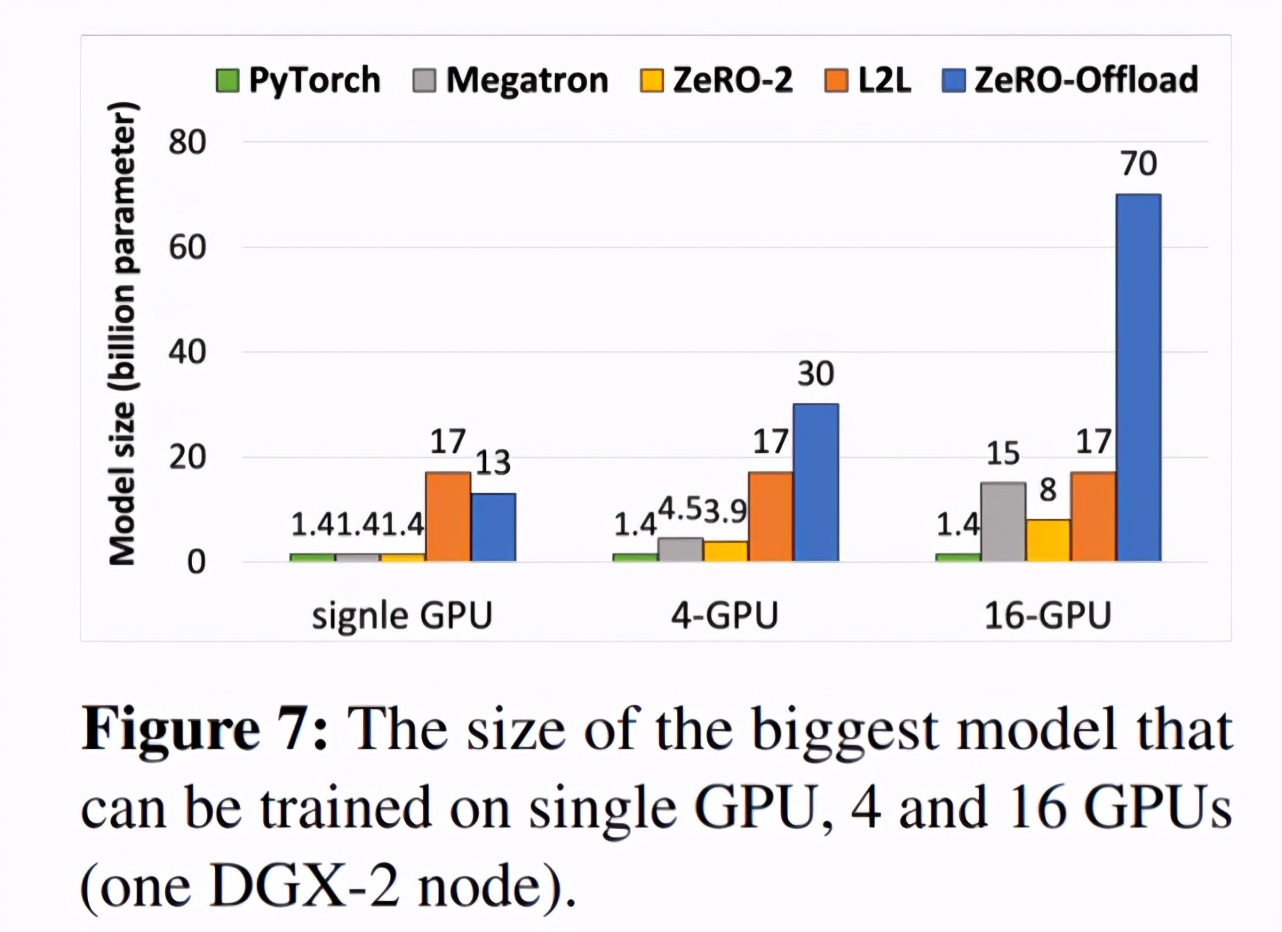
下图 7 展示了利用 ZeRO-Offload 技术在 1 个、4 个或 16 个 GPU(一个 DGX-2)上可以训练的最大模型情况。
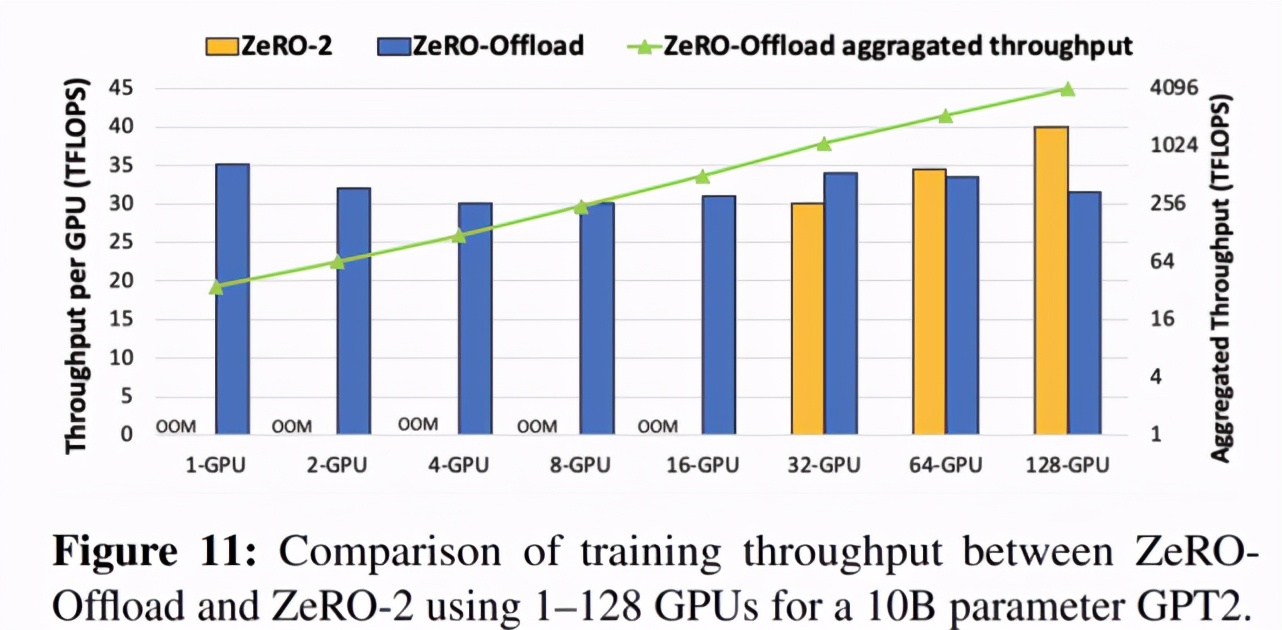
下图 11 展示了每个 GPU 的吞吐量随 GPU 数量增加而呈现的变化情况。可以看出,在 GPU 数量逐渐增加至 128 个的过程中,ZeRO-Offload 几乎可以实现吞吐量的线性加速。
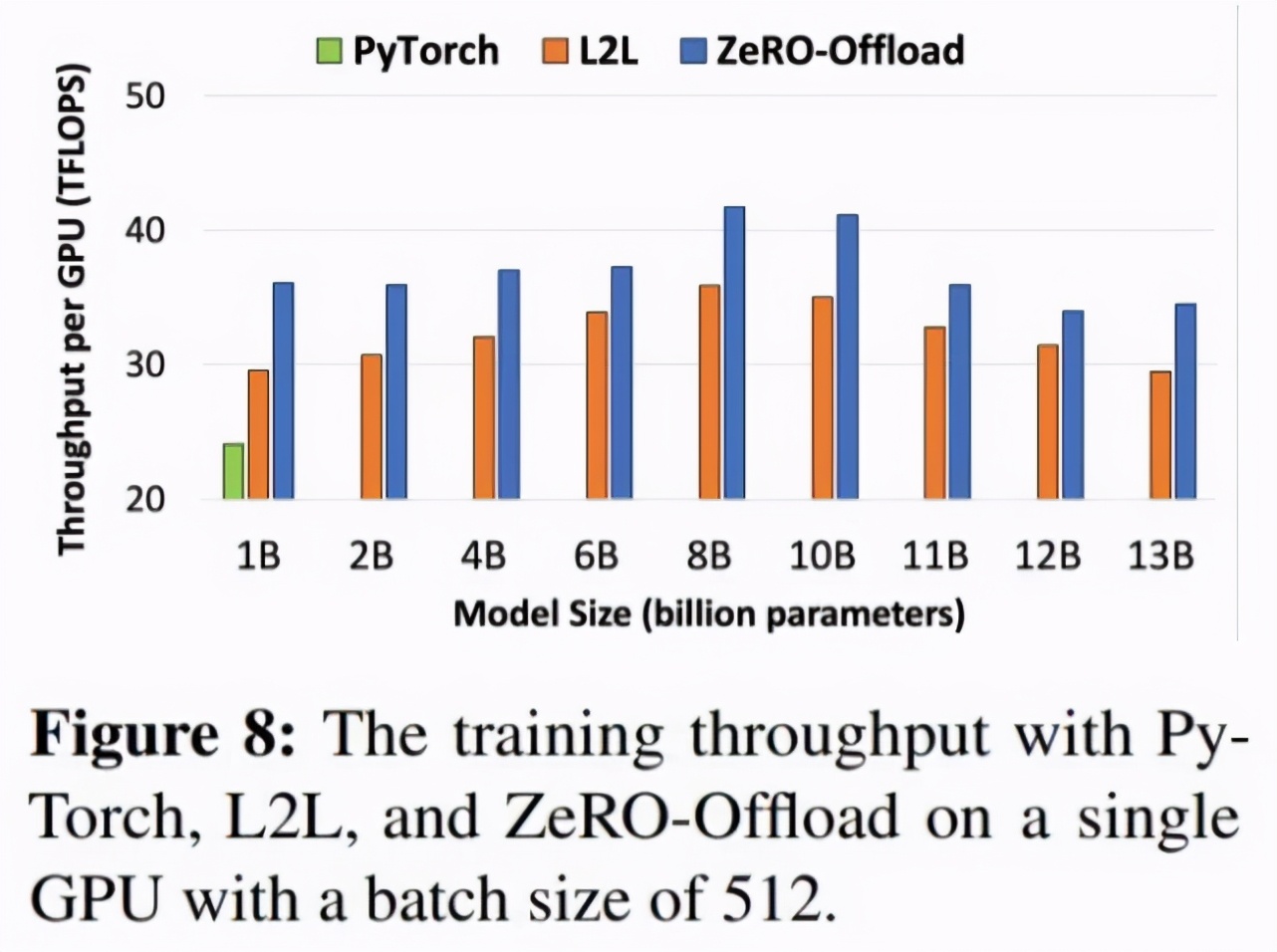
下图 8 展示了使用 PyTorch、L2L 和 ZeRO-Offload 实现的每个 GPU 吞吐量差异。从中可以看出,利用 ZeRO-Offload 实现的每个 GPU 吞吐量比 L2L 平均高出 14%(最多高出 22%)。