本文转载自微信公众号「新钛云服」,作者祝祥 。转载本文请联系新钛云服公众号。
介绍
Ceph是在云环境中最常使用的分布式存储系统。设计初衷是提供较好的性能、可靠性和可扩展性。
Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。
Ceph最令人津津乐道的是,Ceph在一个统一的存储系统中同时提供了对象存储、块存储和文件存储,即Ceph是一个统一存储,能够将企业企业中的三种存储需求统一汇总到一个存储系统中,并提供分布式、横向扩展,高度可靠性的存储系统,Ceph存储提供的三大存储接口。
I/O拥塞是Ceph运维中最常见的问题,常常会影响到生产业务,极端情况会导致存储集群的宕机。
I/O瓶颈则会影响OpenStack上的应用程序性能,即使系统仍然在正常运行,但是I/O的瓶颈会导致所有突发的I/O任务都会卡死。
本文将会解释为什么会在Ceph上会遇到这种情况,以及如何修改对应的参数,从而提高Ceph的稳定性以及对应的I/O性能。
ceph scrubbing
CEPH使用两种清理方式来检查存储运行状况。清理操作默认情况下每天都会执行。
- normal scrubbing:捕获OSD错误或文件系统错误。如上图所示,该操作不耗资源,不影响I/O性能。
- deep scrubbing: 比较PG对象中的所有数据。它会查找磁盘上的损坏的扇区。此处理是I/O密集型的。对I/O影响比较大。
上述指标历史记录中显示的I/O性能是由于每天从凌晨0:00到7:00进行的深度清理过程导致的。如果需要详细了解这一过程,请看下面的配置以及参数说明。下表简单列出了清理的相关参数,本文也会就这些参数提供部分说明。
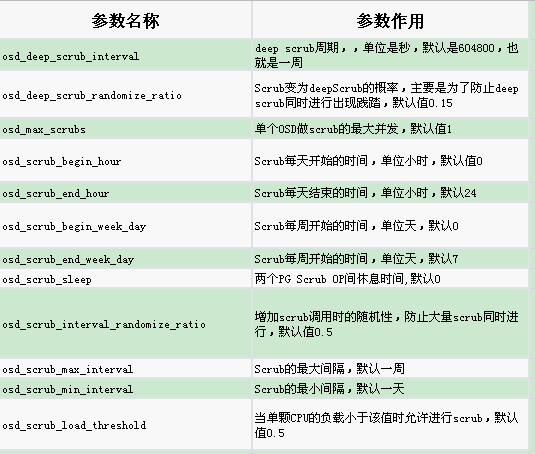
osd scrub begin/end hour :这些参数定义了清理时间窗口。以我们的环境为例,一般我们会计划在凌晨0点到7点之间进行清理任务。深度清理需要较长时间,如果最后一次的深度清理在早上7点之前开始,则处理的结束时间很可能会在大约1小时后。这也就是为什么我们的环境I/O在会在早上7点后降低,但在8点之后恢复为较高的原因。
正确设置Ceph有关的清理时间窗口非常重要。避开业务高峰期,选择业务低谷期间进行深度清理。如果业务是区域性的和基于人工,那么每夜进行一次处理是很有必要的。如果全天业务负载都很均衡,那么全局时间窗口(从0am到24pm)看起来更合适。
osd deep scrub interval:该参数定义了在PG上执行深度清理的时间周期。默认设置是每周一次。这意味着,当深度清理的计划开始工作时,它将标记所有未深度清理的PG,一直到该批次所有PG的深度清理任务完成。基本上,并行深度清理的级别与该参数和时间窗口有关。一周一次深度清理是比较保守的。
经过一番验证,哪怕是深度清理的时间间隔为1周,似乎也没有在4天之前进行过任何PG的深度清理。如果我们想要延长时间段或时间窗口,那么如果PG的处理频率超过预期的周期,我们将无法解决问题。这一假设有部分是正确的,但也有部分是错误的。在CEPH代码中可以找到有关这种过度处理的说明:
- scrubber.time_for_deep = ceph_clock_now() >=
- info.history.last_deep_scrub_stamp + deep_scrub_interval;
- bool deep_coin_flip = false;
- // If we randomize when !allow_scrub && allow_deep_scrub, then it guarantees
- // we will deep scrub because this function is called often.
- if (!scrubber.time_for_deep && allow_scrub)
- deep_coin_flip = (rand() % 100) < cct->_conf->osd_deep_scrub_randomize_ratio * 100;
- scrubber.time_for_deep = (scrubber.time_for_deep || deep_coin_flip);
基本上,深度清理也依赖于第四个参数,当前的官方文档尚未说明:
osd_deep_scrub_randomize_ratio: 随机执行深度清理的概率,可设置0.01 ,值越大,清理概率也越大,也容易影响业务。这个不受osd_deep_scrub_interval影响,但会在osd_scrub_begin_hour—osd_scrub_end_hour之间执行
在这种情况下,初始设置为15%。假设每天进行一次深度清理任务分配,那么则意味着每周都会通过随机过程选择一个PG。换句话说,从统计学上讲,这意味着> 50%的PG将每周处理两次。这就是为什么所有PG在4天的时间内(即使间隔为1周)都进行了处理的原因。
如果您在不更改osd_deep_scrub_randomize_ratio的情况下更改osd deep scrub interval,则并不会减少清理的工作量。因此,通常需要将这两个参数同步使用。
osd_deep_scrub_randomize_ratio的目标是将深度清理操作线性化,否则在PG创建的每个周期内我们可能会有比较大的I/O峰值,即使间隔一个又一个周期时间,这依然可能会越来越线性化。当随机因素对应于间隔时间(基本为一周的15%)时,这将在PG深度清理分布中形成线性关系。但工作量会增加大约150%。因此,当PG深度清理任务被分配,就可以正确处理PG的过期时间,从而降低整个调度的工作量。另一种工作方式是使用一个概率来定义周期(统计的方式),并将该周期用作未处理的PG的垃圾收集器。在我看来,这是一个很好的设置,例如,随机地使用5%的概率统计处理PG,每个PG大约3周,间隔1个月。
分析scrub速度
了解您的清理和深度清理的速率对于了解系统性能瓶颈并计算正常时间来处理清理任务很重要。对于后续的事件回顾与追溯非常有效。
此命令提供PG状态和上次清理/深度清理的时间。
- [~] ceph pg dump
您可以查看PG最早深度清理时间:
- [~] ceph pg dump | awk '$1 ~/[0-9a-f]+\.[0-9a-f]+/ {print $25, $26, $1}' | sort -rn
浅度清理
- [~] ceph pg dump | awk '$1 ~/[0-9a-f]+\.[0-9a-f]+/ {print $22, $23, $1}' | sort -rn
您可以按时间过滤以获取给定时间处理的PG数量,因此您每天可以处理一定数量的PG进行清理。
- [~] ceph pg dump | awk '$1 ~/[0-9a-f]+\.[0-9a-f]+/ {print $25, $26, $1}' | sort -rn | grep 2020-XX-YY | wc
您可以更改ID,以进行浅度清理。
这些信息对于了解Ceph系统是否正常以及是否达到瓶颈是很重要的,因为在较短的时间范围内有很多任务需要运行,比如随机比率太高,并且您每天有太多的清理操作。
进一步配置scrub参数
以下是其他一些参数将对负载产生影响,因为一旦我们定义了要执行的任务,就需要做好计划,然后合理执行。
- osd max scrubs: 表示单个OSD(驱动器)可以进行的最大清理次数。通常为1。但是您可以在同一主机上的不同OSD上进行多并发清理操作。这可能会影响Ceph全局I/O性能,尤其是在驱动器硬盘之间共享总线时。
清理是按chunk组织的。如果chunk大小由两个值定义:** osd scrub chunk min和osd scrub chunk max。这似乎是一个批处理操作,但目前尚不清楚对于一个chunk是否同时包含深度清理和浅度清理。两个chunk之间的处理由osd scrub sleep**设置的时间进行分开。此参数没有描述的单位,因此了解如何使用它有点复杂。默认设置为0.1(10%)。
优先级
CEPH 优先处理优先级较高的I/O任务。这样,我们就可以进行清理操作的同时,也不会对用户I/O造成太大影响。该数值越大,优先级越高,任务也越优先。涉及不同的优先级参数:
- osd requested scrub priority:是手动启动的清理(浅度与深度)操作的优先级。这很重要,大家通常都会修改。默认值为120,已经高于用户优先级。因此,对默认场景而言,并不推荐修改该参数。
- osd scrub priority:是自动计划的清理(浅度和深度)操作的优先级。该值默认为5。4为推荐的最佳值。
- osd client op priority: 是客户端I/O的优先级。最大值为63。它也是默认值。
块大小
块大小读取访问性能也会影响全局清理的性能。osd deep scrub stride参数设置要读取的块大小。默认值为512KB(524288)。该参数对于固态硬盘,块大小在16KiB以上并不重要。对于512KiB机械磁盘,这是一个比较好的调整参数,您可以使用1MiB或2MiB块提高吞吐量。
系统负载
osd scrub load threshold参数允许在系统负载(cpu loadavg)高于给定限制值时停止清理动作。通常,这有助于在I/O密集操作期间停止清理动作。但是scrub本身也会产生负载,因此在我看来,正确调整此参数有点复杂。对于CPU较小的CEPH服务器,却很有意义的。
清理调度
还有一件还不清楚的事情:何时执行清理操作的调度计划?是在每个批处理窗口上(每天一次)还是在每个chunk快满的时候才执行?在这种情况下,系统如何确保按不同的时间段内处理所有PG。这些信息是理解随机PG选择在清除调度中的影响的关键点。官方文档中对这些说明非常少。
常用的配置命令
该配置是每个OSD附带的。以下列出了一个OSD的默认参数:
- ceph config show-with-defaults osd.x # with x a OSD number
在所有OSD上查看参数
- ceph tell osd.* config get osd_deep_scrub_randomize_ratio
其他一些用于了解有关OSD和磁盘性能的命令或工具。有时候,可以发现IO清理问题实际上很可能是底层IO性能问题。
- hdparm -Tt /dev/sdx
- ceph tell osd.x bench -f plain
最后
随着Ceph集群数据量和集群规模逐渐扩大,在日常维护中,我们经常遇到各种异常情况,其中频次较多的就是慢请求slow-request,慢请求会导致性能抖动,直接影响集群的稳定性,需要谨慎对待。而slow-request大部分都是由清理动作引起的,合理的配置以及规划清理计划,可以避免影响生产业务,同时也可以充分发挥存储的性能。