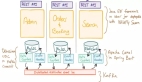
跨地域,即常说的“异地双活”、“异地多活”中的异地概念。在业务发展较快的情况下,我们的服务便需要跨地域部署,以满足各区域就近访问和跨地域容灾等需求,在此过程中,不可避免会涉及到跨地域下的分布式一致性问题。由跨地域所带来的网络延迟问题,以及由于网络延迟而衍生的一系列问题,对于设计和构建一个跨地域分布式一致性系统是极大的挑战,业界有很多针对此问题的解决方案,都希望能解决跨地域场景下的一致性问题。
本文分享阿里巴巴女娲团队在跨地域场景下对分布式一致性系统的探索,从"What How Future"三个方面,介绍跨地域场景下要承接的需求和挑战、业界常见系统和女娲团队对于跨地域场景权衡点的思考,以及对跨地域一致性系统未来发展的设计与思考,以发现和解决跨地域场景下更多的需求和挑战。
一 跨地域需求和挑战
1 需求
跨地域问题是在集团全球化战略下,业务快速发展带来的挑战。像是淘宝单元化业务,或是AliExpress区域化业务,都有一个无法回避的问题——数据跨区域读写一致性。
其核心需求可以总结为以下几点:
跨地域业务场景
跨地域配置同步与服务发现是两个常见的跨地域一致性协调服务的业务需求,跨地域部署可以提供就近访问能力以减小服务延迟,根据具体业务场景可分为多地域写或简化的单地域写、强一致性读或最终一致性读等场景。跨地域的会话管理及基于此的跨地域分布式锁也亟待提供成熟的解决方案。
服务、资源的拓展问题
当一个地域内某个机房的服务能力达到上限而又无法扩容,需要一致性系统在一个地域多个机房水平拓展和能够跨地域拓展。
跨地域容灾能力
当遭遇机房或者一个地域的灾难性故障时,需要一致性系统通过跨地域服务部署,将一个地域的业务迅速迁移到另一个地域完成灾备逃逸,实现高可用。
2 挑战
综合网络延迟和业务需求,可以归纳出跨地域一致性系统所需要化解的挑战:
延迟:网络延迟达几十毫秒
多地域部署带来的核心问题便是网络延迟高,以我们线上跨地域部署的跨地域集群为例,集群中机器分属于杭州、深圳、上海、北京四个地域的机房,实际测试杭州机房到上海延迟大约6ms,到深圳和北京的延迟可以达到接近30ms。同机房或同地域机房间的网络延迟一般在毫秒内,相比之下跨地域访问延迟上升了一个量级。
水平拓展:Quorum Servers规模受限
基于Paxos理论及其变种的分布式一致性系统,在拓展节点时不可避免会遇到Replication Overhead问题,一般一个Quorum的节点数目不大于9个,故无法简单地将一致性系统节点直接部署在多个地域,系统需要能持续地水平拓展,来满足服务、资源的拓展需求。
存储上限:单个节点存储数据受限且failover恢复慢
无论是MySQL还是基于Paxos的一致性系统,其单个节点都会维护和加载全量的镜像数据,会受到单台集群容量的限制。同时在failover恢复时,若数据版本落后较多,通过拉取其他地域镜像恢复会有较长的不可用时间。
二 我们的探索
1 业界解决方案
业界有针对跨地域的一致性系统有很多的设计,主要参考了论文[1]和一些开源的实现,下面介绍常见的几种:
跨地域部署
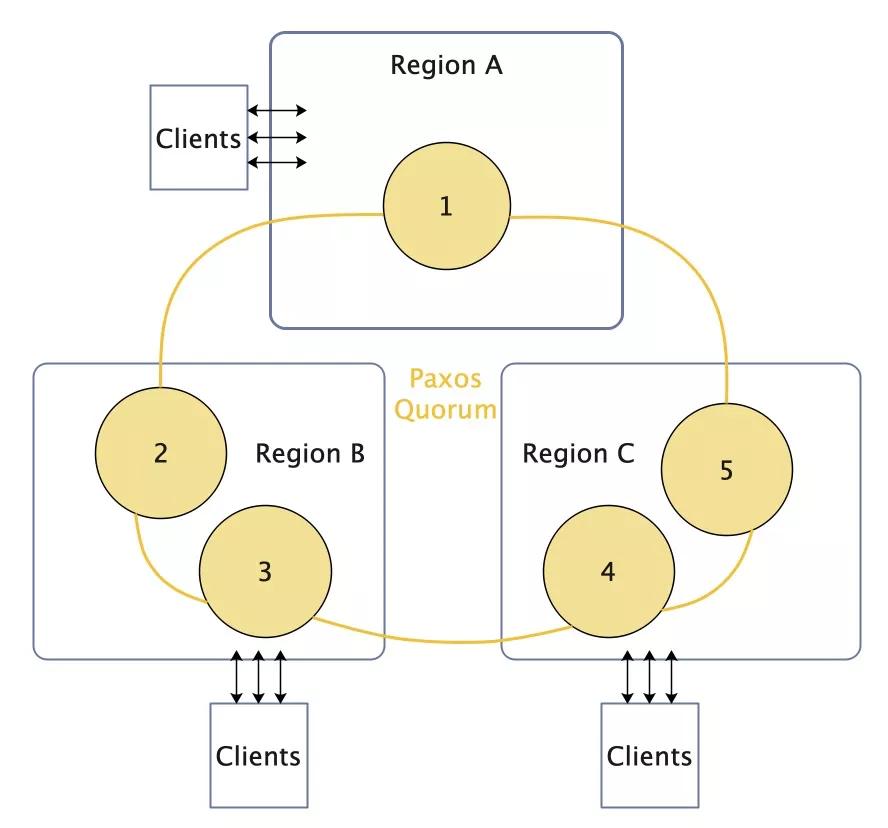
图1 直接跨地域部署
直接跨地域部署,读请求直接读本地域节点,速度较快,一致性、可用性由Paxos保证,没有单点问题。缺点也很明显,会遇到第一部分中讲到的水平拓展问题,即Quorum拓展时会遇到Replication Overhead问题。且随着Quorum节点数目变多,在跨地域极高的网络延迟下,每次多数派达成一致的时间会很长,写效率很低。
单地域部署+Learner角色
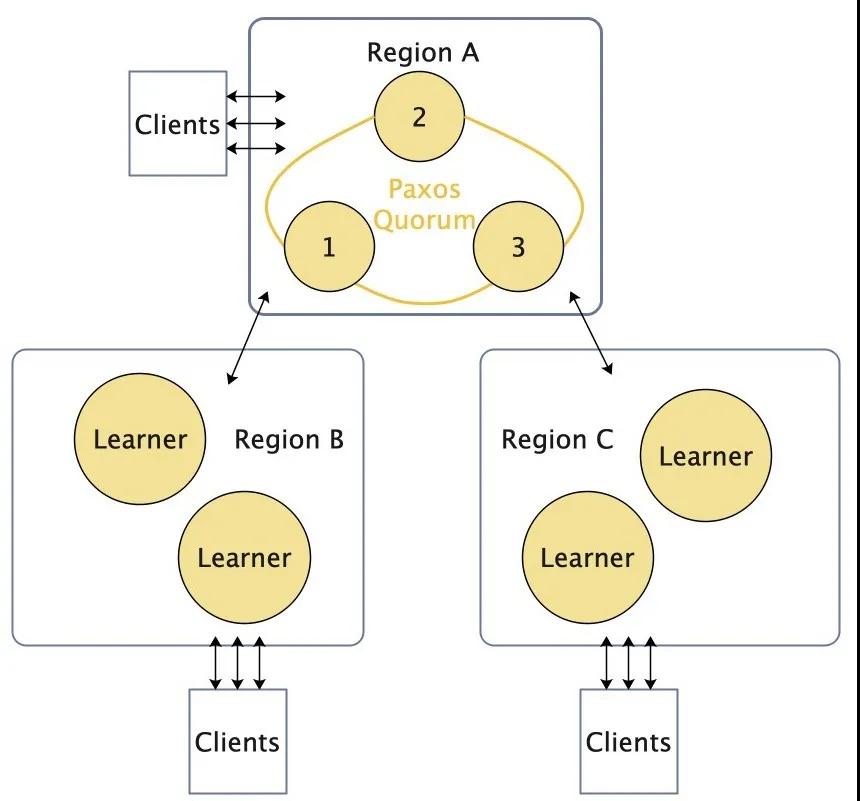
图2 引入Learner角色
通过引入Learner(例如zk中Observer、etcd的raft learner[2]) 角色,即只进行数据同步而不参与多数派投票的角色,将写请求转发到某一个区域(如图2中的Region A),来避免直接多节点部署的投票延时问题。此种方式可以解决水平拓展问题和延时问题,但由于参与投票的角色都部署在一个地域内,当此地域机房遇到灾难性时间时,写服务便不可用了。此种方式是Otter[3]所采用的部署方式。
多服务+Partition&单地域部署+Learner
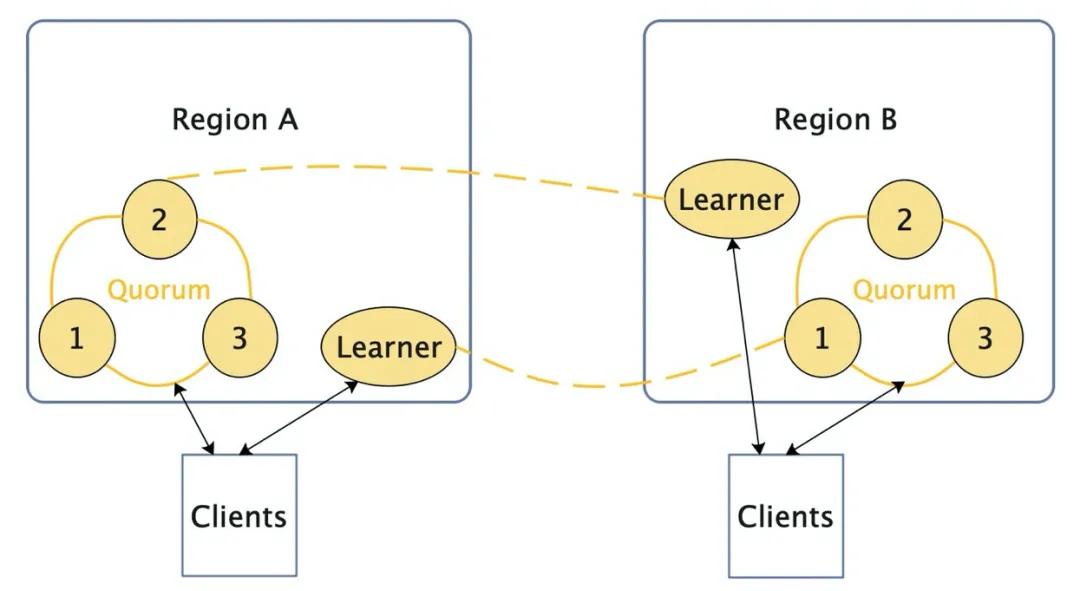
图3 多个服务处理分Partition
将数据按规则切分为不同Partition,每个地域一个Quorum提供服务,不同地域Quorum负责不同Partition,地域之间Quorum使用Learner进行不同Partition数据同步及写请求转发,保证某区域出现问题只影响该区域Partition可用性。同时此种方案下会有正确性问题,即操作不符合顺序一致性[4]的问题(见论文[1])。
实际实现时根据业务场景有各种解决方案,会针对性地进行优化和权衡,弥补缺陷。业界较常见方案的是单地域部署+Learner角色这种方案,通过同城多活和Learner做跨地域数据同步来保证较高的可用性和较高的效率。其他方案也各有优化方案,跨地域部署可以通过减少达成决议时地域间通信,来减小延时和带宽问题,如TiDB的Follower Replication[5];多服务+Partition&单地域部署+Learner这种方案的正确性也可以通过论文[1]中所述,在读之前添加sync操作,牺牲一部分读的可用性来保证一致性。
最后的结论如下表,后面会详细阐释其中的关键项:
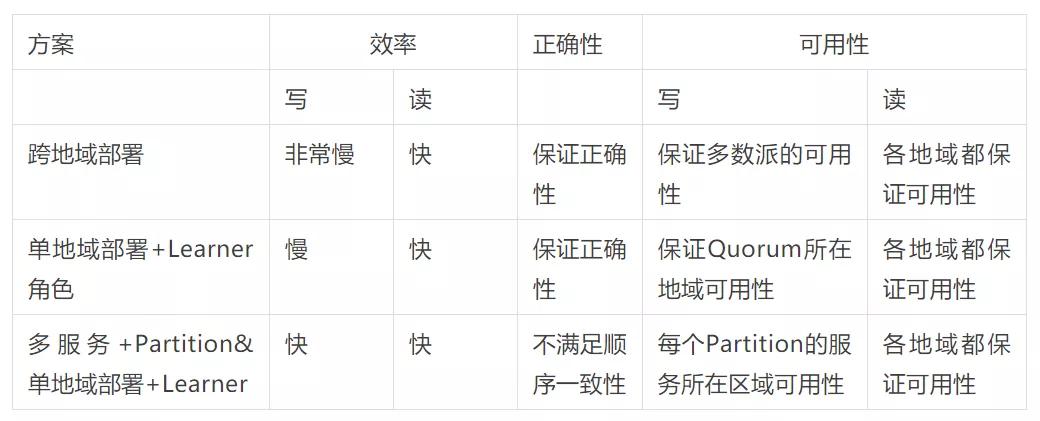
2 跨地域的权衡
通过第一部分总结的需求挑战和前面对业界跨地域一致性系统解决方案的调研,可以总结出基于Paxos的分布式一致性系统在跨地域场景下的核心权衡点:
- 写操作跨地域走一致性协议达成决议太慢
- 地域内多活无法提供极端情况下的可用性
- 需要具备分布式系统最核心的水平拓展能力
针对这三点问题,我们设计了一种日志镜像解耦的跨地域一致性系统。
3 跨地域日志镜像解耦
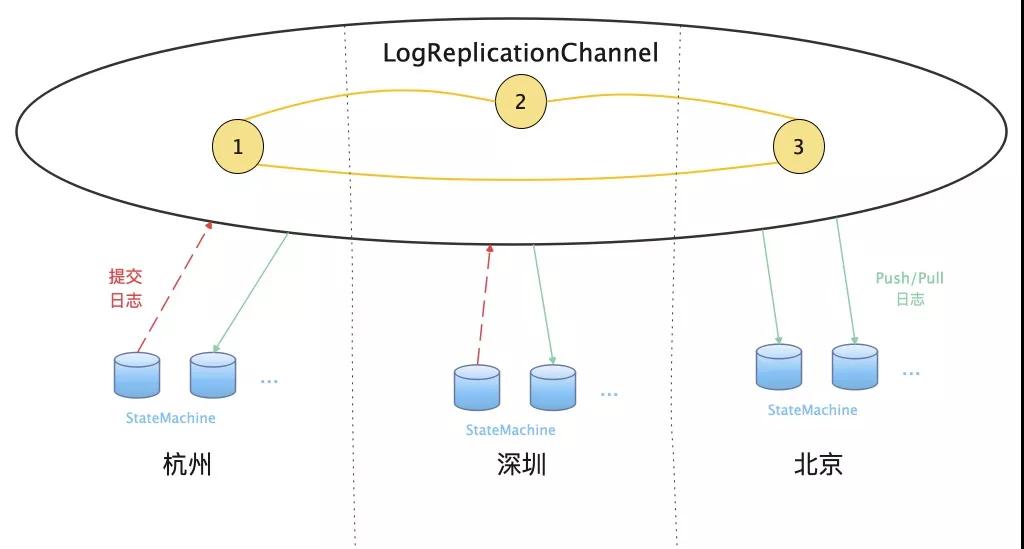
图4 日志镜像解耦示意图
如图3所示,我们的系统分为后端日志同步通道和前端全量状态机——日志与镜像解耦的架构。后端跨地域全局日志同步通道,负责保证请求日志在各个区域的强一致性;前端全量状态机部署在各地域内,处理客户端请求,也负责与后端日志服务交互,对外提供全局强一致性元数据访问服务,接口可以根据业务需求快速修改状态机来实现。
在全局日志与本地镜像分离的架构下,除了解耦本身带来的系统运维和可拓展性的提升,我们还可以解决很多未解耦架构下的问题,后面几条分析是在此种架构下如何对之前思考部分几大问题的一个解决:
写操作效率
单从部署的模式上看,看起来与直接多地域多节点部署,然后各地域添加Learner角色的做法类似,是直接多节点部署和引入Learner的一个结合,综合了两种方式的优缺点。最大区别在于,我们的日志和镜像解耦了,也就是说跨地域的部分是足够轻量高效的单纯日志同步,且由于每个地域只有一个节点,能够节省跨地域带宽(类似TiDB的Follower Replication)。同时后端日志同步通道,也可以实现多Group的功能,将数据分成Partition,每个一致性Group负责不同的Partiton。
由于大部分业务场景的读操作为读本地数据,各种方式相差不大,主要进行写操作的延迟分析,下面是对于写操作(或强一致性读)的延迟分析:
RTT(Round-Trip Time),可以简单理解为发送消息方从发送请求到得到响应所经过的时间。由于跨地域网络延迟较大,后面RTT主要指跨地域RTT。
(1)直接跨地域部署
对于一个常见的有主一致性协议,我们的请求分两种情况:
访问Leader所在地域 1个RTT(暂时忽略地域内较小的延迟)
- Client -> Leader ----> Follower ----> Leader -> Client
访问Follower所在地域 2个RTT
- Client -> Follower ----> Leader ----> Follower ----> Leader ----> Follower ->
(2)单地域部署+Learner同步
在地域内多活,地域间Learnner同步的方案中,我们的延时为:
本地域 0个RTT
- Client -> Quorum -> Client
地域间 1个RTT
- Client -> Learner ----> Quorum ----> Learner -> Client
(3)多服务Partition,单地域部署+Learner同步(与B结果类似)
写本地域Partition 0个RTT
跨Partition写 1个RTT
(4)日志镜像解耦的架构(与A结果类似)
写本地域Partiton 1个RTT
- Client ->Frontend -> LogChannel(local) ----> LogChannel (peer) ----> LogChannel (local) -> Frontend -> Client
跨Partition写 2个RTT (Paxos两阶段提交/转发leader)
- Client ->Frontend -> LogChannel (local) ----> LogChannel (peer) ----> LogChannel (local) ----> LogChannel (peer) ----> LogChannel (local) -> Frontend -> Client
经过以上的对比,可以看出只要跨地域走一致性协议进行写操作,最少也会有1个RTT的延迟,而如果将Paxos Quorum只部署在单地域,又不能保证任何极端情况下的可用性。所以我们根据业务需要,可以进行可用性和写效率的权衡,日志镜像解耦的架构可以在多地域部署场景下保证极端的可用性和正确性,当然效率上会比单地域部署+learner稍差一些,但如果采用多整体比直接多地域部署的方式要轻量高效,因为Quorum规模不会因水平拓展增加,不会影响投票效率。与多服务分Partition部署的方案则没有效率优势,但在可运维护性、正确性、可用性这些方面都有优势。
一致性
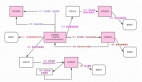
跨地域部署和单地域部署+Learner的强一致性是满足的,zookeeper和etcd都有对应的介绍,在此不做赘述。多服务Partition分Partion这种方案不满足顺序一致性,主要是因为多服务不能保证每条写操作commit的顺序性,见下图:

图5 顺序一致性
可以看到,当两个Client同时对x,y进行修改时,在写操作并发程度较高的情况下,不能保证顺序一致性。
顺序一致性即可以将各个Client的操作排列出一个正确顺序,在图4的例子中:
- set1(x,5) => get1(y)->0 => set2(y,3) => get2(x)->5
或者
- set2(y,3) => get2(x)->0 => set2(y,3) => get1(y)->3
都是符合顺序一致性的。
日志镜像解耦的架构的一致性可以简单理解为跨地域部署+Learner,写操作有sync选项,会在后端log提交成功并拉取到对应log时才会返回成功,因此一定是可以拉取到其他Client在此操作之前的写操作对应的log,故符合顺序一致性。
可用性
可用性这点与直接跨地域多节点部署的可用性类似,前端状态机可以在某个地域后端节点挂掉情况下进行请求转发,在后端全局日志服务不可用时也可以提供读的可用性,可以提供极端情况下的读写高可用保证。
同时由于镜像存储在各个地域的状态机中,当某个前端状态机挂掉时可以把客户端切换到其他前端,failover恢复时也可以直接从后端拉取数据恢复,在落后太多情况下才需要从本地域其他前端拉取镜像,不用跨地域同步镜像,由此可以使得前端的不可用时间极短。
水平拓展能力
水平拓展能力是分布式服务的核心能力,在前述的多种方案中,直接跨地域部署水平拓展能力极差,其他依赖Learner的方式,也解决了水平拓展的问题,只是解耦没有日志镜像解耦的设计干净。
将以上几个关键问题总结对比:

三 跨地域更多可能性
后端日志和前端镜像解耦的状态下,我们对跨地域场景的探索分为两部分——后端日志同步轻量高效和前端状态机灵活丰富。
- 轻量,体现在架构,后端只同步日志带来的后端存储压力极小,只用同步轻量的增量日志。
- 高效,体现在后端的一致性协议,由于轻量,所以只需要考虑投票和选举的逻辑,只用注重日志同步效率的提升,后端资源不用消耗在其他业务逻辑上。
- 灵活,体现在架构,前端可以自定义上传日志,CAS、事务等都可以包装成日志由前端解析和处理。
- 丰富,主要是体现在前端的状态机,由于日志的灵活留给我们探索和构建的空间极大,可以根据需求包装出处理各种复杂事务的状态机。
新的架构下有新的问题,这一部分主要探究如何吸取已有系统的优点,利用日志镜像解耦下的轻量、灵活,来实现跨地域场景下一致性协议和状态机的高效、丰富,也会对跨地域一致性系统后继如何发展有一个思考和规划。总体目标是后端一致性协议做精做深,前端状态机做大做强。
1 高效的后端一致性协议
基于我们前面对写操作效率的讨论,在多地域写同一数据场景下,延迟只能控制在2RTT。因为跨地域场景下,延迟占比主要在跨地域网络通信,无论是有主的转发还是无主的Paxos两阶段提交,延迟都有2RTT。但如果使用无主的协议,如Paxos的变种EPaxos[6],则可以尽可能提高跨地域场景下写的效率,其延迟分Fast Path和Slow Path两种情况,在Fast Path下延迟为1RTT, Slow Path下延迟为2RTT。
引用介绍EPaxos文章中的一句话:
若并发提议的日志之间没有冲突,EPaxos只需要运行PreAccept阶段即可提交(Fast Path),否则需要运行Accept阶段才能提交(Slow Path)。
相比于分Partition操作,如果将后端一致性协议选为EPaxos,则可以保证极端情况下的可用性和大多数情况下延迟为1RTT,这是无主一致性协议在跨地域场景下的优势,主要是因为省去了一次转发Leader操作的RTT。目前我们系统中使用的是最基础的Paxos的实现,在多地写场景下延迟理论上与有主的协议相差不大,后继发展期望利用EPaxos来加快跨地域场景下写操作的效率。
由于不需要实现各种业务逻辑,高效便是后端一致性协议的最大诉求,当然其正确性、稳定性也是必不可少的,而对于前端的状态机,则有着丰富的场景来设计和发挥。
CAS操作
CAS操作在此种架构下的实现是很自然的,由于后端只有一致性log,所以我们每一次CAS请求,自然而然会有Commit的先后顺序,举一个例子。
两个客户端同时写同一个Key的值:
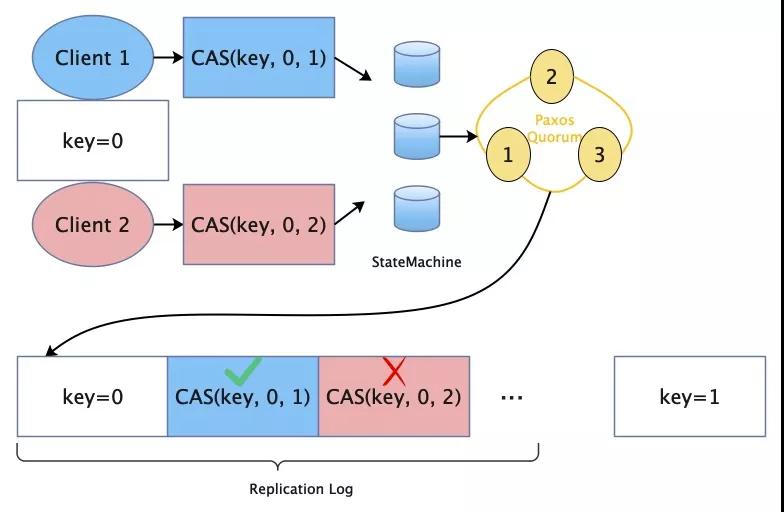
图 6 CAS操作示意图
开始时key的值为0,此时Client 1和Client 2并发对key进行CAS操作,分别为CAS(key, 0, 1)和CAS(key, 0, 2),当这两个操作同时提交并Commit后,由于后端Quorum达成决议的先后,Replication Log一定会有先后顺序,因此自然而然这两个并发的CAS操作转换为顺序执行。当Frontend同步到这两个操作的log时,会依次apply这两个操作到本地状态机,自然CAS(key, 0, 1)成功,更新key值为1,而CAS(key, 0, 2)更新失败,这时前端会返回给对应请求的Client其CAS请求是否成功或失败的结果。
其原理是将一个并发操作变成了一个顺序执行的串行过程,由此避免了在跨地域场景下对加锁的操作,可以想象如果是后端维护了一个kv结构数据,则还需要增加一个跨地域分布式锁来完成此操作,相对更加繁琐,效率也没有保证。通过只同步日志把复杂计算转移到Frontend,可以灵活地构建前端状态机,更好地实现CAS或更复杂的事务功能(此种架构可参考pravega的StateSynchronizer[7])。
Global ID
Global ID是一个常见的需求,分布式系统生成一个唯一ID,常见的有使用UUID、snow flake算法,或者基于数据库、redis、zookeeper的方案。
类似使用zookeeper的znode数据版本进行Global ID的生成,在此种日志镜像分离架构中,可以使用CAS接口调用,生成一个key作为Global ID,每次对Global ID进行原子操作。基于上述的CAS设计,跨地域并发场景下不需要加锁,在使用方式上类似redis对key进行原子操作。
2 Watch操作
订阅功能是分布式协调服务的不可或缺的,是业务最常见的一种需求,下面是对zk和etcd的调研结果:
目前业界比较成熟的实现了订阅通知的分布式协调系统包括ETCD和ZooKeeper,我们分别以这两个系统为例讲解各自的解决方案。
ETCD会保存数据的多个历史版本(MVCC),通过单调递增的版本号来表明版本的新旧,客户端只要传入自己关心的历史版本,服务端就可以将后续的所有事件推送给客户端。
Zookeeper并不会保存数据的多个历史版本,只有当前的数据状态,客户端并不能订阅数据的历史版本,客户端只能订阅当前状态之后的改变事件,所以订阅伴随着读,服务端把当前的数据发送给客户端,然后推送后续的事件,同时为了防止在failover等异常场景订阅到老的数据和事件,客户端会拒绝连接数据比较老的服务端(这依赖于服务端会在每个请求会返回当前的服务端全局的XID)。
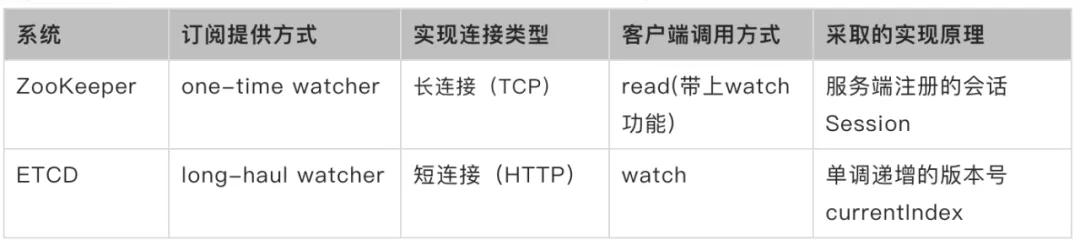
上述的调研结果中ETCD较为符合我们的接口设计,目前ETCDv3 使用了HTTP/2的TCP链接多路复用,watch性能有提升。由于同为日志加状态机结构,设计功能时主要参考了ETCD v3,借鉴其如何订阅多个key以及返回全部历史事件这两个特性。若要达到etcd订阅的功能,我们在前端状态机同步并解析日志时,如果出现写日志,则将kv结构的状态机Store和 专门提供给watch接口的状态机watchableStore同时更新,具体实现可以完全参考etcd,然后按日志版本号将订阅时版本后的历史事件全部返回给客户端。而订阅多个key则同样使用线段树作为watcher的range keys存储结构,可以实现watch范围keys的watcher通知。
3 Lease机制
在无主的系统中实现高效的Lease机制是一大挑战,无主的系统中没有Leader,任意节点均可维护Lease,Lease分布在各个节点上,当有节点不可用时,需要平滑切换到其它节点。无主的系统中实现高效的Lease机制的难点在于随着Lease数量的增加,如何避免后端的一致性协议中出现大量的Lease维持消息,影响系统性能,最好让Lease维持消息能够直接在前端本地处理,而不经过后端。所以我们的思路是将客户端与前端的Lease聚合到前端与后端的Lease,使得Lease维持消息能够直接在前端本地处理。
四 结语
随着全球化战略的推进,跨地域方面的需求一定会越来越迫切,跨地域场景的真正痛点也会越来越清晰,希望我们在跨地域方面的调研和探索可以给大家一个思路和参考,我们也会继续探索跨地域日志镜像分离的架构下更多的可能性。
相关链接
[1]https://www.usenix.org/conference/atc16/technical-sessions/presentation/lev-ari
[2]https://github.com/etcd-io/etcd/blob/master/Documentation/learning/design-learner.md
[3]https://github.com/alibaba/otter
[4]https://zhuanlan.zhihu.com/p/43949695
[5]https://zhuanlan.zhihu.com/p/94663335
[6]https://zhuanlan.zhihu.com/p/163271175
[7]https://github.com/pravega/pravega/blob/master/documentation/src/docs/state-synchronizer-design.md