Pulsar 是一个由 Yahoo 公司于 2016 年开源的消息中间件,2018 年成为 Apache 的顶级项目。
图片来自 Pexels
在开源的业界已经有这么多消息队列中间件了,Pulsar 作为一个新势力到底有什么优点呢?
Pulsar 自从出身就不断的再和其他的消息队列(Kafka,RocketMQ 等等)做比较。
但是 Pulsar 的设计思想和大多数的消息队列中间件都不同,具备了高吞吐,低延迟,计算存储分离,多租户,异地复制等功能。
所以 Pulsar 也被誉为下一代消息队列中间件,接下来我会一一对其进行详细的解析。
Pulsar 架构原理
Pulsar 架构原理如下图:
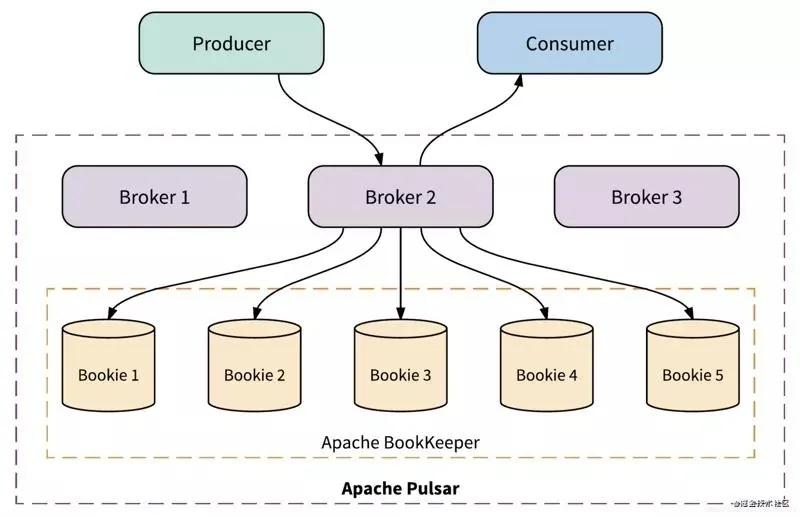
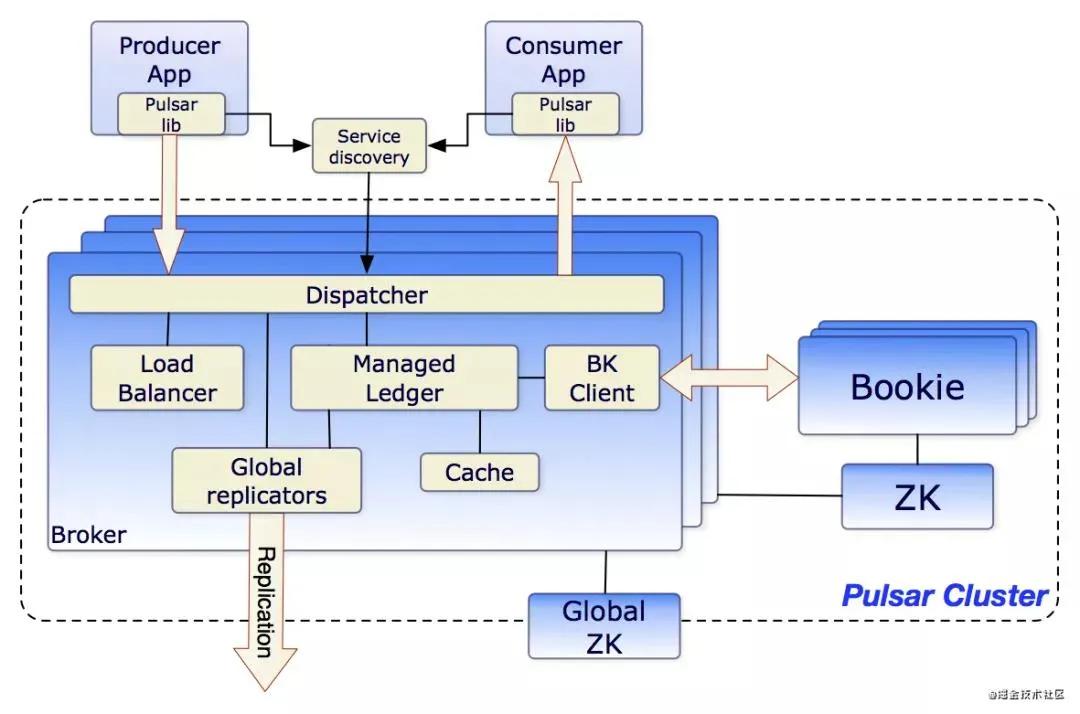
整体的架构和其他的消息队列中间件差别不是太大,相信大家也看到了很多熟悉的名词,接下来会给大家一一解释这些名词的含义。
名词解释:
- Producer:消息生产者,将消息发送到 Broker。
- Consumer:消息消费者,从 Broker 读取消息到客户端,进行消费处理。
- Broker:可以看作是 Pulsar 的 Server,Producer 和 Consumer 都看作是 Client 消息处理的节点。
Pulsar 的 Broker 和其他消息中间件的都不一样,他是无状态的没有存储,所以可以无限制的扩展,这个后面也会详解讲到。
- Bookie:负责所有消息的持久化,这里采用的是 Apache Bookeeper。
- ZK:和 Kafka 一样 Pulsar 也是使用 ZK 保存一些元数据,比如配置管理,Topic 分配,租户等等。
- Service Discovery:可以理解为 Pulsar 中的 Nginx,只用一个 URL 就可以和整个 Broker 进行打交道,当然也可以使用自己的服务发现。
客户端发出的读取,更新或删除主题的初始请求将发送给可能不是处理该主题的 Broker 。
如果这个 Broker 不能处理该主题的请求,Broker 将会把该请求重定向到可以处理主题请求的 Broker。
不论是 Kafka,RocketMQ 还是我们的 Pulsar 其实作为消息队列中间件最为重要的大概就是分为三个部分:
- Producer 是如何生产消息,发送到对应的 Broker。
- Broker 是如何处理消息,将高效的持久化以及查询。
- Consumer 是如何进行消费消息。
而我们后面也会围绕着这三个部分进行展开讲解。
Producer 生产消息
先简单看一下如何用代码进行消息发送:
- PulsarClient client = PulsarClient.create("pulsar://pulsar.us-west.example.com:6650");
- Producer producer = client.createProducer(
- "persistent://sample/standalone/ns1/my-topic");
- // Publish 10 messages to the topic
- for (int i = 0; i < 10; i++) {
- producer.send("my-message".getBytes());
- }
Step1:首先使用我们的 URL 创建一个 Client 这个 URL 是我们 Service Discovery 的地址,如果我们使用单机模式可以进行直连。
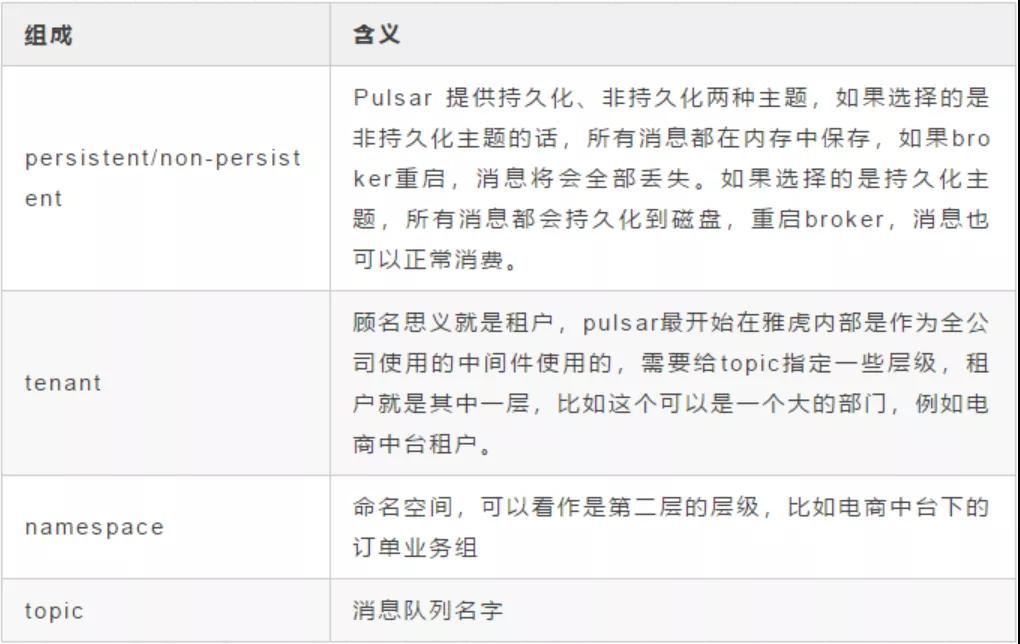
Step2:我们传入了一个类似 URL 的参数,我们只需要传递这个就能指定我们到底在哪个 Topic 或者 Namespace 下面创建的,URL 的格式为:
- {persistent|non-persistent}://tenant/namespace/topic
Step3:调用 Send 方法发送消息,这里也提供了 sendAsync 方法支持异步发送。
上面三个步骤中,步骤 1,2 属于我们准备阶段,用于构建客户端,构建 Producer,我们真的核心逻辑在 Send 中。
那这里我先提几个小问题,大家可以先想想在其他消息队列中是怎么做的,然后再对比 Pulsar 的看一下:
- 我们调用了 Send 之后是会立即发送吗?
- 如果是多 Partition,怎么找到我应该发送到哪个 Broker 呢?
发送模式
我们上面说了 Send 分为 Async 和 Sync 两种模式,但实际上在 Pulsar 内部 Sync 模式也是采用的 Async 模式,在 Sync 模式下模拟回调阻塞,达到同步的效果。
这个在 Kafka 中也是采用的这个模式,但是在 RocketMQ 中,所有的 Send 都是真正的同步,都会直接请求到 Broker。
基于这个模式,在 Pulsar 和 Kafka 中都支持批量发送,在 RocketMQ 中是直接发送,批量发送有什么好处呢?
当我们发送的 TPS 特别高的时候,如果每次发送都直接和 Broker 直连,可能会做很多的重复工作,比如压缩,鉴权,创建链接等等。
比如我们发送 1000 条消息,那么可能会做 1000 次这个重复的工作,如果是批量发送的话这 1000 条消息合并成一次请求,相对来说压缩,鉴权这些工作就只需要做一次。
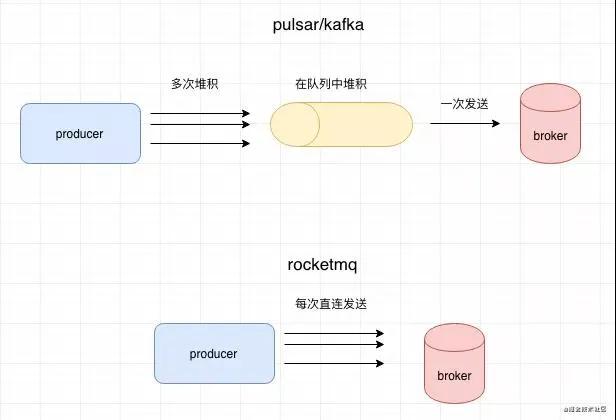
有同学可能会问,批量发送会不会导致发送的时间会有一定的延误?这个其实不需要担心,在 Pulsar 中默认定时每隔 1ms 发送一次 Batch,或者当 batchsize 默认到了 1000 都会进行发送,这个发送的频率都还是很快的。
发送负载均衡
在消息队列中通常会将 Topic 进行水平扩展,在 Pulsar 和 Kafka 中叫做 Partition,在 RocketMQ 中叫做 Queue,本质上都是分区,我们可以将不同分区落在不同的 Broker 上,达到我们水平扩展的效果。
在我们发送的时候可以自己制定选择 Partition 的策略,也可以使用它默认轮训 Partition 策略。
当我们选择了 Partition 之后,我们怎么确定哪一个 Partition 对应哪一个 Broker 呢?
可以先看看下面这个图:
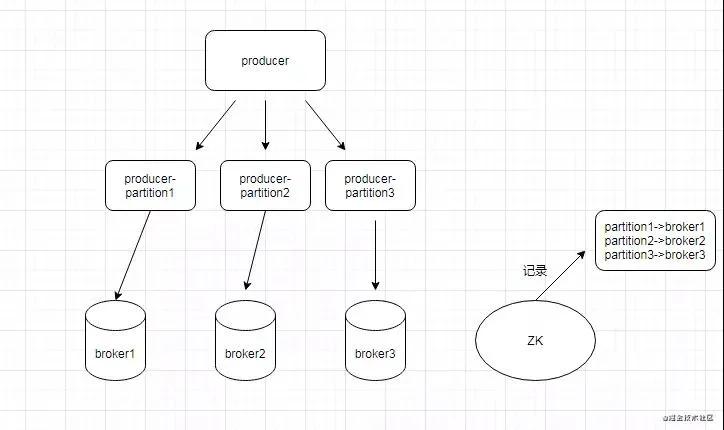
Step1:我们所有的信息分区映射信息在 ZK 和 Broker 的缓存中都有进行存储。
Step2:我们通过查询 Broker,可以获取到分区和 Broker 的关系,并且定时更新。
Step3:在 Pulsar 中每个分区在发送端的时候都被抽象成为一个单独的 Producer,这个和 Kafka,RocketMQ 都不一样。
在 Kafka 里面大概就是选择了 Partition 之后然后再去找 Partition 对应的 Broker 地址,然后进行发送。
Pulsar 将每一个 Partition 都封装成 Producer,在代码实现上就不需要去关注他具体对应的是哪个 Broker,所有的逻辑都在 Producer 这个代码里面,整体来说比较干净。

压缩消息
消息压缩是优化信息传输的手段之一,我们通常看见一些大型文件都会是以一个压缩包的形式提供下载。
在我们消息队列中我们也可以用这种思想,我们将一个 Batch 的消息,比如有 1000 条可能有 1M 的传输大小,但是经过压缩之后可能就只会有几十 KB,增加了我们和 Broker 的传输效率,但是与之同时我们的 CPU 也带来了损耗。
Pulsar 客户端支持多种压缩类型,如 lz4、zlib、zstd、snappy 等。
- client.newProducer()
- .topic(“test-topic”)
- .compressionType(CompressionType.LZ4)
- .create();
Broker
接下来我们来说说第二个比较重要的部分 Broker,在 Broker 的设计中 Pulsar 和其他所有的消息队列差别比较大,而正是因为这个差别也成为了他的特点。
计算和存储分离
首先我们来说说他最大的特点:计算和存储分离。
我们在开始的说过 Pulsar 是下一代消息队列,就非常得益于他这个架构设计,无论是 Kafka 还是 RocketMQ,所有的计算和存储都放在同一个机器上。
这个模式有几个弊端:
- 扩展困难:当我们需要扩展的集群的时候,我们通常是因为 CPU 或者磁盘其中一个原因影响,但是我们却要申请一个可能 CPU 和磁盘配置都很好的机器,造成了资源浪费。并且 Kafka 这种进行扩展,还需要进行迁移数据,过程十分繁杂。
- 负载不均衡:当某些 Partion 数据特别多的时候,会导致 Broker 负载不均衡,如下面图,如果某个 Partition 数据特别多,那么就会导致某个 Broker(轮船)承载过多的数据,但是另外的 Broker 可能又比较空闲。

Pulsar 计算分离架构能够非常好的解决这个问题:
- 对于计算:也就是我们的 Broker,提供消息队列的读写,不存储任何数据,无状态对于我们扩展非常友好,只要你机器足够,就能随便上。
扩容 Broker 往往适用于增加 Consumer 的吞吐,当我们有一些大流量的业务或者活动,比如电商大促,可以提前进行 Broker 的扩容。
- 对于存储:也就是我们的 Bookie,只提供消息队列的存储,如果对消息量有要求的,我们可以扩容 Bookie,并且我们不需要迁移数据,扩容十分方便。
消息存储
名词解析:
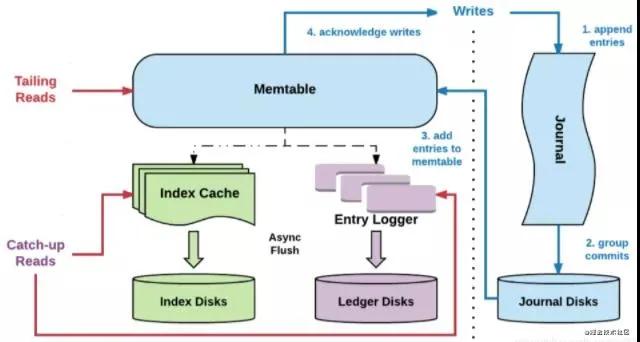
上图是 Bookie 的读写架构图,里面有一些名词需要先介绍一下:
- Entry:是存储到 bookkeeper 中的一条记录,其中包含 Entry ID,记录实体等。
- Ledger:可以认为 ledger 是用来存储 Entry 的,多个 Entry 序列组成一个 ledger。
- Journal:其实就是 bookkeeper 的 WAL(write ahead log),用于存 bookkeeper 的事务日志,journal 文件有一个最大大小,达到这个大小后会新起一个 journal 文件。
- Entry log:存储 Entry 的文件,ledger 是一个逻辑上的概念,entry 会先按 ledger 聚合,然后写入 entry log 文件中。同样,entry log 会有一个最大值,达到最大值后会新起一个新的 entry log 文件。
- Index file:ledger 的索引文件,ledger 中的 entry 被写入到了 entry log 文件中,索引文件用于 entry log 文件中每一个 ledger 做索引,记录每个 ledger 在 entry log 中的存储位置以及数据在 entry log 文件中的长度。
- MetaData Storage:元数据存储,是用于存储 bookie 相关的元数据,比如 bookie 上有哪些 ledger,bookkeeper 目前使用的是 zk 存储,所以在部署 bookkeeper 前,要先有 zk 集群。
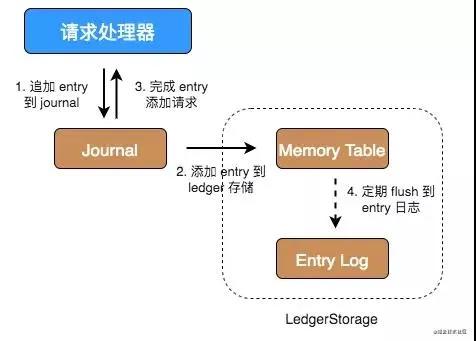
整体架构上的写流程:
- Step1:Broker 发起写请求,首先对 Journal 磁盘写入 WAL,熟悉 MySQL 的朋友知道 redolog,journal 和 redolog 作用一样都是用于恢复没有持久化的数据。
- Step2:然后再将数据写入 index 和 ledger,这里为了保持性能不会直接写盘,而是写 pagecache,然后异步刷盘。
- Step3:对写入进行 ack。
读流程为:
- Step1:先读取 index,当然也是先读取 cache,再走 disk。
- Step2:获取到 index 之后,根据 index 去 entry logger 中去对应的数据。
如何高效读写?在 Kafka 中当我们的 Topic 变多了之后,由于 Kafka 一个 Topic 一个文件,就会导致我们的磁盘 IO 从顺序写变成随机写。
在 RocketMQ 中虽然将多个 Topic 对应一个写入文件,让写入变成了顺序写,但是我们的读取很容易导致我们的 Pagecache 被各种覆盖刷新,这对于我们的 IO 的影响是非常大的。
所以 Pulsar 在读写两个方面针对这些问题都做了很多优化:
写流程:顺序写+Pagecache。在写流程中我们的所有的文件都是独立磁盘,并且同步刷盘的只有 Journal。
Journal 是顺序写一个 journal-wal 文件,顺序写效率非常高。ledger 和 index 虽然都会存在多个文件,但是我们只会写入 Pagecache,异步刷盘,所以随机写不会影响我们的性能。
读流程:broker cache+bookie cache,在 Pulsar 中对于追尾读(tailing read)非常友好基本不会走 IO。
一般情况下我们的 Consumer 是会立即去拿 Producer 发送的消息的,所以这部分在持久化之后依然在 Broker 中作为 Cache 存在。
当然就算 Broker 没有 Cache(比如 Broker 是新建的),我们的 Bookie 也会在 Memtable 中有自己的 Cache,通过多重 Cache 减少读流程走 IO。
我们可以发现在最理想的情况下读写的 IO 是完全隔离开来的,所以在 Pulsar 中能很容易就支持百万级 Topic,而在我们的 Kafka 和 RocketMQ 中这个是非常困难的。
无限流式存储
一个 Topic 实际上是一个 ledgers流(Segment),通过这个设计所以 Pulsar 他并不是一个单纯的消息队列系统,他也可以代替流式系统,所以他也叫流原生平台,可以替代 Flink 等系统。
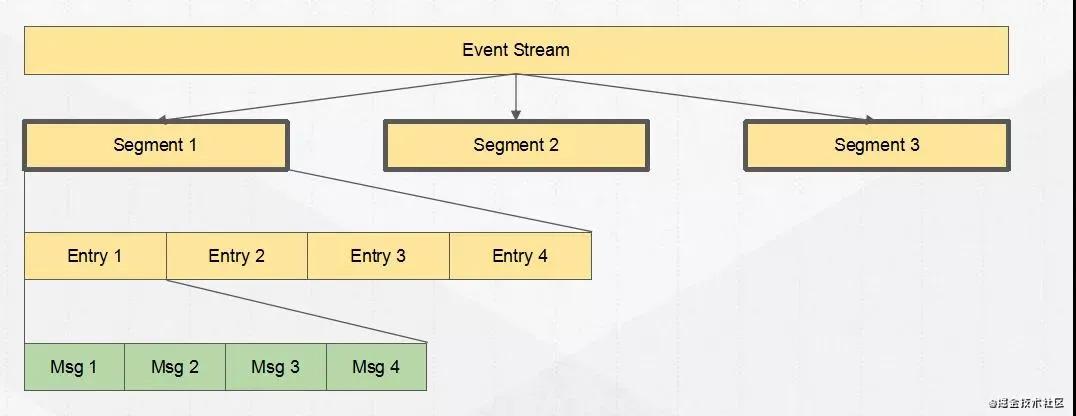
可以看见我们的 Event Stream(topic/partition),由多个 Segment 存储组成,而每个 Segment 由 Entry 组成,这个可以看作是我们每批发送的消息通常会看作是一个 Entry。
Segment 可以看作是我们写入文件的一个基本维度,同一个 Segment 的数据会写在同一个文件上面,不同 Segment 将会是不同文件,而 Segment 之间的在 Metadata 中进行保存。
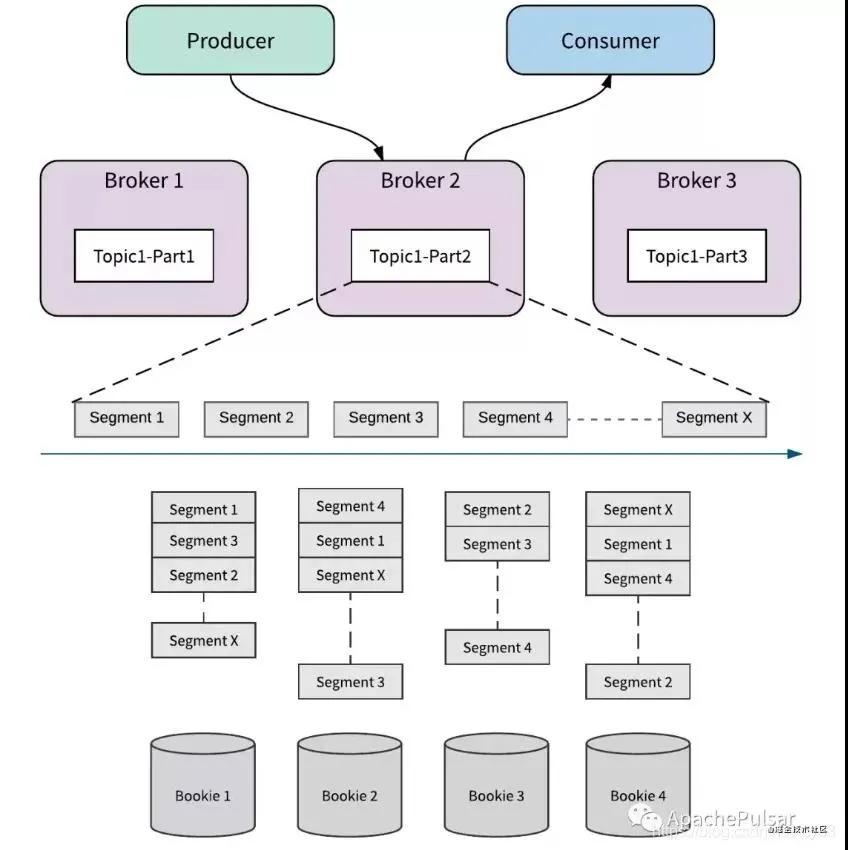
分层存储
在 Kafka 和 RocketMQ 中消息是会有一定的保存时间的,因为磁盘会有空间限制。
在 Pulsar 中也提供这个功能,但是如果你想让自己的消息永久存储,那么可以使用分级存储,我们可以将一些比较老的数据,定时的刷新到廉价的存储中,比如 s3,那么我们就可以无限存储我们的消息队列了。
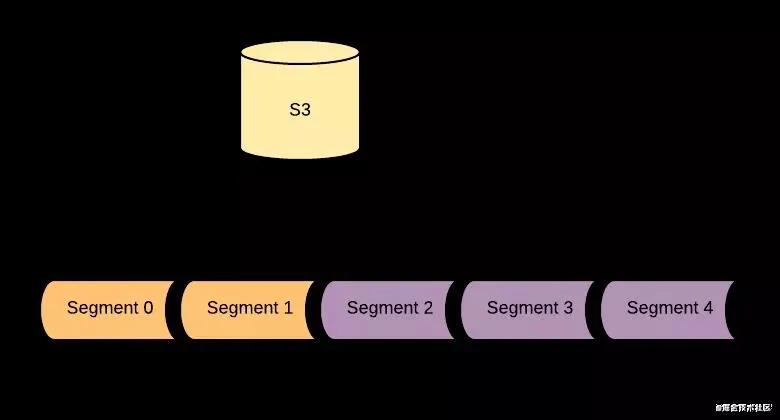
数据复制
在 Pulsar 中的数据复制和 Kafka,RocketMQ 都有很大的不同,在其他消息队列中通常是其他副本主动同步,通常这个时间就会变得不可预测。
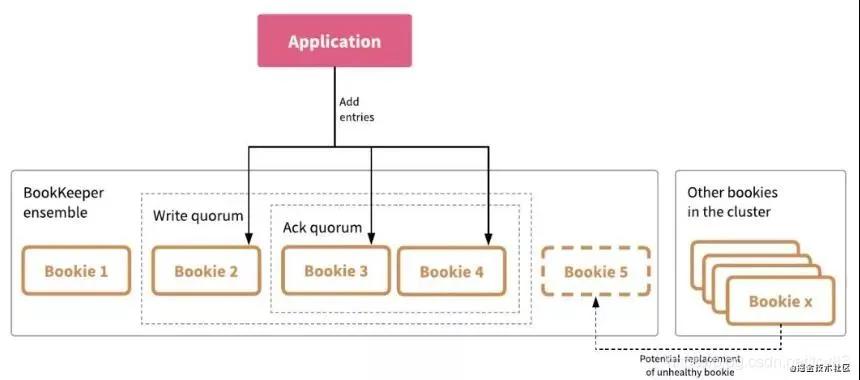
而在 Pulsar 采用了类似 Qurom 协议,给一组可用的 Bookie 池,然后并发的写入其中的一部分 Bookie,只要返回部分成功(通常大于 1/2)就好。
- Ensemble Size(E):决定给定 Ledger 可用的 Bookie 池大小。
- Write Quorum Size(Qw):指定 Pulsar 向其中写入 Entry 的 Bookie 数量。
- Ack Quorum Size(Qa):指定必须 Ack 写入的 Bookie 数量。
采用这种并发写的方式,会更加高效的进行数据复制,尤其是当数据副本比较多的时候。
Consumer
接下来我们来聊聊 Pulsar 中最后一个比较重要的组成 Consumer。
订阅模式
订阅模式是用来定义我们的消息如何分配给不同的消费者,不同消息队列中间件都有自己的订阅模式。
一般我们常见的订阅模式有:
- 集群模式:一条消息只能被一个集群内的消费者所消费。
- 广播模式:一条消息能被集群内所有的消费者消费。
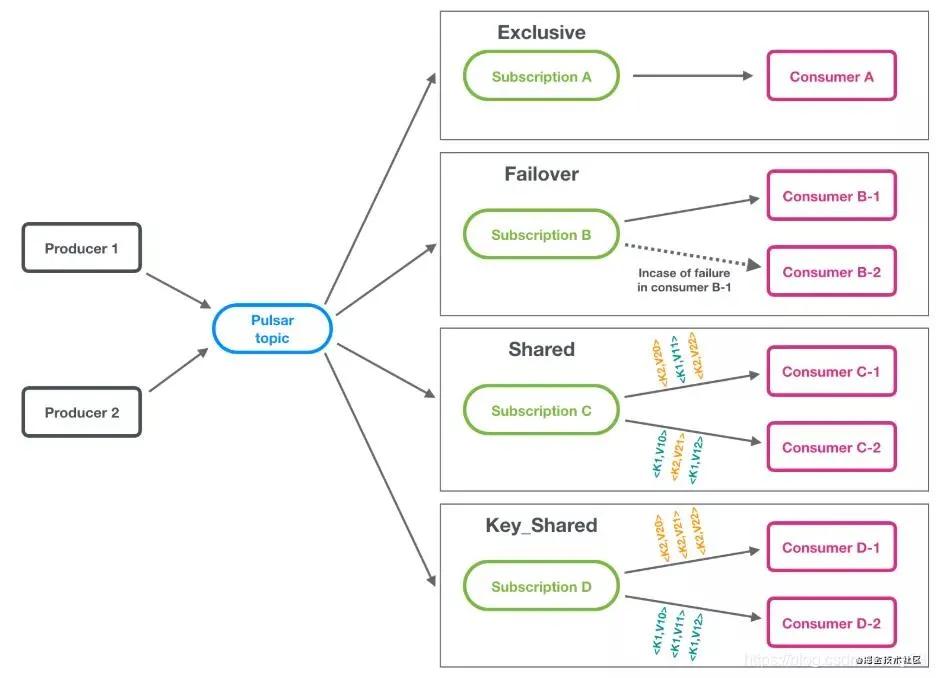
在 Pulsar 中提供了 4 种订阅模式,分别是:
独占:顾名思义只能由一个消费者独占,如果同一个集群内有第二个消费者去注册,第二个就会失败,这个适用于全局有序的消息。
灾备:加强版独占,如果独占的那个挂了,会自动的切换到另外一个好的消费者,但是还是只能由一个独占。
共享模式:这个模式看起来有点像集群模式,一条消息也是只能被一个集群内消费者消费,但是和 RocketMQ 不同的是,RocketMQ 是以 Partition 维度,同一个 Partition 的数据都会被发到一个机器上。
在 Pulsar 中消费不会以 Partition 维度,而是轮训所有消费者进行消息发送。这有个什么好处呢?
如果你有 100 台机器,但是你只有 10 个 Partition 其实你只有 10 台消费者能运转,但是在 Pulsar 中 100 台机器都可以进行消费处理。
键共享:类似上面说的 Partition 维度去发送,在 RocketMQ 中同一个 Key 的顺序消息都会被发送到一个 Partition。
但是这里不会有 Partition 维度,而只是按照 Key 的 Hash 去分配到固定的 Consumer,也解决了消费者能力限制于 Partition 个数问题。
消息获取模式
不论是在 Kafka 还是在 RocketMQ 中我们都是 Client 定时轮训我们的 Broker 获取消息,这种模式叫做长轮训(Long-Polling)模式。
这种模式有一个缺点网络开销比较大,我们来计算一下 Consumer 被消费的时延,我们假设 Broker 和 Consumer 之间的一次网络延时为 R。
那么我们总共的时间为:
- 当某一条消息 A 刚到 Broker 的,这个时候 long-polling 刚好打包完数据返回,Broker 返回到 Consumer 这个时间为 R。
- Consumer 又再次发送 Request 请求,这个又为 R。
- 将我们的消息 A 返回给 Consumer 这里又为 R。
如果只考虑网络时延,我们可以看见我们这条消息的消费时延大概是 3R,所以我们必须想点什么对其进行一些优化。
有同学可能马上就能想到,我们消息来了直接推送给我们的 Consumer 不就对了,这下我们的时延只会有一次 R,这个就是我们常见的推模式。
但是简单的推模式是有问题的,如果我们有生产速度远远大于消费速度,那么推送的消息肯定会干爆我们的内存,这个就是背压。
那么我们怎么解决背压呢?我们就可以优化推送方式,将其变为动态推送,我们结合 Long-polling,在 long-polling 请求时将 Buffer 剩余空间告知给 Broker,由 Broker 负责推送数据。
此时 Broker 知道最多可以推送多少条数据,那么就可以控制推送行为,不至于冲垮 Consumer。
举个例子:Consumer 发起请求时 Buffer 剩余容量为 100,Broker 每次最多返回 32 条消息。
那么 Consumer 的这次 long-polling 请求 Broker 将在执行 3 次 Push(共 Push 96 条消息)之后返回 Response 给 Consumer(Response 包含 4 条消息)。
如果采用 long-polling 模型,Consumer 每发送一次请求 Broker 执行一次响应。
这个例子需要进行 4 次 long-polling 交互(共 4 个 Request 和 4 个 Response,8 次网络操作;Dynamic Push/Pull 中是 1 个 Request,3 次 Push 和 1 个 Response,共 5 次网络操作)。
所以 Pulsar 就采用了这种消息获取模式,从 Consumer 层进一步优化消息达到时间。
我觉得这个设计非常巧妙,很多中间件的这种 long-polling 模式都可以参考这种思想去做一个改善。
总结
Apache Pulsar 很多设计思想都和其他中间件不一样,但无疑于其更加贴近于未来。
大胆预测一下其他的一些消息中间件未来的发展也都会向其靠拢,目前国内的 Pulsar 使用者也是越来越多,腾讯云提供了 Pulsar 的云版本 TDMQ。
当然还有一些其他的知名公司华为,知乎,虎牙等等有都在对其做一个逐步的尝试,我相信 Pulsar 真的是一个趋势。
最后也让我想起了最近大江大河大结局的一句话:
所有的变化,都可能伴随着痛苦和弯路,开放的道路,也不会是阔野坦途,但大江大河,奔涌向前的趋势,不是任何险滩暗礁,能够阻挡的。道之所在,虽千万人吾往矣。
作者:咖啡拿铁
编辑:陶家龙
出处:转载自公众号咖啡拿铁(ID:close_3092860495)