近日,可能是汪峰放出消息月底要发新歌,所以网上的爆料不断:饿了么骑手因薪资纠纷自焚,郑爽张恒孩子出生证明曝光,腾讯QQ读取浏览器历史,字节跳动开撕百度一审获赔40元,猛料一个接一个。不过,作为安全媒体,嘶吼还是最关注“腾讯QQ读取浏览器历史”这件事。
1月17日,某论坛流出消息:“QQ会读取网页浏览器的历史记录”。随后,该内容被链接到知乎上提问,引发广泛关注。
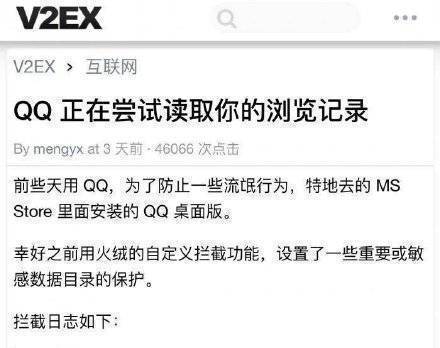
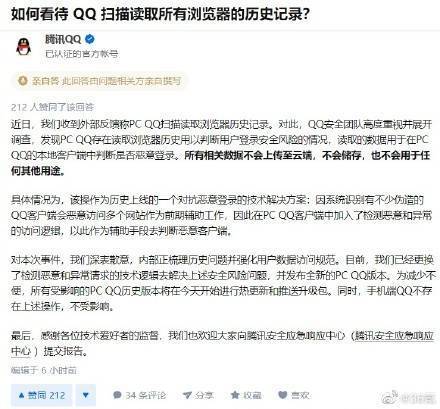
事情曝出后,腾讯QQ在其知乎官方号上做出回应:
- 近日,我们收到外部反馈称PC QQ扫描读取浏览器历史记录。对此,QQ安全团队高度重视并展开调查,发现PC QQ存在读取浏览器历史用以判断用户登录安全风险的情况,读取的数据用于在PC QQ的本地客户端中判断是否恶意登录。所有相关数据不会上传至云端,不会储存,也不会用于任何其他用途。
- 具体情况为,该操作为历史上线的一个对抗恶意登录的技术解决方案:因系统识别有不少伪造的QQ客户端会恶意访问多个网站作为前期辅助工作,因此在PC QQ客户端中加入了检测恶意和异常的访问逻辑,以此作为辅助手段去判断恶意客户端。
同时腾讯做出道歉:对本次事件,我们深表歉意,内部正梳理历史问题并强化用户数据访问规范。目前,已经更换了检测恶意和异常请求的技术逻辑去解决上述安全风险问题,并发布全新的PC QQ版本。为减少不便,所有受影响的PC QQ历史版本将在今天开始进行热更新和推送升级包。同时,手机端QQ不存在上述操作,不受影响。
事件爆出后,陆续也有程序员进行复现,发现QQ读取浏览器历史的行为包括:读取浏览器浏览历史,对读取到的url进行md5,并在本地进行比较,在md5匹配的情况下,上传相应分组ID。
安全圈内也发出不少声音,有穷追猛打伺机宣传自己的,也有利用技术分析最后澄清的,这里的前世今生,人情世故什么的不做多说。嘶吼只想作为一个中立的行业媒体谈一谈自己的态度。
首先,QQ在未授权的情况下读取浏览器历史记录,解释说是为了检测恶意和异常访问?敢问什么检测机制是需要对比历史记录中的搜索链接,比如:淘宝、天猫、京东等。又有什么检测机制要根据比较搜索的关键字呢?在常用设备上得到这些就可能判断异常访问?比起那些异地登录警告、非常用设备登录等安全防护措施,这个解释未免显得有些惨白。
其次,腾讯QQ在声明中说,所有相关数据不会上传至云端,不会储存,也不会用于任何其他用途。难道你的日记被陌生人看了,然后向你保证绝对不会外泄,这就不犯法了吗?事实就是事实,不管怎么解释,责任还是难辞其咎。不过,腾讯QQ在声明中也表明要调整此功能缺陷的问题,诚恳的态度还是值得认可的。
其实,很多App都存在越权访问的问题,而大数据时代下的安全问题也非一朝一夕可以攻克的。不过,作为安全媒体,我们还是希望企业可以重视隐私保护问题,为中国创造大数据时代下的一片净土。
如若转载,请注明原文地址