上次介绍了堆排序,这次介绍堆排序常见的应用场景TopK问题。
利用堆求TopK问题TopK问题是一个堆排序典型的应用场景。
题目是这样的:假设,我们想在大量的数据,如 100 亿个整型数据中,找到值最大的 K 个元素,K 小于 10000。对此,你会怎么做呢?
对标的是Leetcode第215题:「数组中的第K个最大元素。」
具体链接:https://leetcode-cn.com/problems/kth-largest-element-in-an-array/
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
- 示例 1:
- 输入: [3,2,1,5,6,4] 和 k = 2
- 输出: 5
- 示例 2:
- 输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
- 输出: 4
经典的TopK问题还有:最大(小) K 个数、前 K 个高频元素、第 K 个最大(小)元素
对此TopK问题本质上是一个排序问题,排序算法一共有十个,这个还有很多排序算法没有介绍过。
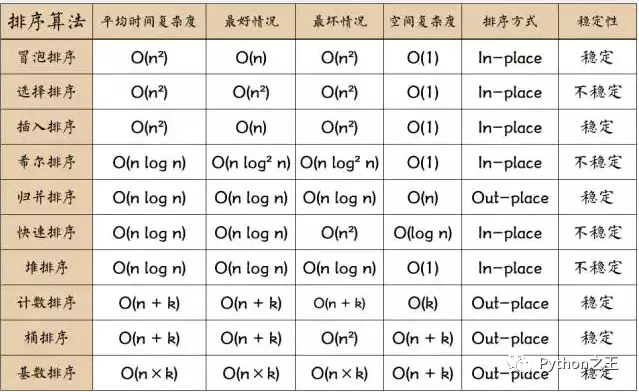
至于为什么TopK问题最佳的答案是堆排序?其实在空间和时间的复杂度来考量,虽说快排是最好的排序算法,但是对于100亿个元素从大到小排序,然后输出前 K 个元素值。
可是,无论我们掌握的是快速排序算法还是堆排序算法,在排序的时候,都需要将全部的元素读入到内存中。也就是说,100亿个整型元素大约需要占用40GB的内存空间,这听起来就不像是普通民用电脑能干的事情,(一般的民用电脑内存比这个小,比如我写文章用的电脑内存是 32GB)。
众所周知,快速排序和堆排序的时间复杂度都可以达到,但是对于快速排序来说,数据是顺序访问的。而对于堆排序来说,数据是跳着访问的。比如堆排序中,最重要的一个操作就是数据的堆化。因此,快速排序的时间复杂度是优于堆排序的。
但是快速排序是新建数组,空间复杂度是,远低于堆排序的。对于庞大的数据量,应该优先选择堆排序。
如果使用heapq内置模块,寻找数组中的第K个最大元素就是一行代码,heapq中的nlargest接口封装好了,返回的是一个数组,需要切片取值。
- import heapq
- class Solution:
- def findKthLargest(self, nums: List[int], k: int) -> int:
- return heapq.nlargest(k,nums)[-1]
当然,一般都是手写堆排序,寻找数组中的第K个最大元素建立最小堆,寻找数组中的第K个最小元素建立最大堆,
思路:「取nums前K个元素建立大小为K的最小堆,后面就是维护一个容量为k的小顶堆,堆中的k个节点代表着当前最大的k个元素,而堆顶显然是这k个元素中的最小值。」
因此只要遍历整个数组,当二叉堆大小等于K后,当遇见大于堆顶数值的元素时弹出堆顶,并压入该元素,持续维护最大的K个元素。遍历结束后,堆顶元素即为第K个最大元素。时间复杂度。
- class Solution:
- def findKthLargest(self, nums: List[int], k: int) -> int:
- heapsize=len(nums)
- def maxheap(a,i,length):
- l=2*i+1
- r=2*i+2
- large=i
- if l<length and a[l]>a[large]:
- large=l
- if r<length and a[r]>a[large]:
- large=r
- if large!=i:
- a[large],a[i]=a[i],a[large]
- maxheap(a,large,length)
- def buildheap(a,length):
- for i in range(heapsize//2,-1,-1):
- maxheap(a,i,length)
- buildheap(nums,heapsize)
- for i in range(heapsize-1,heapsize-k,-1):
- nums[0],nums[i]=nums[i],nums[0]
- heapsize-=1
- maxheap(nums,0,heapsize)
- return nums[0]
相反如果是求前k个最小,那么就用最大堆,因此面对TopK问题,最完美的解法是堆排序。因此,只有你看到数组的第K个……,马上就是想到堆排序。
如果在数据规模小、对时间复杂度、空间复杂度要求不高的时候,真没必要上 “高大上” 的算法,写一个快排就很完美了。
TopK问题就像搜索引擎每天会接收大量的用户搜索请求,它会把这些用户输入的搜索关键词记录下来,然后再离线地统计分析,得到最热门的Top10搜索关键词,啥啥惹事就出来了。
本文已收录 GitHub https://github.com/MaoliRUNsen/runsenlearnpy100