












本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
虽然GPT-3没有开源,却已经有人在复刻GPT系列的模型了。
例如,慕尼黑工业大学的Connor Leahy,此前用200个小时、6000RMB,复现了GPT-2。
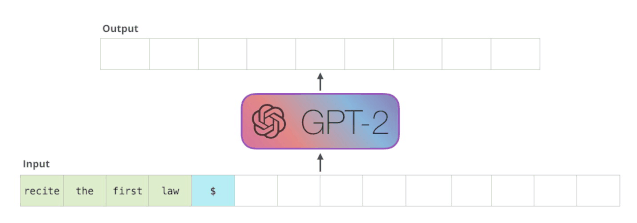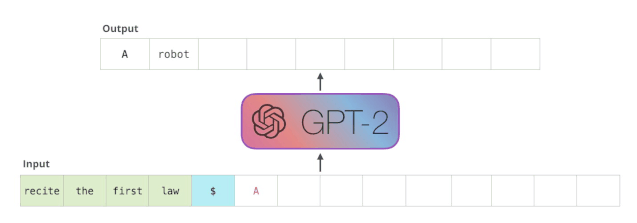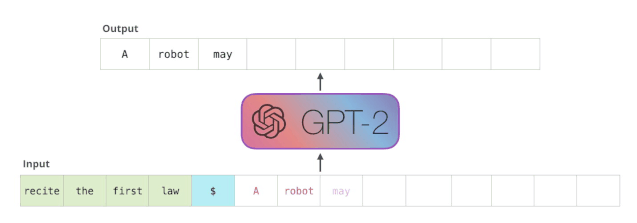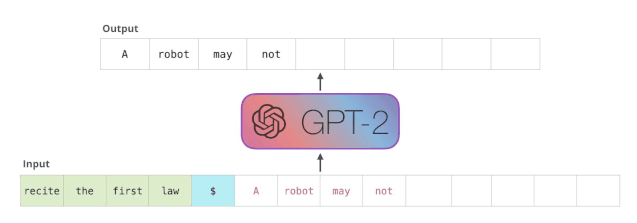
又例如,基于150亿参数版GPT-3的DALL·E模型刚出,来自康奈尔大学的Philip Wang就开始复现了。
但此前,还没人能复现出GPT-3大小的大语言模型来。
不过,已经有人开始尝试了。这是一个名为GPT-Neo的项目,用于复现GPT系列的各种语言模型,当然也包括GPT-3。

作者表示,目前他们已经成功制造出GPT-2大小的模型。
从项目代码的可扩展性来看,他们预计可以复刻出GPT-3大小的语言模型,甚至比GPT-3更大。
不仅如此,由于这是个开源的项目,大家还可以自主训练这些模型(将来也会包括GPT-3)。
目前,作者已经给出了详细的训练步骤。
消息一出,网友沸腾了:
要是真能复现,说不定会比现在的GPT-3还要更好用!

GPT系列的“高仿”项目
本质上,GPT-Neo有点像是GPT系列的“高仿”项目:
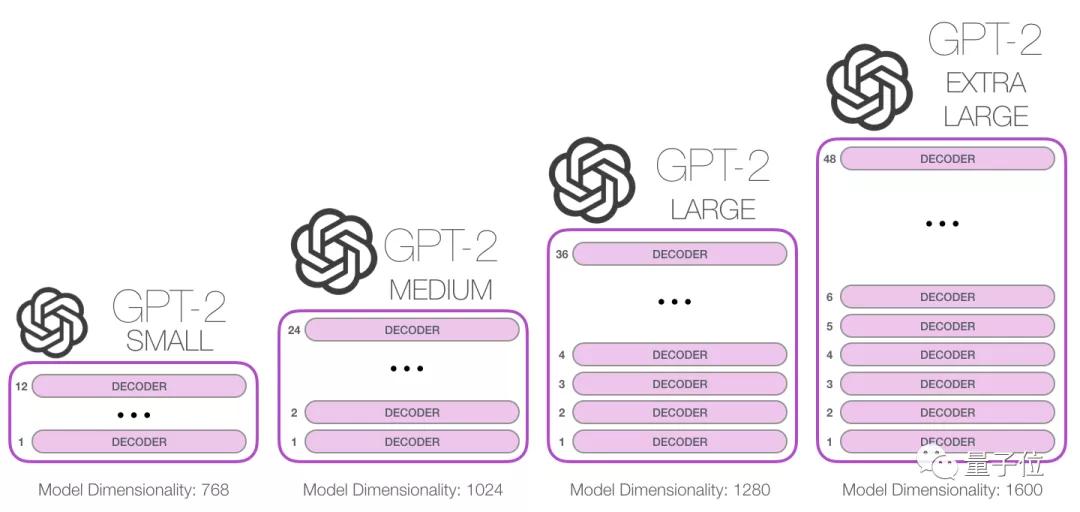
GPT-Neo中的各种模型,设计原理接近GPT系列,但代码并不一样。

作者们打算尝试各种结构和注意力类型,最终扩展出GPT-3大小的大语言模型。
为了实现这一目标,他们从复现GPT系列的模型开始,不断尝试各种模型架构、和各种注意力机制的实现方式。
也就是说,GPT-Neo更像是一个实验性质的项目,通过各种尝试,扩展出更大的模型。
这里面,融合了各种让模型变得“更大”的研究:
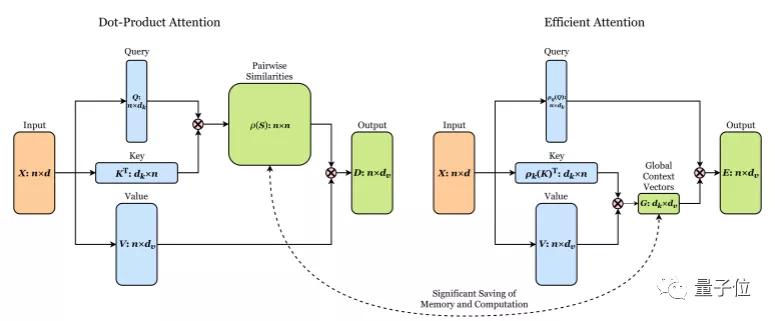
例如,多任务学习方法MoE(Mixture of Experts),采用多个专家的结构,将问题空间划分为同质区域,然后采用分发器,决定问题应该问哪些专家。
又比如,具有线性复杂性的自注意力机制。
……
这个项目还在施工中,不过,连模型的训练方式都准备好了。
项目计划通过TPU或GPU,对大语言模型进行训练。
为此,作者们已经基于Tensorflow-mesh(用于在GPU上训练模型)、Deepspeed(用于在TPU上训练模型)两个项目,编写了GPT-Neo的训练代码。
这两个项目都可以扩展到大于GPT-3的大小,甚至还能更大。
因此,训练GPT-3大小的模型,软件理论上是可行的。
但硬件上的问题,目前作者们还在思考明确的解决方案。如果将来真的做出了GPT-3大小的模型,他们打算先从谷歌那多要点免费资源,如果不行的话,就再说……

如何训练GPT-Neo
当然,在TPU和GPU上训练的方式有所不同。
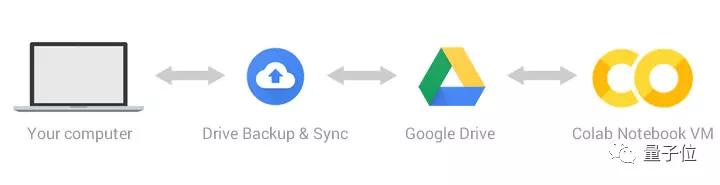
如果使用TPU训练的话,需要注册一个谷歌云平台,创建存储空间,然后再搞个虚拟机,将模型放到TPU上训练。

不过,如果你的GPU硬件足够OK,也可以选择直接训练GPT-Neo,就不用设置一系列谷歌云了。
此外,也可以用谷歌Colab来训练项目,它免费提供TPU-V8S处理器,训练GPT的3XL(1.5B参数)版本绰绰有余。
训练过程也不复杂,主要包括创建分词器、数据集预处理、指定训练数据集、选择训练配置、训练模型几个步骤。
在创建分词器上,GPT-Neo目前提供一个Huggingface的预训练GPT-2分词器。不过,也可以训练自己专属的分词器。
然后,对数据进行预处理,可以直接下载项目提供的数据,也可以使用自己的数据集。
在那之后,指定模型训练所用的数据集,然后对训练方式进行设置,例如优化算法、训练步数等。

然后,指定硬件名称、数量,就可以开始训练模型了。
“只会用谷歌搜索的自动化团队”
不过,对于GPT系列的项目复现,有网友并不看好。
网友认为,GPT-X系列项目,就像是一个由几百人组成的自动化团队,这几百人只会用谷歌搜索来干活,而且还没办法写出最新的新闻事件报道。(因为训练数据无法一直更新)
它虽然是个非常有趣的研究,但目前却还没有一个“杀手级”应用,来让GPT-3项目的存在变得更有意义。

当然,也有人认为,复现这一项目还是有意义的。
即使只是“几百个只会用搜索引擎干活的团队”,他们也需要快速给出某个问题的答案。
如何在大量零碎信息中,高效地选出最优解,本身就是GPT-X项目的价值之一。毕竟如果只是几百个“会用谷歌搜索”的人组成的团队,是无法像GPT-3一样,快速得出最佳答案的。

当然,也有一些程序员调侃,要是这个GPT-3项目真的被复现了,岂不是他们马上就要失业了。
“我们总是在用谷歌搜索、和stackoverflow来解决问题。这不就是像GPT-3一样,只会整合搜索引擎上的信息,来解决问题吗?”
“该死,原来GPT-3竟然可以取代这么多程序员。”

目前,GPT-Neo的所有项目和代码已开源。
想要上手一试、或是对项目感兴趣的小伙伴,可以行动起来了~
项目地址:
https://github.com/EleutherAI/gpt-neo



























