我认为前端开发中问题很多,尤其是以下3点。
-
UI老变,导致开发必须跟紧
-
逻辑挑战,开发也必须改代码,很多后端处理逻辑都在里面
-
组合接口,这是历史原因,主要是和后端配合导致的。其实没有Node BFF层,都由组件来做,会问题非常多。
最近我们的开源项目 iMove 一天就涨了 280+ star,一举登上了 github 趋势榜第 1 名,取得的成绩还是不错的,说明这个项目定位准确,确确实实解决了开发者问题。
今天,就通过本篇文章和大家介绍一下 iMove 开源项目,内容包含iMove功能和实现原理、独创的在线代码运行能力,以及如何自动解析节点的npm包依赖,还是有非常多亮点和创新的。
关于 iMove
简单讲,其实我们理想的前端可以做以下4点。
-
逻辑可组装:其实是接口和UI在最小粒度上的复用。
-
流程可视化:这些可复用的最小单元,可以通过流程来进行编排,继而达到让运营简化的目的。
-
运营配置收敛:这是因为多套系统导致运营成本很高导致的,统一放到一起最好。
-
玩法能力沉淀:促使产品将玩法进行沉淀,变成可复用的能力。
对开发者而言,iMove恰好是可以完成这些目标的理想工具。动动鼠标,写一下节点函数,代码导出,放到具体工程里就可以直接使用,是不是很方便?
那么,什么是 iMove?
-
它是个工具,无侵入性。
-
双击编写函数,编排后的流程可以导出可执行代码,便于在具体项目里做集成。
-
测试方便,右键直接执行,此处有创新。
-
让开发像运营配置一样完成功能开发,做到复用和Lowcode。
举个栗子
上面这些介绍,也许看着没什么体感,不容易理解,让我们一起来看个例子~
假如有天你接到了一个 详情页购买按钮 的需求:
-
获取详情页的商品信息
-
商品信息包含以下
-
-
当前用户是否已经领券
-
商品领券是需要关注店铺还是加入会员
-
-
根据返回的商品信息,购买按钮有以下几种形态
-
-
如果已经领券,按钮展示 "已领券 + 购买"
-
如果没有领券
-
-
-
-
如果领券需要关注店铺,按钮展示 "关注店铺领券 + 购买"
-
如果领券需要加入会员,按钮展示 "加入会员领券 + 购买"
-
-
-
-
异常情况时,展示兜底样式
-
-
注意:如果用户未登录,唤起登录页
我们可以将以上这段复杂的业务逻辑转化成如下这段示意伪代码:
- // 检查登录
- const checkLogin = () => {
- return requestData('/is/login').then((res) => {
- const {isLogin} = res || {};
- return isLogin;
- }).catch(err => {
- return false;
- });
- };
- // 获取详情页数据
- const fetchDetailData = () => {
- return requestData('/get/detail/data').then((res) => {
- const {
- hasApplied,
- needFollowShop,
- needAddVip,
- } = res;
- if(hasApplied) {
- setStatus('hasApplied');
- } else {
- if(needFollowShop) {
- setStatus('needFollowShop');
- } else if(needAddVip) {
- setStatus('needAddVip');
- } else {
- setStatus('exception');
- }
- }
- }).catch(err => {
- setStatus('exception');
- });
- };
- checkLogin().then(isLogin => {
- if(isLogin) {
- return fetchDetailData();
- } else {
- goLogin();
- }
- });
诚如上述例子所示,虽然业务复杂度并不是非常高,但其背后的沟通和理解成本其实并不低,想必大家在各自业务中遇到的实际场景比这复杂棘手得多。然而,业务逻辑的复杂度决定了代码的复杂度,越复杂的代码越难维护,假如某天你接手了一个逻辑很复杂的他人项目,这其中的维护成本是非常高的。不过这也正是 iMove 所解决的问题之一,面对上述同样的业务需求,我们来看看使用 iMove 是如何开发的。
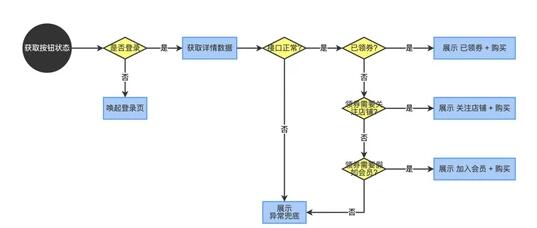
如上所示,原本晦涩难懂的代码逻辑通过 iMove 以流程图的形式表达了出来,现在产品的业务逻辑一目了然。除此之外, iMove 中的每个节点都是支持编写代码的,而流程图的走向又决定了图中节点的执行顺序,可以说 "流程可视化即天然的代码注释" 。
因此,就从 "易读性" 和 "可维护性" 上来看: iMove 流程可视化的形式 > 产品经理的 PRD 文字描述形式 > 程序代码形式。
应用场景
前端React组件一般在ComponentDidMount里发起请求,根据请求成功的数据完成渲染或其他业务逻辑,这种是完全无UI的Ajax请求处理。除了组件声明周期,就只有各种交互事件里,这里面一般是UI和Ajax混用的场景。
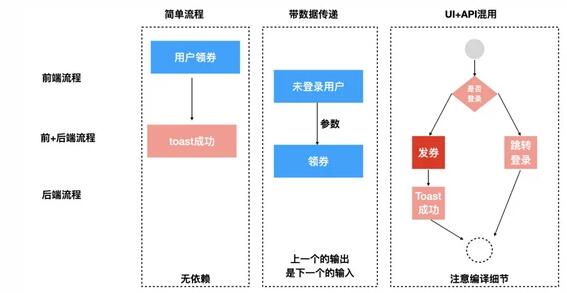
-
前端流程,比如点击事件,组件生命周期回调等。
-
后端流程,比如Node.js或Serverless领域。
-
前端+后端,比如前端点击事件,Ajax请求和后端API。
优势
上文提到的内容只是 iMove 的冰山一角,我们一起来看下 iMove 都有哪些优势:
1)逻辑可复用
面对频繁迭代的日常业务需求,我们一定会遇到许多相似、重复的开发工作。体现在代码中它可以是一段通用的 utils 工具方法,也可以是一段通用的业务逻辑代码(比如分享),但究其本质它们就是一个 代码片段 。为了提高代码的复用,我们往往会将其封装成一些通用的类或函数,然后在各个项目中拷贝粘贴(做得好一点可以将其封装成 npm 包,但修改发布的流程又会稍显繁琐)。
而在 iMove 中,每个可复用的代码片段都可以被封装成流程图中的节点。当想在不同项目中复用逻辑的时候,直接引入对应的节点/子流程即可,每个节点还支持参数配置,进一步提升了节点的复用性,使用体验可以说是非常简单了。
再往后设想一步,假如 iMove 已经在某个业务场景中沉淀了一定量的业务节点,当下次再遇到相似的业务需求时,逻辑部分是否可以直接复用现成的节点拼装而成。这可是大大提升了研发效率,缩短了项目的研发周期。
2)面向函数
在节点的设计方面, iMove 做得比较克制,每个节点其实就是导出一个函数,因此编码体验上几乎没有什么上手成本,只要你有JavaScript基础就能使用。你可以照常 import 其他 npm 包,也不用考虑节点之间的全局变量命名污染等问题,将它当做一个普通的 js 文件即可。
3)流程可视化
我们将流程可视化的这种开发方式称之为 "逻辑编排" ,它的好处(逻辑表达更为直观,易于理解)前文已经介绍过,这里就不再重复赘述。
4)逻辑/UI 解耦
我们在日常业务开发中经常会遇到: UI 样式经常变化,而业务逻辑较为稳定,甚至还会有 ABTest 需求查看改版效果 。
然而许多开发者在组件开发之初并不会设想到将来会有这一步,因此一个业务组件往往会将 "业务逻辑" 和 "UI样式" 耦合在一起。而到了改版的时候才会发现要想抽离和复用业务逻辑并不容易,维护成本也大大增加。
不过当你使用 iMove 开发之后就会发现:组件代码自然而然就拆成了 "业务逻辑" + "UI样式"。而且,不同版本的 UI 可以维护多套,但业务逻辑部分只要交给 iMove 维护一套即可。这样的开发方式不仅可以最大程度地复用业务逻辑代码,而且还提高了项目的可维护性。
5)更简单的代码测试
为了提升 iMove 的使用体验,我们实现了 "浏览器端在线运行节点代码" 的功能。这意味着当完成一个节点的函数功能时,你随时可以在浏览器端 mock 各种输入来测试该节点的运行结果是否符合你的预期。
也就是说,在无须引入测试框架、脱离上下文环境的前提下,你就可以单独对某一个节点的函数进行测试,这大大降低了代码测试的成本和门槛。与此同时,你还可以顺手将每次的测试输入/输出作为测试用例进行保存,渐而形成一份完备的测试用例,这不但可以保障该节点的代码质量,还可以更放心得被引用在其他项目当中。
6)无语言/场景限制
虽然 iMove 本身是一个 JavaScript 工具库,但在我们的设计中 iMove 并没有对使用语言和场景加以限制。也就是说,你不仅可以用 iMove 编排前端项目中的 js 代码,同样也可以用 iMove 编排后端项目中的 java 代码,甚至其他场景的其他语言。而这一切,其实最终只取决于 iMove 将流程图编译出码成什么语言而已。
iMove 原理
在对 iMove 的项目背景有了一定了解后,本文接下来将带大家一起揭开它背后的技术原理~
如何搭建可绘制的流程图应用?
抛开 iMove 偏开发的功能不说,大家完全可以把它当做一个流程图的绘制工具来使用(画完之后还可以导出图片保存到本地~)。那么 iMove 又是如何绘制流程图的呢?想必大家一定对此比较好奇,这里必须得给蚂蚁团队做的 X6 引擎点个赞 :+1: ,真的很好用~
X6 本身并不和 React 或 Vue 捆绑,因此你可以在任何框架内配合 X6 一起使用。除此之外,它提供了一系列开箱即用的交互组件和简单易用的节点定制能力,只需简单调用一些 API 就能快速实现相应的功能。
点击i
后续我们会专门出一篇文章介绍 iMove 如何使用 X6 快速搭建一个可绘制的流程图应用。

imove的核心就是基于x6协议实现的。
-
有节点:利用x6的可视化界面,便于复用和编排。
-
有指向边:即流程可视化,简单直观,边上还可以带参数。
-
有function和schema2form,支持函数定义,这是面向开发者的。支持form,让每个函数都可以配置入参,这部分是基于阿里开源的form-render实现的。
整个项目难度不大,基于x6和form-render进一步整合,将写法规范化,将编排工具化,这样克制的设计使得imove具备小而美的特点,便于开发使用。
如何将流程图编译成可运行代码?
相比于绘制流程图, iMove 更吸引人的是它可以将流程图编译成业务项目中可实际运行的代码。
在线编译 vs 本地编译
首先, iMove 既支持浏览器端在线编译提供 zip 包下载,也支持本地命令行 watch 实时编译出码。
1)在线编译
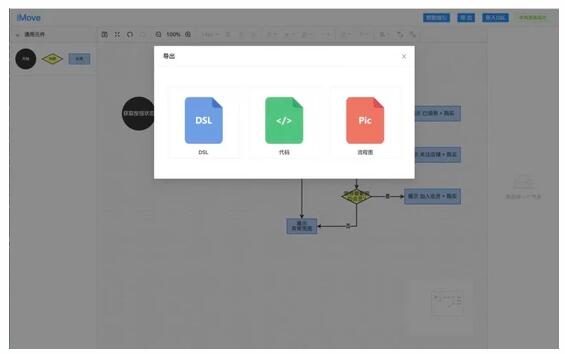
为了降低 iMove 的上手成本,我们加入了浏览器端在线编译出码的功能,这样开发者无须安装工具就能直接下载编译好的代码。
具体该如何实现呢?经过调研,我们发现 jszip 是一个集读/写/改 zip 文件于一身的 JavaScript 库,而且还支持浏览器端运行。因此,我们完全可以按照出码的文件目录生成一个 json 丢给 jszip 打包,最后再用 file-saver 提供下载即可。
- // key 是"文件/目录名",value 是对应的"文件内容"
- {
- "nodeFns": {
- "node1.js": "...",
- "node2.js": "...",
- "index.js": "..."
- },
- "context.js": "...",
- "dsl.json": "...",
- "index.js": "...",
- "logic.js": "..."
- }
2)本地编译
在线编译的方式固然简单,但在项目开发中会遇到一个问题: 每次修改代码都需要重新下载 zip 包并解压到指定目录,尤其是调试时需要频繁修改代码会非常不便 。为了解决这个问题, iMove 提供了本地编译的方式,通过 watch 流程图的保存操作,实时地编译出码到业务项目中。
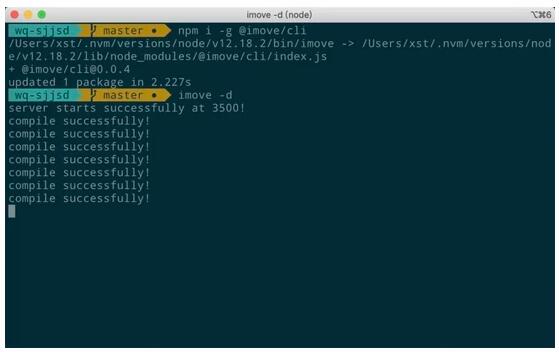
具体该如何实现呢?上述问题的关键在于: 本地如何监听浏览器端的流程图保存操作 。但是反过来想,为什么不可以是 流程图在保存时发送消息通知本地呢? 这么一来,我们既可以使用 socket.io 等类库在浏览器和本地之间建立 websocket 通信,也可以使用 koa / express 等类库在本地启动一个 http 服务器,只要在接收到流程图保存信号时触发编译出码即可。
iMove 代码运行基本原理
解决完 iMove 如何编译代码的问题,再来看看 iMove 编译的代码又是如何运行的。
要想运行代码, iMove 需要解决两个核心问题:
-
如何按流程图的顺序依次执行节点
-
如何处理数据流(比如上一节点的返回值是下一节点的输入)
RxJS 看起来是个不错的选择,函数响应式编程似乎天然解决上面的问题。但考虑到它的上手成本无疑会对 iMove 的使用者造成巨大的心智负担,因此最终我们并没有采用这套方案。
1)对于第一个顺序执行问题, iMove 采用了一种低成本的方式来解决:
-
首先,
X6支持导出流程图的json数据,我们可以将其精简处理后保存为一份DSL文件。 -
其次,根据这份
DSL文件,我们可以从中提取出每个节点的代码部分成为单独的文件,进而构成一个 节点函数集 。 -
最后,接下来只要按照 节点和边的上下游关系 顺序调用相应的节点函数即可。
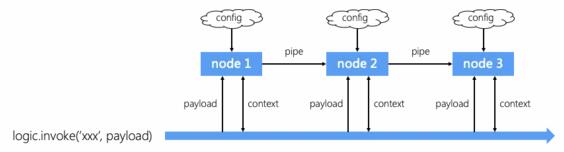
2)对于第二个数据流问题, iMove 考虑到实际应用中节点对数据操作的各种场景,一共设计了四种数据读写方式:
-
config:只读型,每个节点的投放配置,节点之间互不干扰。
-
payload: 只读型,
logic.invoke触发逻辑时,可以传一个payload值,每个节点都能读取该值。 -
pipe:只读型,上一个节点的输出是下一个节点的输入。
-
context: 可读写,某一个逻辑流中的公有数据,如果祖先节点又通过
setContext设置数据,那么子孙节点可以跨节点通过getContext访问到该数据
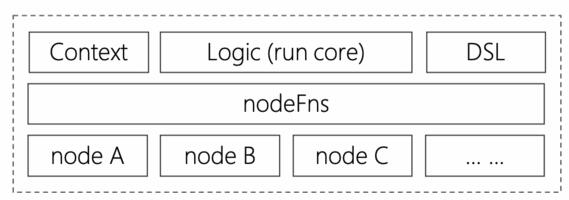
至此, iMove 解决了流程图代码运行的问题。如果你有注意 iMove 编译后的代码,就能看到如下结构:
理解Flow
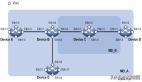
Flow的基本概念很简单,就是一个有向无环图(DAG),数据在节点间流动。

-
节点 Node
-
-
节点是组成流的主要单元,负责对流入节点的数据进行处理,并输出到后续节点进行进一步的处理。
-
-
端口 Port
-
-
每个节点拥有输入和输出端口,输入端口负责数据流入节点,输出端口负责数据流出节点。每个节点都可能拥有一个或者多个输入和输出端口。
-
-
连接 Link
-
-
一个节点的输出端口连接到另一个节点的输入端口,节点处理好的数据通过连接流入其后的节点。
-
Flow的实现基本思路就是用一个函数function实现一个节点,输入端口映射为函数的输入参数。输出端口映射为函数的返回值。
流中有一个节点被设置为终点节点(End Node),通过节点间的连接关系,以终点节点开始通过连接搜索所有的依赖关系(树形查找),得到一个节点运行的栈。例如上图,我们就可以得到一个 [node1,node2, node3] 这样的栈。按顺序出栈的方式执行每一个节点的功能就可以运行整个流。(注意,这是一个简单版本的Flow的实现,仍然是一个批处理,不是streaming)
需要假定每一个节点的功能是无状态的,这样就可以利用输入输出端口对计算结果进行缓存,但输入值是已经运算过的值的时候,不需要运算,直接返回已经计算过的值。
以上是Flow-base programing(FBP)里的Flow概念。其实这和imove里的概念是一样的。imove基于x6,x6解决了DAG实现和可视化问题,再结合节点扩展函数写法,继而实现面向开发者的逻辑编排工具。殊途同归,就是这么简单。
如何在线运行节点代码?
iMove 有个比较 cool 的功能就是可以在浏览器端在线运行节点函数代码,实时看到运行结果。这种 所见即所得 的开发体验对使用者来说还是很友好的,不但测试调试的成本大大降低,还能成为测试用例集进一步保障节点质量。
在 iMove 里编写代码,双击节点即可。
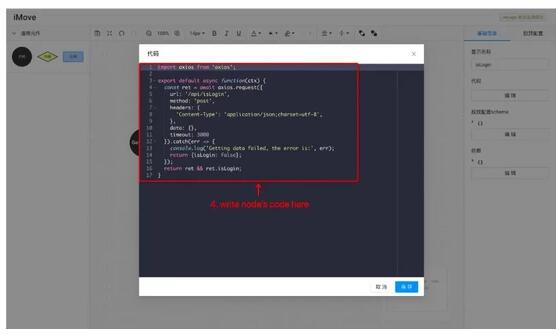
右键执行代码,即可完成对单个节点的测试。
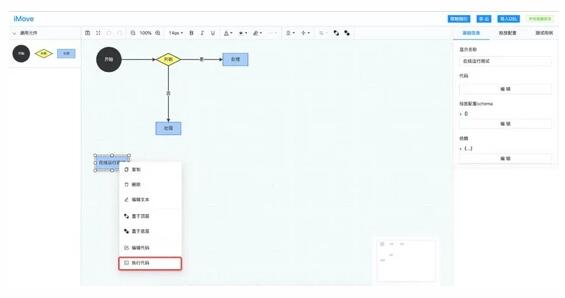
打开运行面板,填写对应参数,即可执行具体代码。
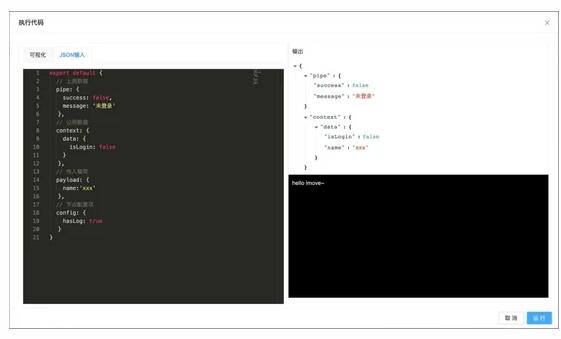
在线运行 iMove 节点代码需要解决以下一些问题:
-
浏览器端如何直接运行节点中的
import/export等esm规范代码 -
节点中
import进来的npm包还有可能是cjs规范,浏览器又该如何运行 -
同时选中多个节点时,又该如何运行代码
iMove 实现的背后原理主要还是借助 http-import ,后面我们会专门出一篇文章介绍它的实现原理,敬请期待~
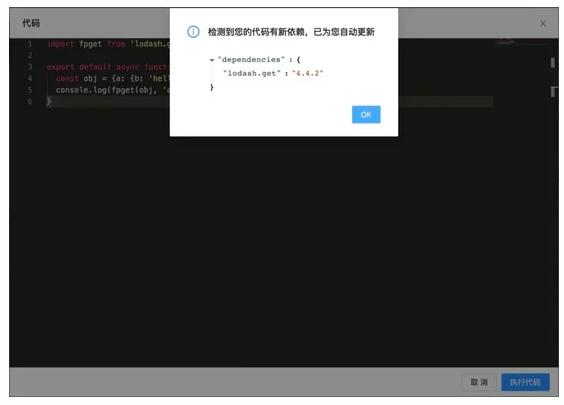
如何自动解析节点的 npm 包依赖?
由于每个 iMove 的节点都支持 import 其他 npm 包,因此每个节点都有 npm 依赖。但是,如果这项工作让开发者手动填写体验会非常差,因此我们做了自动解析的功能。
原理其实比较简单,了解 npm view 命令即可。就拿 npm view lodash.get 举例来说,查看命令行输出可以看到:
- $ npm view lodash.get
- lodash.get@4.4.2 | MIT | deps: none | versions: 13
- The lodash method `_.get` exported as a module.
- https://lodash.com/
- dist
- .tarball: https://r.cnpmjs.org/lodash.get/download/lodash.get-4.4.2.tgz
- .shasum: 2d177f652fa31e939b4438d5341499dfa3825e99
- maintainers:
- - phated <blaine.bublitz@gmail.com>
- dist-tags:
- latest: 4.4.2
- published over a year ago by jdalton <john.david.dalton@gmail.com>
如上所述,该命令成功获取到 lodash.get 这个包的最新版本。当然, npm view 命令不适合在浏览器端执行,但究其本质都会走网络请求查询。我们再用 npm view lodash.get --verbose 就能看到执行过程中其实发起了请求: https://r.cnpmjs.org/lodash.get 。
接下来就很简单了,只要根据 import 语法规则用正则匹配出节点代码中的依赖,再调用上面的 api 就可以自动解析出该节点的包依赖了。
总结
在UI侧有imgcook这样的设计稿转代码的工具,应对变化是足够的。但在逻辑领域,真正能解决问题的又面向开发者的少之又少,imove算这个方向的一个探索。相信通过上面的讲解,大家都能够感受到它的魅力。
imove的口号是 Move your mouse, generate code from flow chart ,即动动鼠标,写一下节点函数,代码导出,放到具体工程里就可以直接使用。像运营配置一样开发,这已经不是愿望,而是已经实现了的。