













本文转载自微信公众号“code秘密花园”(code_mmhy)。
作为一个前端工程师,大家日常也会维护一些 Node.js 服务,对于一个服务我们首先要关注的就是它的稳定性,可能大部分同学对服务端的很多概念不会理解的特别深刻,所以在稳定性上面也不知道去关注什么。
本篇文章我先给大家介绍一些在服务端稳定性上面我会关注的一些指标。
整体分为两个大的方面:
- 资源稳定性:即当前服务所处的运行环境的一些指标,一般如果资源稳定性的指标除了问题,那么服务有可能已经有了大问题,甚至处于不可用状态。
- 服务运行稳定性:服务运行过程中产生的异常、日志、延迟等等。
一、资源稳定性
1. CPU
(1) CPU Load
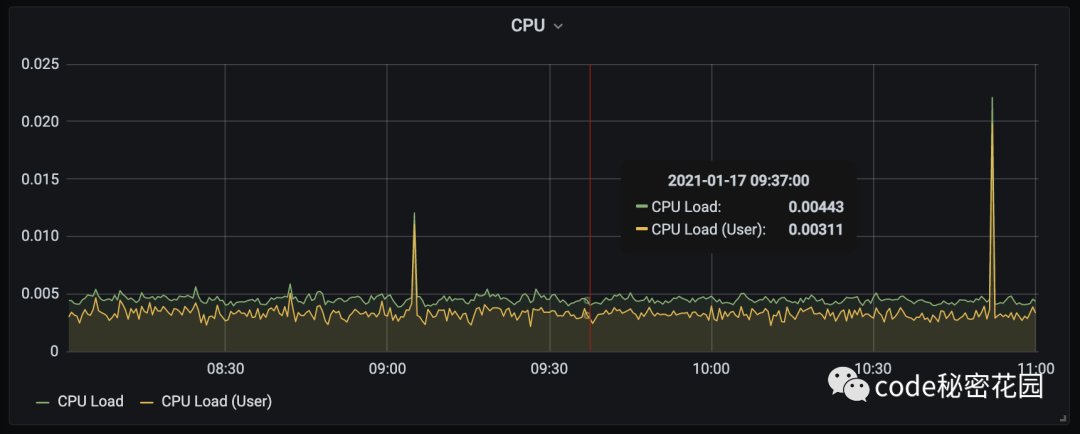
CPU Load 即 CPU 的负载,表示在一段时间内 CPU 正在处理以及等待 CPU 处理的进程数之和的统计信息。CPU 完全空闲时,CPU Load 为0,CPU 工作越饱和,CPU Load越大。
如果 CPU 每分钟最多处理 100 个进程,系统负荷0.2,意味着 CPU 在这1分钟里只处理20个进程。
下面借用下阮一峰的例子:我们把 CPU 想象成一座大桥,桥上只有一根车道,所有车辆都必须从这根车道上通过。系统负荷为0,意味着大桥上一辆车也没有。系统负荷为0.5,意味着大桥一半的路段有车。

系统负荷为 1.0,意味着大桥的所有路段都有车,也就是说大桥已经"满"了。但是必须注意的是,直到此时大桥还是能顺畅通行的。系统负荷为 1.7,意味着车辆太多了,大桥已经被占满了(100%),后面等着上桥的车辆为桥面车辆的70%。

如果容器有 2个CPU 表明系统负荷可以达到2.0,此时每个CPU都达到100%的工作量。推广开来,n个CPU的电脑,可接受的系统负荷最大为n。多核CPU与多CPU效果类似,所以考虑系统负荷的时候,必须考虑这台电脑有几个CPU、每个CPU有几个核心。
(2) CPU Usage
CPU Usage 代表了程序对 CPU 时间片的占用情况,也就是我们常说的 CPU 利用率,它可以反应某个采样时间内 CPU 的使用情况,是否处于持续工作状态,可以从 CPU 核心、占用率百分比两个角度来看。

正常情况下,CPU Usage 高,CPU Load 也会比较高。CPU Usage 低,CPU Load也会比较低。也有例外情况:
CPU Load 低,CPU Usage 高:如果 CPU 执行的任务数很少,则 CPU Load 会低,但是这些任务都是CPU密集型,那么利用率就会高。
CPU Load 高,CPU Usage 低:如果CPU执行的任务数很多,则 CPU Load 会高,但是在任务执行过程中 CPU 经常空闲(比如等待IO),那么利用率就会低。
2. 内存
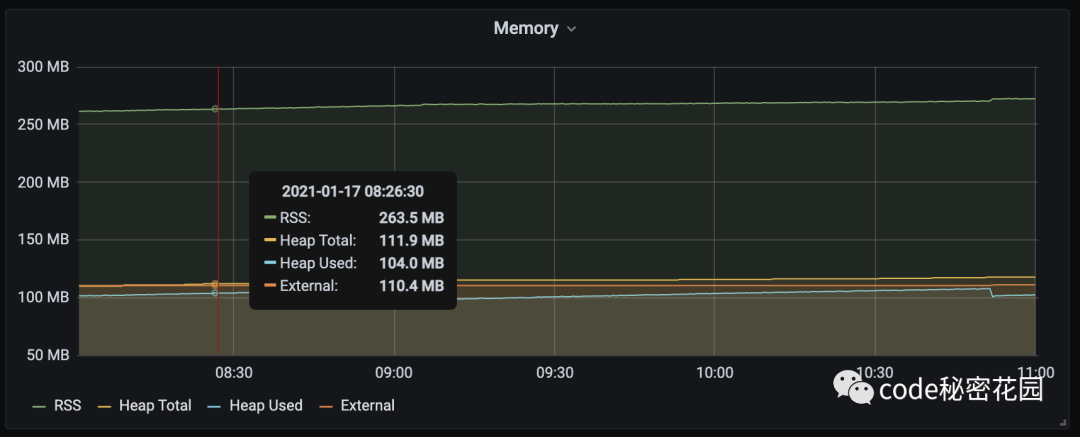
(1) 内存 RSS
RSS :常驻内存集(Resident Set Size)用于表示系统有多少内存分配给当前进程,它能包括所有堆栈和堆内存,是 OOM 主要参考的指标。
(1) 内存 V8 Heap
表示 JavaScript 代码执行占用的内存。
一般我们可以看到 V8 Heap 区分了 Used 和 Total,这里是主要是因为 V8 的内存回机制,在进程中有一些内存是可回收并且没有马上被回收的,Total - Used 实际上是指当前可以回收但没有回收的内存。
(3) 内存 max-old-space-size
V8 允许的最大的老生代内存大小,可以简单认为是一个 Node.js 进程长期可维持的最大内存大小。进程的 HeapTotal 接近这个值时,进程很可能会因为 V8 abort 而退出。
(4) 内存 External
Node.js 中的 Buffer 是基于 V8 Uint8Array 的封装,因此在 Node.js 中使用 Buffer 时,其内存占用量会被记录到 External 中。
加之 external string 在 Node.js 中使用的得很少,因此我们可以认为对一个常见的 Node.js web 应用来说,process.memoryUsage() 中 的 External 主要指的就是Buffer占用的内存量。Buffer经常被用在 Node.js 中与 IO 相关的 api 上,如:文件操作、网络通信等。
3. Libuv
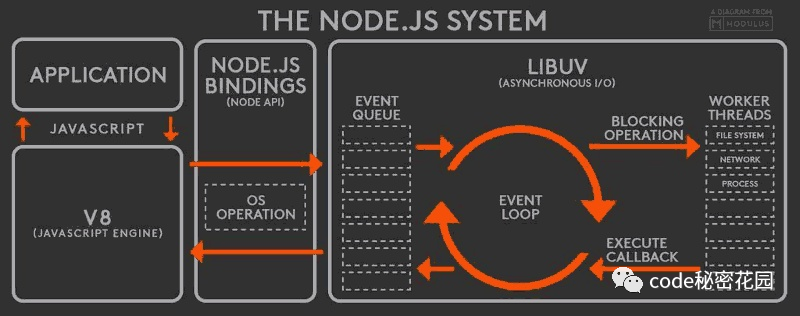
Libuv 是跨平台的、封装操作系统 IO 操作的库。Node.js 使用 Libuv 作为自己的 event loop,并由 uv 负责 IO 操作,诸如:net、dgram、fs、tty 等模块,以及 Timer 等类都可以认为是基于 uv 的封装。因此与 uv 相关的数据指标可以一定程度上反应出 Node.js 应用的稳定性。
(1) Libuv Handles
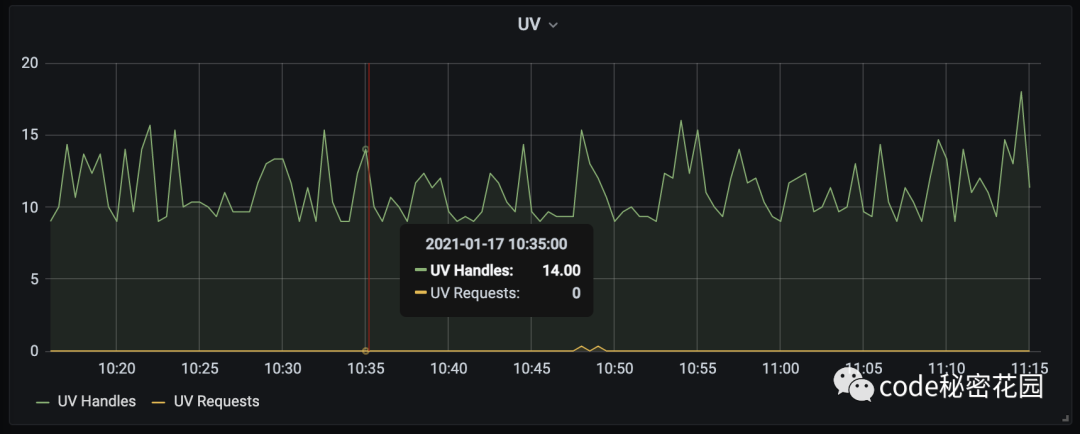
libuv handles 指示了 Node.js 进程中各种IO对象(tcp, udp, fs, timer 等对象)的数量。对于常见的 web 应用来说, libuv handles 较高通常意味着当前请求量较大或者有 tcp 连接等未被正确释放。之前在线上业务中还会经常发现有 handle 没有被关闭,如:tcp、udp socket 不断被创建,并且没有被关闭,导致操作系统的端口被耗尽的问题出现。
(2) Libuv Latency
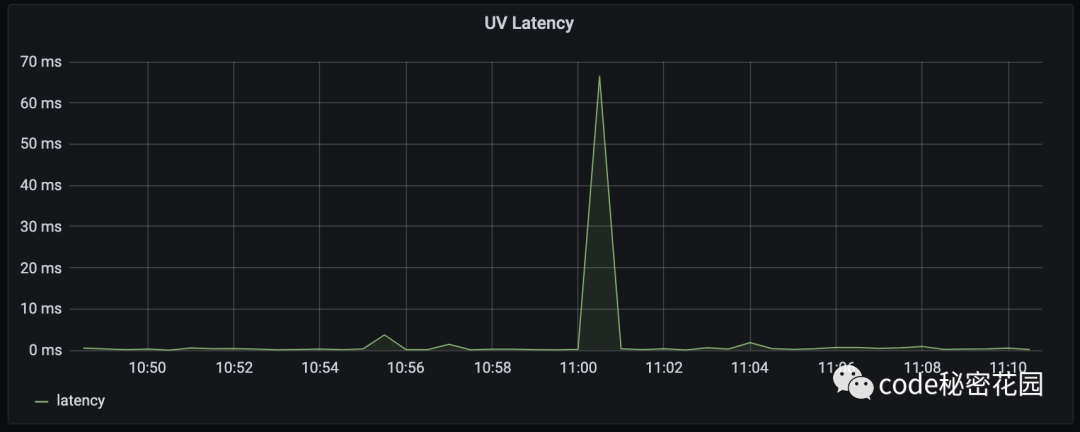
libuv latency 并不是 libuv 或 Node.js API 中可以直接获取到的数据。目前主流的、对 libuv latency 的计算方式,都是通过 setTimeout() 来设置 timer ,并记录回调函数被调用时所消耗的时间和预计消耗的时间之间的差值作为 latency ,如:
- const kInterval = 1000;
- const start = getCurrentTs();
- setTimeout(() => {
- const delay = Math.max(getCurrentTs() - start - kInterval, 0);
- }, kInterval);
latency 数值较高通常意味着当前应用的 eventloop 过于繁忙,导致简单的操作也不能按时完成。而对于 Node.js 进程来说,这类情况很可能是由调用了耗时较长的同步函数或是阻塞的 IO 操作导致。
发生这类问题时,对应的线程将没办法进行正常的服务,比如对于 http server 来说,在这段时间内的请求会得不到响应。因此我们需要保证主线程的 libuv latency尽可能的小。
二、服务运行稳定性
1. 状态码
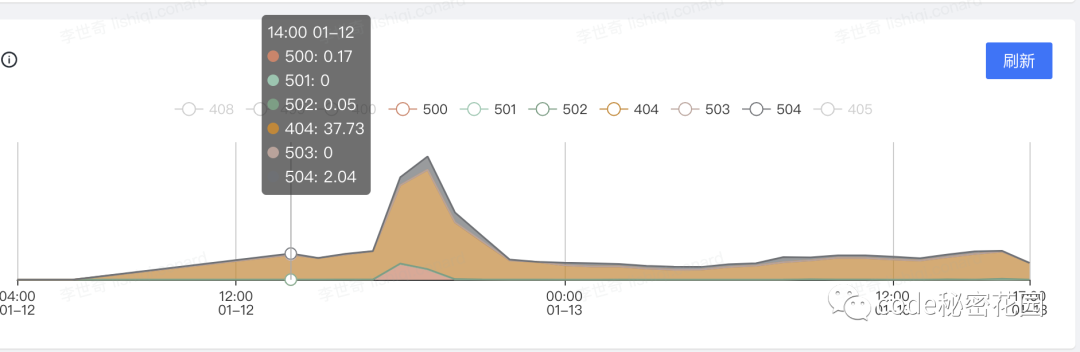
这个应该不用多说,对于服务产生的所有 5xx 的状态码都属于服务器在尝试处理请求时发生内部错误,这些错误可能是服务器本身的错误,而不是请求出错,都是需要我们关注的:
- 500 (服务器内部错误) 服务器遇到错误,无法完成请求。
- 501 (尚未实施) 服务器不具备完成请求的功能。例如,服务器无法识别请求方法时可能会返回此代码。
- 502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
- 503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。通常,这只是暂时状态。
- 504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
- 505 (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
- 506 由《透明内容协商协议》(RFC 2295)扩展,代表服务器存在内部配置错误:被请求的协商变元资源被配置为在透明内容协商中使用自己,因此在一个协商处理中不是一个合适的重点。
- 507 服务器无法存储完成请求所必须的内容。这个状况被认为是临时的。
- 509 服务器达到带宽限制。这不是一个官方的状态码,但是仍被广泛使用。
- 510 获取资源所需要的策略并没有没满足。
错误日志服务运行过程中产生的错误日志数量也是衡量一个服务是否稳定的重要指标,对于错误日志上报,不同公司的业务可能有不同的实现,但是应该大同小异,一般日志都分为 INFO、WARN、ERROR 几个级别,我们需要关注的是 ERROR 及以上级别的日志。
一般在我们的业务逻辑中,都需要对服务运行的过程中产生的异常进行捕获以及日志上报,但是我们不可能在所有程序运行的节点进行异常捕获,另外 try catch 也不是万能的,它并不能捕获异步异常,所以我们一般在我们使用的 Node.js 框架中的关键节点也会集成日志的上报,以 KOA 为例,我们需要监听 app 的 error 事件:
- this.on('error', (error, ctx) => {
- if (error.status === 404) {
- return;
- }
- const message = error.stack || error.message;
- log(message);
- });
另外,我们还需要在 uncaughtException、unhandledRejection 中进行异常上报:
- process.on('unhandledRejection', (error) => {
- if (error) {
- log({
- level: 'error',
- location: '[gulu-core]::UnhandledRejection',
- message: error.stack || error.message,
- });
- }
- });
- process.on('uncaughtException', (error) => {
- log({
- level: 'error',
- location: '[gulu-core]::UncaughtException',
- message: error.stack || error.message,
- });
- process.exit(1);
- });
进行了这样的操作后,所有在你的业务逻辑中产生的异常都会被捕获并上报,所以对于你想了解到的异常你不应该手动进行 try catch,而是将它们抛出到框架进行捕获上报。
2. pm2 日志
对于程序中我们自己打印出的一些 console ,一般生产环境是默认不会被记录的。例如某些程序异常我们可能自己通过 try catch 进行了捕获,并使用 console 输出了 ERROR INFO ,这样的异常并不会被当作错误日志进行捕获。

一般在线上运行的 Node 服务都是使用 PM2 启动的。PM2 是 node 进程管理工具,可以利用它来简化很多 node 应用管理的繁琐任务,如性能监控、自动重启、负载均衡等。
我们可以通过 pm2 log 命令来查看当前程序运行的实时日志,注意这个日志是包括开发者自己打出来的一些 console 的。
另外 pm2 也支持查看所有历史产生的日志,我们可以通过一些 Error 之类的关键字去检索错误日志。
3. 延时
延时情况也是衡量一个服务稳定性的重要指标,一些非常慢的接口除了会影响用户体验,还有可能会影响数据库的稳定性,一般我们在接口的延时和数据库的延时两个方面关注服务延时,这个比较好理解,这里我就不再多说了。
4. QPS

QPS:全名 Queries Per Second,意思是“每秒查询率”,是一台服务器每秒能够响应的查询次数,是对一个特定的查询服务器在规定 Queries Per Second 时间内所处理流量多少的衡量标准。简单的说,QPS = req / sec = 请求数/秒。它代表的是服务器的机器的性能最大吞吐能力。
正常来讲服务的 QPS 可能随着时间的变化进行有规律的增长或减小,但是如果在某段时间内 QPS 发生了成倍的数量级的增长,那么有可能你的服务正在遭受 DDoS 攻击,或者正在被非法调用。


















