对于Java 应用,程序员之间一个认识口口相传:
要看一个Java程序跑的快不快,需要多跑几次;另外,Java程序跑一段时间之后会快起来。速度甚至能赶上 C/C++程序的速度。
如果你问为什么跑一段时间就快了呢?
一般都能听到 「因为JVM会把调用次数多的热方法编译再执行」的答案。
更通俗的话来讲, JVM 会把热方法编译成机器码,执行效率会更高。就像公司或工厂里,对于一项任务,一般老手都比新人更快,因为老手更熟悉嘛。所以招聘要求里你很少会见到指明要新人的,大部分都是要有工作经验的。
而JVM 将热方法编译生成的机器码,由于是针对当前平台,当前硬件生成的,对应用具体执行情况分析之后进行编译而成,所以就像老手一样,能更了解情况,效率当然更高。
默默在背后做编译工作的人就是 JIT (Just-In-Time) 编译器,一般也叫即时编译器。
今天我们一起来看看,这越跑越快的背后,JIT 具体是怎样工作的。
我们都知道,Java 原生就是解释型语言,也是解释执行的,怎么又有了编译执行了?
执行 java -version 的时候,我们一般能看到当前 Java 版本号之后,会有一个 mixed mode,说明当前JVM 运行在混合模式之下,即同时包含解释执行和编译执行。我们也可以通过参数强制执行只按一种模式执行。各种环境根据自己的需要选择执行的方式。
相比编译执行,解释执行要慢很多,但仍然广泛在被运用在各种虚拟机中,比如它内存占用少,应用启动时间更短。更关键的优势在于它简单。一种新语言或者一个语言的新特性出现时,在解释器中能比编译器实现要快很多。另外,开发者会考虑到性价比,一些语言特性很难,同时也不值得在实现在编译器就只使用解释器。
开发实现语言时,使用解释器只有两个要求:
- 熟悉VM实现语言
- 理解新语言特性、语法和语义
而像在JIT编译器实现新语言特性,对开发者有更多的要求:
- 熟悉目标机器的应用程序二进制接口规范
- 把新语言特性映射到这个目标机器的接口运行时
- 掌握开发编译器生成目标机器码的能力
而为了应用程序的执行效率、运行速度, Java 又特别需要JIT,在运行的适当时候,可以把一些高频率代码编译,换取更好的效率。
JIT就是通过将热方法、代码段编译生成机器码的形式,在下次调用到该方法时,会直接通过vtable中链接的机器码直接执行,所以效率是杠杠的。
那么问题来了,什么样的方法才算热方法,怎样来判断热方法?
对于热方法的计算,一般虚拟机内有以下几种实现方式:
- 基于方法的JIT,JVM内常用
- 基于踪迹的JIT, Dalvik和 TraceMonkey在使用
- 基于区域的JIT,HHVM 使用这种形式
基于方法的JIT中,一般探测热点方法有基于采样的热点探测,即周期性的去检查线程的调用栈顶,如果方法经常出现在栈顶,那它就是热点方法。另一种是基于计数器的热点探测,这种会给每个方法建立计数器,用来统计方法的执行次数。超过阈值的就认为是热点方法。
当然需要注意的是,这里统计的次数,不是绝对的次数,和我们进行限流和降级时说的类似,都是一个时间周期内的相对频率,如果在此期间没有超过,就不算,原来的次数会减少。
JIT 编译的代码,存储在 Code Cache 的内存区间。空间是有限的在JVM 启动的时候,设置了一个固定的最大值,实现形式也是个堆,在分配满时会停止编译,类卸载、替换成新版本等也会从 Code Cache中删除。
另外,在JVM JIT编译器中包含C1、C2 两种编译器,在具体的编译过程中,一般是采用分层编译,再具体使用不同的编译器,相比C1,C2编译需要更多的时间,做更多的优化等等,像内联、循环展开、逃逸分析、锁消除与合并、栈上替换……
前面我们大概了解了JIT的原理,也了解到 JIT 编译后,机器码执行效率更高,那有什么办法能了解到我们自己的应用里,JIT有没有执行,用的是C1还是C2,对哪些代码做过编译和优化呢?
我们有没有办法,能知道都有哪些方法被JIT编译了,哪些方法本来我们想要效率高一些,期待被编译却没被考虑的,能更直观的知道呢?
一个办法是应用启动时,增加 JVM 参数:
- -XX:+UnlockDiagnosticVMOptions
- -XX:+PrintCompilation
- -XX:+PrintInlining
- -XX:+PrintCodeCache
- -XX:+PrintCodeCacheOnCompilation
- -XX:+TraceClassLoading
- -XX:+LogCompilation
- -XX:LogFile=~/a.log
然后根据这些输出内容,以及日志文件里的内容,去分析。
当然,如果真的是肉眼阅读那可太累了。好在有一个优秀的开源工具用于解析日志文件。
铛铛铛,来了。
就是它, JITWatch。
https://github.com/AdoptOpenJDK/jitwatch
使用 JavaFX 开发而成,功能很强大。
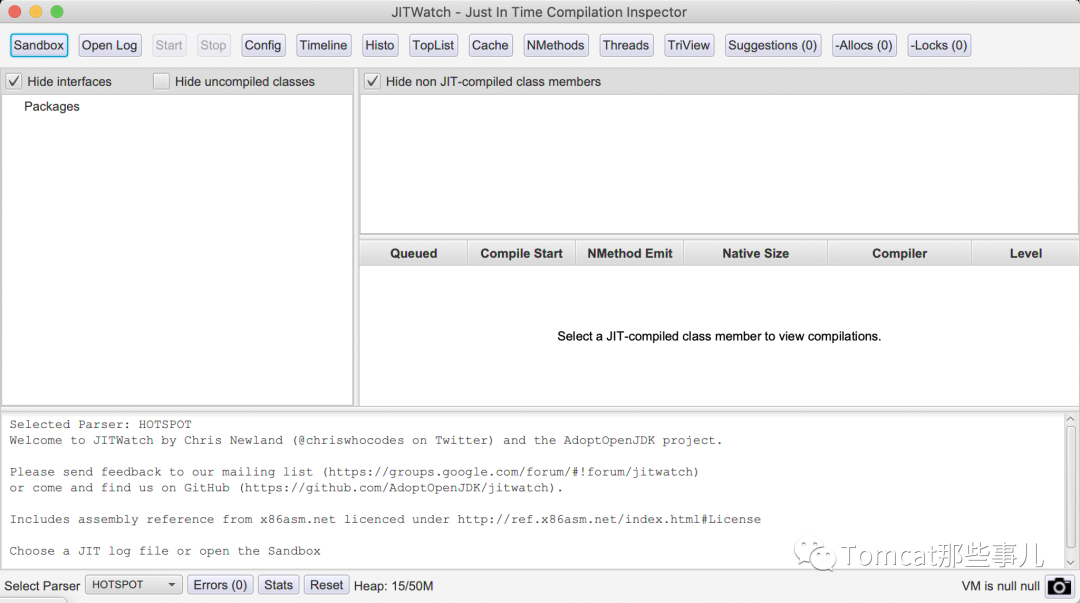
你可以 通过 Open Log 直接解析上面输出的日志文件。 例如一个简单的应用,打开日志之后,会看到不同包下的内容,这里example111 是示例。
- public void jitTest() {
- long x = calc();
- System.out.println(x);
- }
- public long calc() {
- long sum = 0;
- for (long i=0; i< 1000000; i++) {
- sum = plus(sum, i);
- }
- return sum;
- }
- public long plus(long a, long b) {
- return a + b;
- }
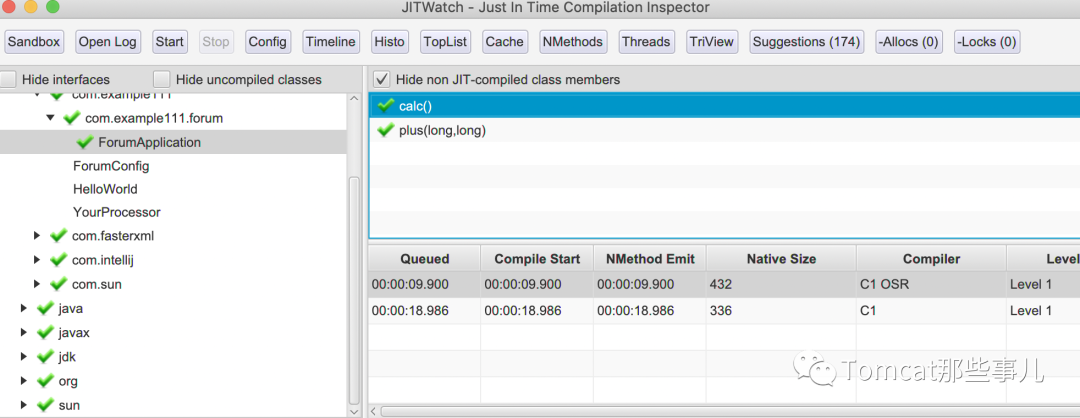
在点击右侧某个JIT编译过的具体方法后,点击TriView,会看到生成的节字码,以及相应的源码是如何对应到字节码和汇编代码的。
点击Chain,会看到编译链路
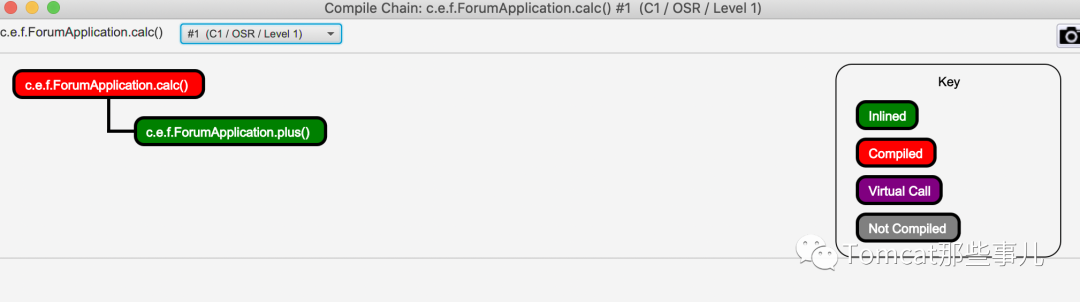
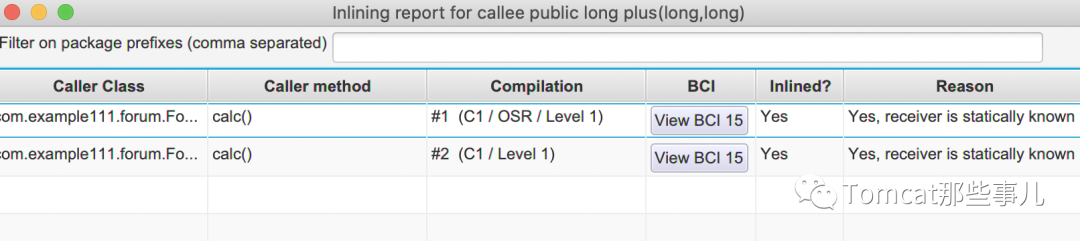
Inline-info 会显示哪些方法进行了内联优化。
这里看到的OSR,就是常听到的栈上替换(On-stack replacement),用于优化在解释器中执行时,向后跳转的循环分支达到某个阈值时就会被编译。
JITWatch 还有一个沙箱的环境,可以用来实验观察 JIT的行为,观察 JVM 里JIT的决策过程。
有了工具的帮助,我们能更好的理解JIT 对应用优化的决策,从而让应用性能更佳。