背景:高德地图车机版运行的车载系统环境绝大部分都是基于安卓的定制系统,且高德车机版底层代码均为C/C++ Native代码。因此,在安卓上需要有一种通用的Native内存性能分析方案。内存塔(MemTower)是一个基于开源项目memory-profiler并移植安卓且优化改进后的方案,解决了之前方案存在的痛点问题,满足了通用Native内存性能分析需求。该项目采用Rust语言编写,并利用了Rust的一些特性来完成对Native内存访问的Hook.
1. Android Native内存分析痛点与诉求
这一节主要介绍我们为什么要做这件事以及对于这件事我们期望达到什么样的目标。
1.1 现有工具缺陷
Android在Java层面有很完善的性能分析工具,但是在Native层面没有完整的解决方案。主要表现在:
- 不支持Android 4.x,线上统计数据显示4.x版本的车机仍占有较大比重,因此这点成为了无法忽视的问题。
- 安卓自带的malloc_debug功能在不同的版本上行为不同,而且车机安卓系统大多经过了系统厂商的定制,不能保证这些功能可用。
因此, 无法基于Android系统自有的功能做到Native内存性能分析。
我们团队之前也在这方面做出了一些成果,但还是存在下面几个问题:
- 通过修改编译参数对Native代码函数入口/结束位置插桩来进行Hook,导致了性能严重下降;
- 由于是侵入式分析,对内存问题分析需要单独编译出包分析,解决效率大幅降低,一个内存泄漏问题的排查成本按天计算。
- 缺少精准内存使用数据。
1.2 打造一套完整的Native内存性能分析方案
结合上门的问题痛点,我们希望能够有一套完整的Native内存性能分析方案。具体诉求表现在下面几点:
- 支持安卓4.x在内的绝大多数安卓系统。
- 无侵入式分析,内存问题的发现与精准定位同时完成。
- 性能优异,overhead低。
- 支持长时间内存泄漏压测。包括车厂客户在内的研发团队都会对导航进行压测,需要能够支持长时间的压测并定位内存泄漏问题。
- 函数级内存使用数据。原先的方案重点在于解决内存泄漏的问题,获取的内存使用数据不够精确。而我们希望新的方案能够获得详细的内存使用数据,用来支持内存性能优化。
2. 内存塔(MemTower)方案
本节主要介绍memory-profiler项目的实现和内存塔(MemTower)方案在移植该项目至Android平台上的过程和对原方案的改进。阐述我们是如何实现并满足上述的诉求。
2.1 选择Rust & Memory-profiler
针对上门的诉求,期望能够找到一种新的解决方案。当时正好在研究Rust,因此在GitHub上结合关键字搜索便发现了memory-profiler(以下简称mp)项目,作者koute是前Nokia工程师。接着才有了后面的内存塔。本节主要阐述mp如何结合Rust实现内存Profile的相关原理和功能。
2.1.1 Hook实现
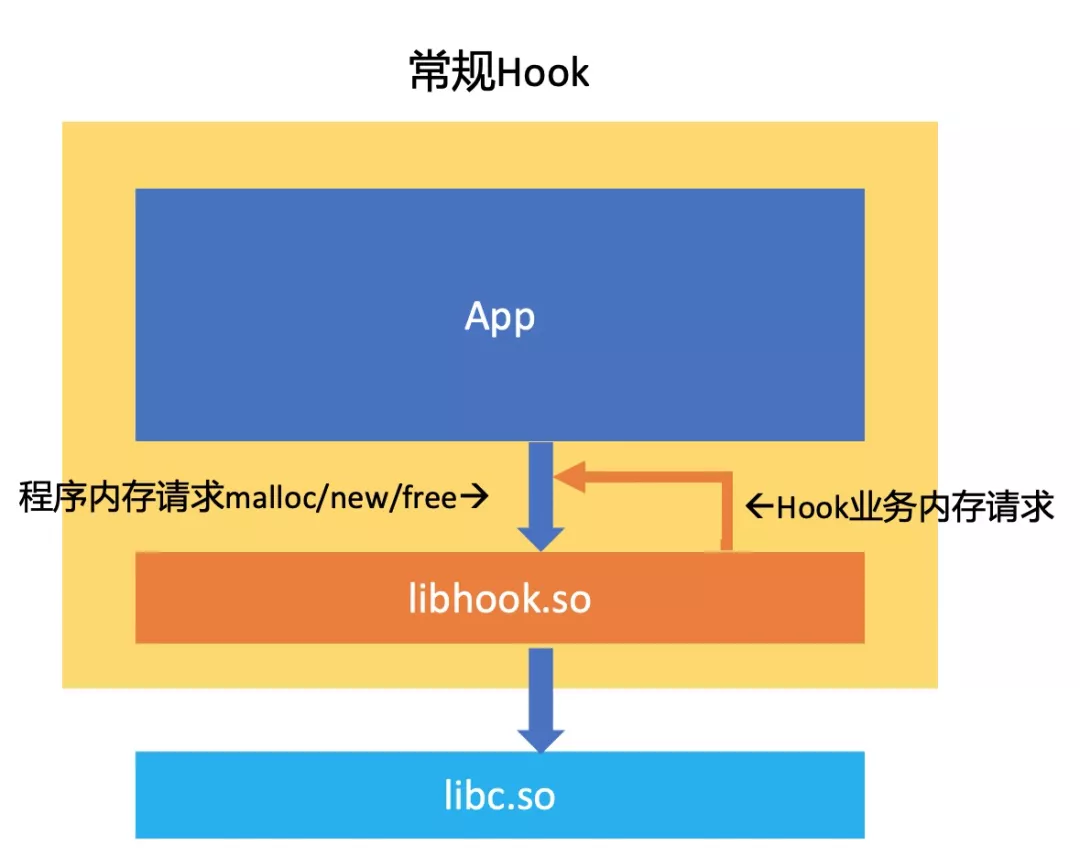
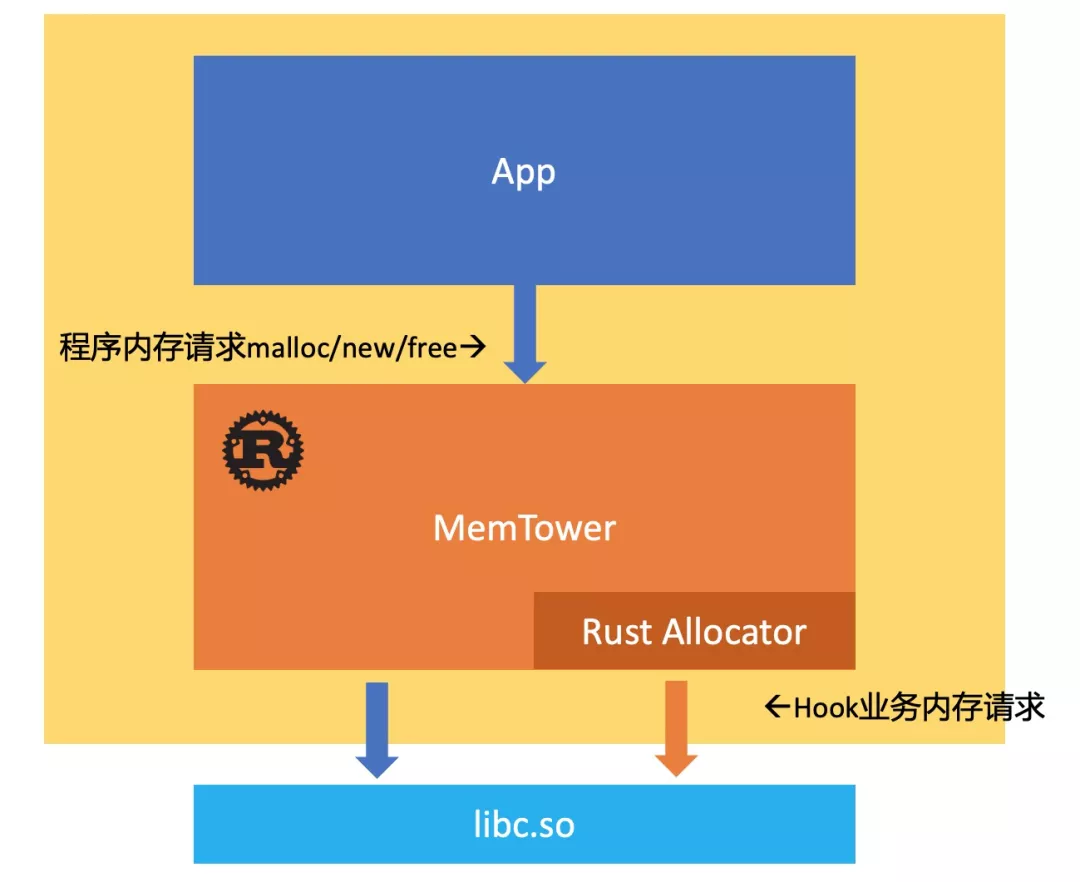
通常对Native内存性能分析使用的方案是Hook malloc 和 free 等内存调用请求。mp的原理也是如此,利用LD_PRELOAD 预加载自定义库实现对内存操作函数的Hook。这种方案最大的问题是容易引发循环malloc调用。如下图,Hook了程序内存请求后,Hook业务自身的内存请求也会触发内存请求,从而造成了malloc循环调用,引发栈崩溃。
mp的做法利用了Rust的可自定义内存分配器(Allocator)的特性,将曾经的Rust默认内存分配器jemalloc作为自定义分配器,并在jemalloc-sys的c代码中将最终的内存申请mmap替换成自定义的函数入口(从而也区分应用和自身的mmap调用),最终调用mmap系统调用。
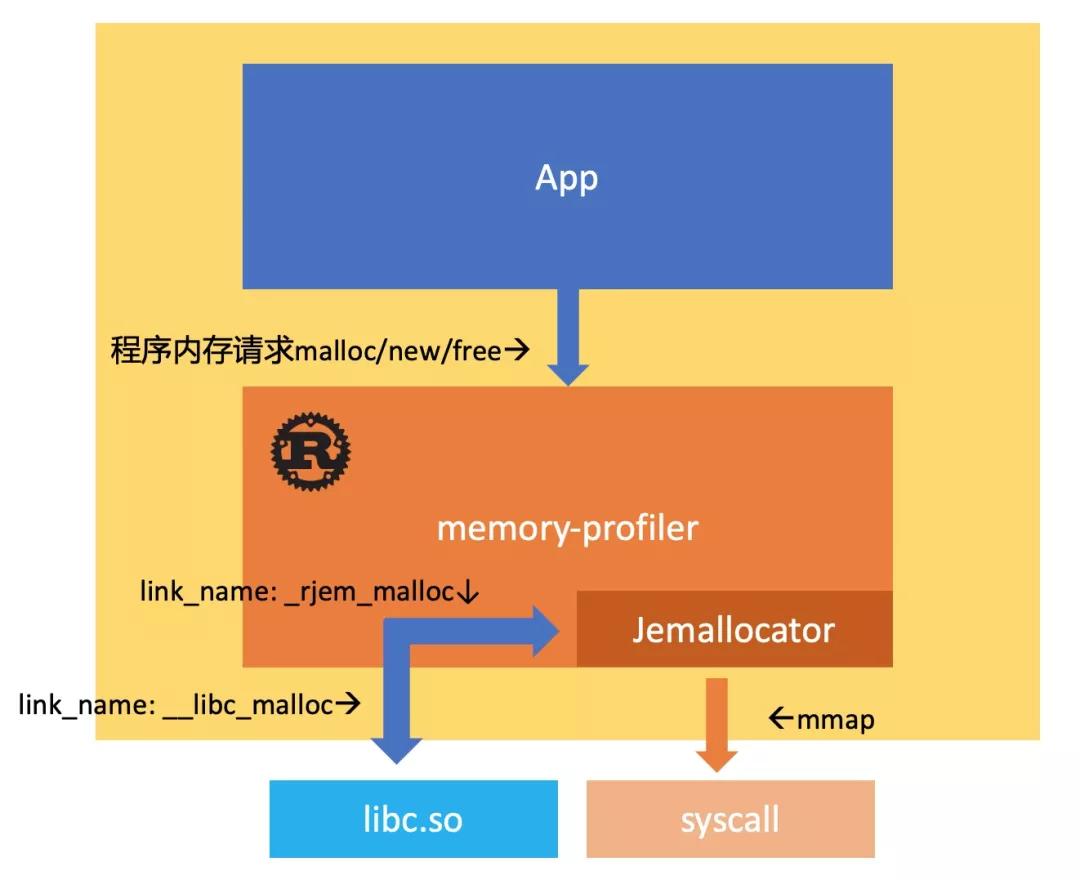
将Rust内存请求转发给系统调用后,还需要将应用的内存请求继续传递给系统libc. mp的做法是通过Rust的feature开关,可以自行选择两种方式处理应用内存请求,这两种方式都是通过在Rust中指定link_name 属性实现:
- 直接通过__libc_malloc的link_name将应用内存请求转发给libc
- 通过指定成jemallocator的函数入口 _rjem_malloc,使应用和Rust共用jemalloc.
- 最终可以使Hook业务使用完整的Rust语言功能而不用担心Rust自身代码引起的循环调用崩溃。
2.1.2 高性能堆栈反解
除了利用Rust系统编程语言特性避开内存循环调用之外,作者还利用Rust的高性能特点实现了几种高性能堆栈反解。
利用ELF的.eh_frame 节(C++异常处理机制)提供的栈回溯信息。
基于.ARM.exidx + .ARM.extab的栈回溯,这个是ARM提供的unwind table.
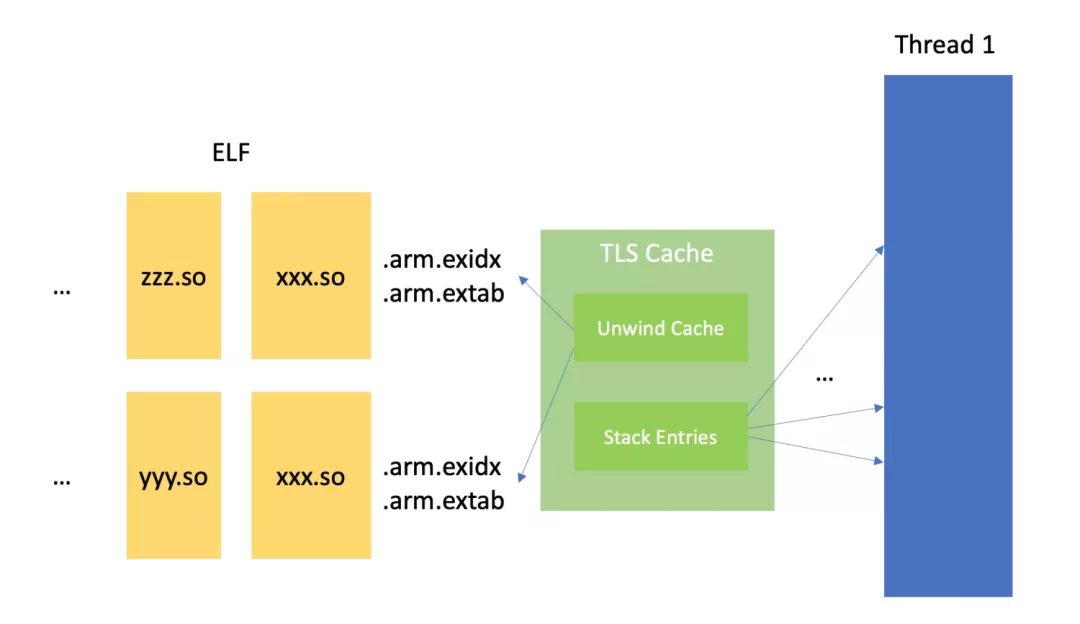
具体实现可以看作者的这个Crate not-perf。这里选择第二种做说明,如图下,对每个线程的堆栈都用线程局部存储维护了一套栈帧缓存,这个缓存来自于ELF文件中的unwind table信息,当堆栈的帧在缓存未命中时会把对应二进制的unwind表被加载到内存,而命中的时候,就不需要去读取文件。通常二进制被加载后它的地址空间就不会发生变化,所以缓存的效率很高。缺点是每个线程都有一套完整的缓存。从系统层面看占用的内存overhead很大。
2.1.3 强大的数据分析功能
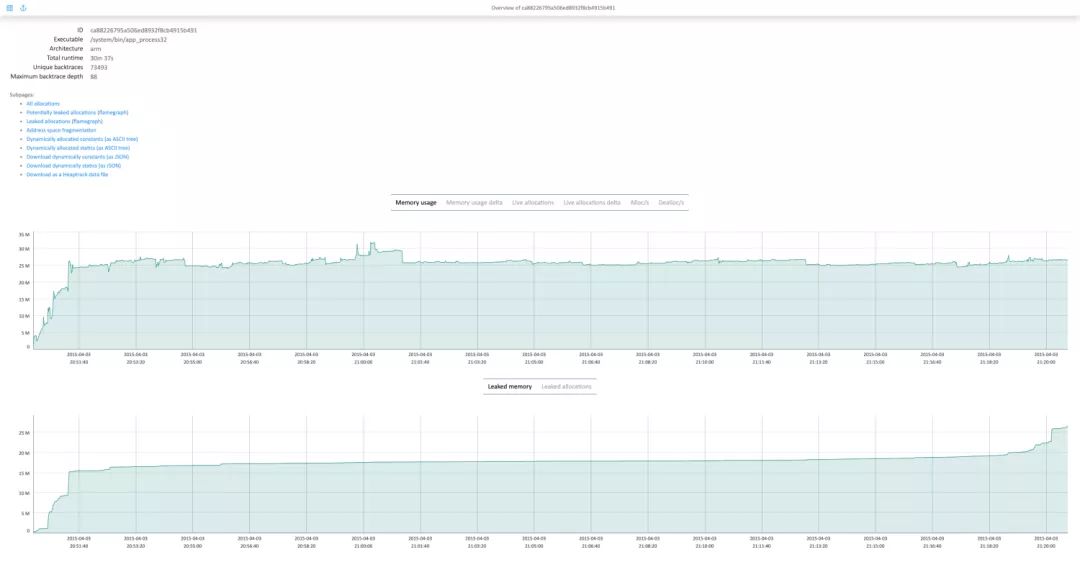
从mp的页面可以看到它除了内存Profile外,还有一个对应的数据分析Server端,采用actix-web框架,且具备一个非常强大的分析功能。主要特性有下面几点:
- 内存使用量和泄漏两种视角的时序曲线非常直观。
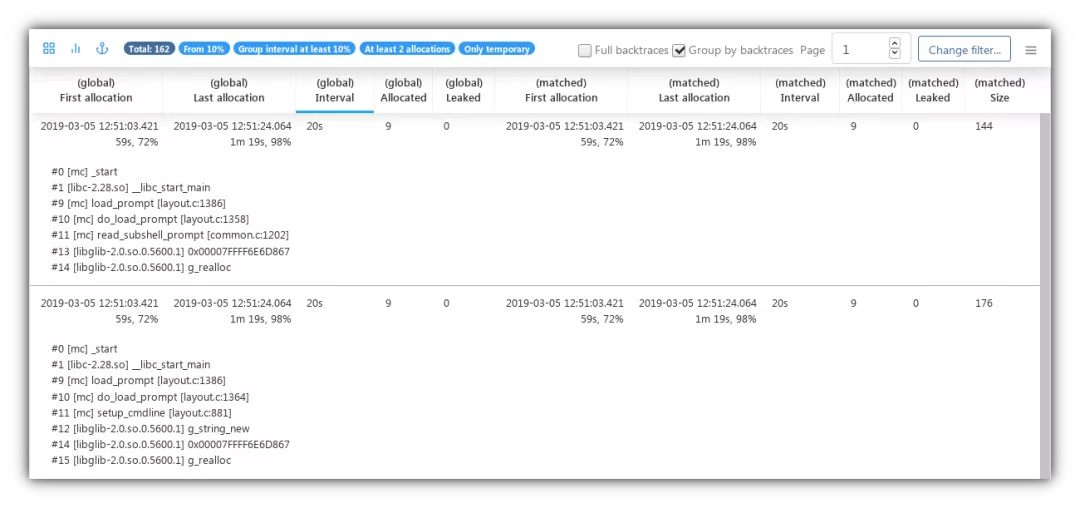
- 搭配了一个非常强大的过滤器,可以实现针对内存生命周期、函数、时间等多维度做过滤查询及其对应的内存火焰图功能。
- 所有功能具备RESTful API接口,可以非常容易的实现定制。
详细的使用说明这里不做过多的介绍。
2.2 移植
了解完mp的基本原理后,本节我们主要阐述在移植安卓平台过程中遇到的各种问题(坑)。
2.2.1 自定义Allocator
mp的Hook方案在Android平台上存在较多问题,主要体现在下面几点:
- Jemalloc本身也才是Android 5.0开始引入安卓,mp自带的jemalloc-sys会导致一个应用里存在两个jemalloc,最终表现为在不同的版本上有着各种各样的异常崩溃,问题排查成了阻碍。
- __libc_malloc是glibc提供的malloc函数入口别名,但在Android平台没有对应这类实现。
因此,我们采用最原始的dlsym 方法获取内存相关函数入口,再将其封装成Rust Allocator. 应用的内存请求也使用这些函数地址。如下图,最终所有内存请求都传给libc,这样Rust的业务代码对libc来说是透明的。
2.2.2 栈回溯
栈回溯这块同样有一些移植修改。上面说到作者提供了基于C++异常处理机制的栈回溯方法,但是这个方案要求依赖C++库。而C在Android 8.0之后才会成为默认依赖。这要求在8.0之前的版本运行时应用必须也依赖C++库。因此我们移除了这个栈回溯方案,舍去了这个依赖。
2.2.3 地址空间重载
在程序启动或调用dlopen/dlclose时链接器会加载(或卸载)ELF文件,相应的,程序的地址空间会发生变化,这时候栈回溯缓存里的地址空间就可能会失效,需要重新加载(reload),reload操作扫描整个地址空间的变更,这个成本很高。与此同时还需要一种低成本获取地址空间变化的方式. mp的实现主要有两种方式:
libc提供的接口dl_iterate_phdr. Android API_LEVEL低于21(即5.0之前)没有,5.0之后这个函数的结构体和在高版本Android的实现不同。所以Rust定义的单一C结构体格式会导致读取到脏数据作为reload依据,导致非常高频繁地reload.;
Perf的 PERF_RECORD_MMAP2 事件,这个要求内核版本大于3.16。因此这在Android 4.x上也不具备。
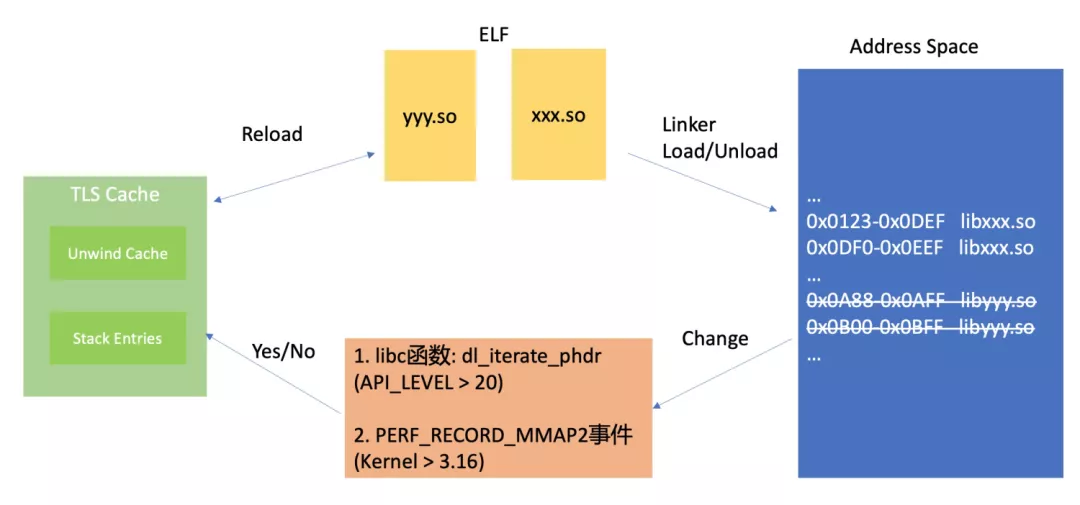
实际运行过程中程序在加载完所有依赖ELF后,地址空间几乎很少再变。因此,我们修改为只有在新的ELF被加载时才进行地址空间重载。火焰图结果显示可以大幅降低Hook时的计算成本。
2.3 改进
到目前为止, 内存塔已经可以在支持 LD_PRELOAD 的Android版本上正确运行了(含4.x)。但是上面诉求中还有一点无法满足:长时间内存泄漏压测。而且在数据分析过程中,我们希望有更多维度的信息。因此,本小节主要介绍我们对内存塔的改进。
2.3.1 内存泄漏压测
mp原先的定位正如它的名称表述,是一款内存性能分析工具,它记录的是全量内存信息。这点决定了它的数据量规模。在长时间压测一小时的多个业务场景中,根据内存使用量不同,生成的采样数据文件有1GB~7GB之多。这样的数据量无法满足业务的需要。
因此,我们增加了内存泄漏检测模式(ONLY_LEAKED),这个模式的原理如下:
- 将记录到内存开辟的每一层栈帧记录到一个字典树(Trie Tree)中,同时记录开辟的内存大小。
- 内存释放时更新字典树对应的节点信息。当前泄漏是否达到某个阈值(如100MB), 是则停止采样。
- 在结束采样时把整个字典树存储的未释放内存记录写入文件。
这种模式的优点是最终的数据量非常的小,实际压测一小时数据文件大小在100~200MB之间。再进过mp自带的postprocess 子命令压缩后,大小不足100MB。不足之处是内存塔需要在内存中缓存一个全量的堆栈历史数据,当没有新的栈帧记录出现后这个内存增长才会趋于稳定。
2.3.2 增强分析过滤器
导航的业务模块划分和线程很多,因此增加了按线程和库正则筛选过滤器选项。

2.3.3 内存火焰图完善
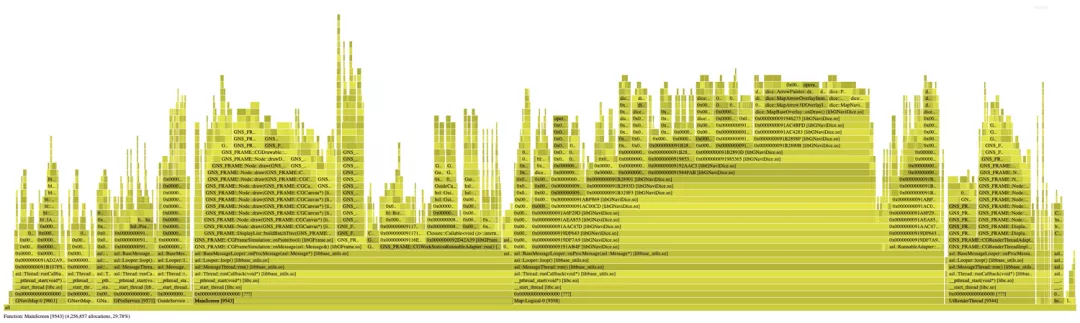
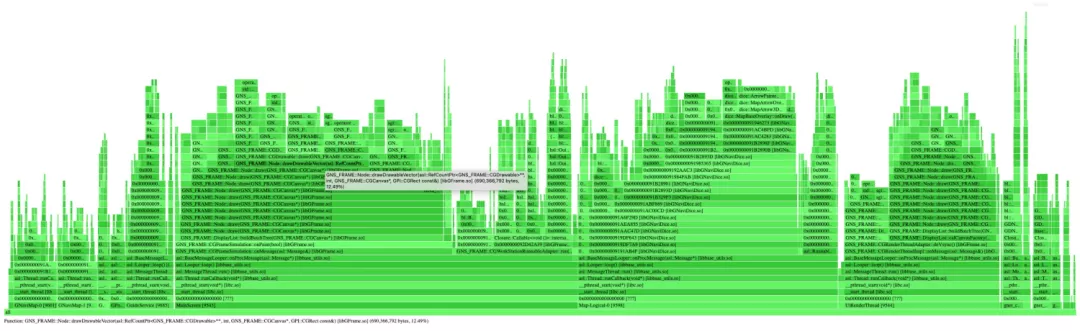
mp原方案的内存火焰图是以内存大小(allocated)作为火焰图维度,在分析内存性能时内存开辟次数(allocations)也是一个很重要的指标,因此加入内存开辟次数火焰图。这是当初最早改进的功能,而且火焰图的形状类似塔状,就把该项目重命名为:内存塔(MemTower)。
最后一点是原方案的火焰图信息没有以线程为单位划分,我们把堆栈信息按线程区分后会更加直观。
分配次数火焰图
分配大小火焰图
3. 内存塔的能力及更多可能
最后一节介绍下内存塔提供了什么样的能力、收益以及还有哪些可能。
3.1 能力
内存塔(MemTower)在Android 8.0以下依赖setprop wrap.com.xxx.xxx 和 root权限的能力,8.0以上版本如果没有root权限还可以通过配置Android项目wrap.sh来加载内存塔库。另外,由于mp原生支持Linux的原因,我们也成功适配了奔驰戴姆勒这类嵌入式Linux项目车机。
- 支持平台:Android 4.x、5.1.1和7或更高以上版本(5.0和6系统存在Bug, 无法设置setprop ). Linux x86_64, AArch64, Arm.
- 采样方式: 非侵入式. 非Root设备可选侵入式方式。
- 采样模式: 常规性能分析模式和内存泄漏压测模式。
- 特点: 高性能堆栈反解、完善的内存分析Insight体验(多维度过滤器分析、内存火焰图等)。
原先发现内存泄漏问题重新出包二次压测分析,再推断可能泄漏点的流程耗费时间按天计算。利用内存塔(MemTower)做一遍测试后几分钟即可解析出精细化数据,大幅降低了内存性能问题分析成本。mp提供的这套Hook思路和高性能堆栈反解其实可以不仅仅局限在内存方面的分析,还可以针对IO性能分析或其它问题上。