前言
Hey,大家好呀,我是码农,星期八!
最近在学习关于逆向的一些玩意,发现逆向不得不说都是些玩底层的玩意。
在学习的过程中,发现了一个其实在正向开发中也用的很多的底层知识点,就是位和字节。
比如一个数字a究竟是怎么存在内存中的。
一段代码
本次就以Go语言举例,Go语言是类C语言,一些底层还是很相近的!
代码
- package main
- import (
- "fmt"
- "unsafe"
- )
- func main() {
- //定义一个 字符a
- var a = 'a'
- //定义一个 正 整数3
- var b uint8 = 3
- var c uint8 = 98
- fmt.Printf("值:%c,十进制:%d,类型:%T,二进制:%b,大小%v字节\n", a, a, a, a, unsafe.Sizeof(a)) // 4个字节
- fmt.Printf("值%d,十进制:%d,类型:%T,二进制%b,大小%v字节\n", b, b, b, b, unsafe.Sizeof(b)) //一个字节
- fmt.Printf("值%c,十进制,%d,类型:%T,二进制%b,大小%v字节\n", c, c, c, c,unsafe.Sizeof(c)) //一个字节
- }
执行结果

有几个问题
我a变量命名时字符a,为什么十进制是97,二进制是1100001?
为什么变量c命名是98,却能输出b?
位和字节
要像理解上述问题,还是要理解本质问题。
我们的程序,终究是跑在内存中的。
而我们的内存条,大概是这样。
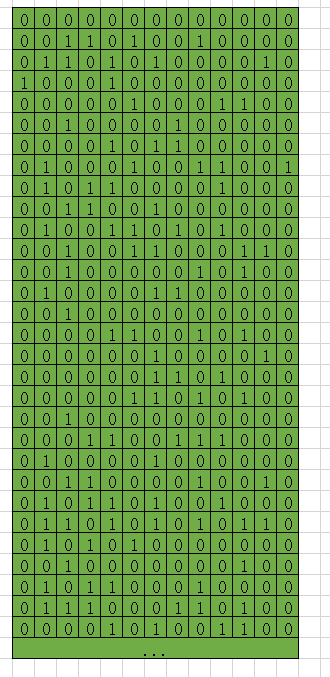
内存条的本质,本质就是一个个的电子元件,终究只有两种状态,通电(1),没通电(0)。
位
一个电子元件,就是一个位。

字节
而一个字节,等于8位,1字节=8位 。

一位,就是一个0或1,就是二进制,非0即1。
一个字节,就是8个0或1,就像这样,00000000,如果看到不足8个0或1,将前面都补成0,补够8位。
通常情况下,语言一般只操作到字节,很少操作到位。
为什么a是97
虽然上述我们知道了,一个位表示的就是一个通电或者没通电的电子元件。
一个字节表示的是8个通电或者没通电的电子元件的组合。
但是这样并没有解决实际问题啊,我想存一个10,在加上一个20,进行加法计算,咋办???
所以这时候,就要有一个什么规定,哪个亮,或者哪个不亮,就表示是什么。
所以就有了ASCII这个规范,这个规范的最小单位是字节,也就是同时管理8个0或1。
比如说,第一个字节,就是前八位,如果说全部都是0,就表示的是十进制数字0。
8个二进制表示方式是00000000。
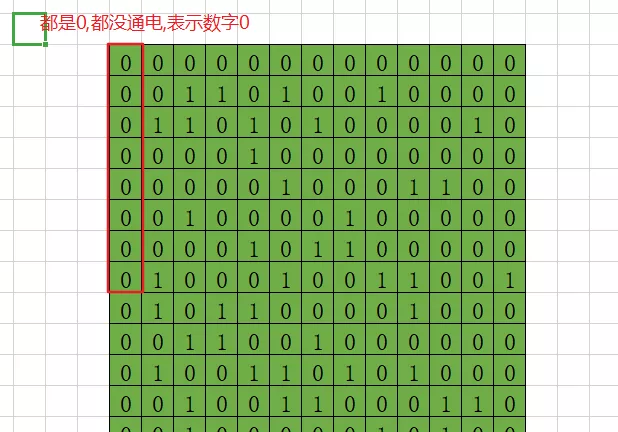
又规定,从末尾开始计算,如果末尾亮了,其他7个没亮,表示十进制1。
00000001
等等等等,通过字节组织位,通过每8位不同的组合,表示不同的符号或者数字或者字母等。
具体二进制对应的符号或者数字:https://baike.baidu.com/item/ASCII/309296?fromtitle=ASCII%E7%BC%96%E7%A0%81&fromid=3712529&fr=aladdin
通过查询ASCII可知。
字母a的二进制是0110 0001,十进制是97,表示的符号是a。

所以就和开头对上咯!
为什么98能输出b,还是因为ASCII,因为98代表的就是字母b,就是二进制0110 0010。
只不过是输出方式不一样。
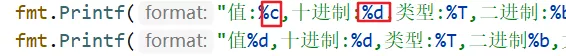
目前的编码方向
其实一个字节,8位,如果全部亮灯,就是11111111,他的十进制是255,理论来说是可以支持255个符号的。
对于英语的国家应该是凑合了,一个字母8位,一个字节,存一个hello就是5个字节,一共需要40位就足够了。
但是现如今,计算机早已经成为一颗参天大树,中国再用,小日本再用,棒子再用,各国的文字加起来早都不是255个那么简单了。
所以衍生出像中国的GBK等一些编码,各种编码都是基于ASCII扩充的。
ASCII占一个字节,8位,那我GBK不够啊,几万个汉字呢,那我占俩字节,16位,16个0或者1,应该凑合吧,再不行三个字节,24个0或1,三个字节十进制就已经到16777215了,上千万了,足够保存各国的符号和文字了。
但是GBK和其他编码又不通用,所以现在又衍生出utf-8等编码收录各国的编码。
目前utf-8是一个最好的编码,基本已经支持所以计算机。
总结
本篇主要是理解计算机内存的本质,1字节=8位,1位=一个通电or没通电的电子元件,通过不同的00101010表示不同的符号。
经过这么多年的发展,utf-8已经很成熟,目前趋势很稳定。