每当有人发布关于 python 处理 Excel 数据的文章,总会有人只看了标题就评论:
- "vba处理已经足够,完全没必要使用python"。
- "我工作环境不能安装,因此vba就比python更适合处理Excel"
- "vba比python快速100倍!"
其实,那些稍微接触过 pandas 的人,相信都会心底上抗拒使用vba。

而我本人一直保持一个观点,各种工具都有他的优劣势,抛开应用场景单纯说某个工具更好都是在耍流氓。今天,我就举例说明一下,哪些场景适合vba,哪些场景适合python。
我喜欢用实际案例说明问题,本文使用泰坦尼克号沉船事件中的乘客信息表:
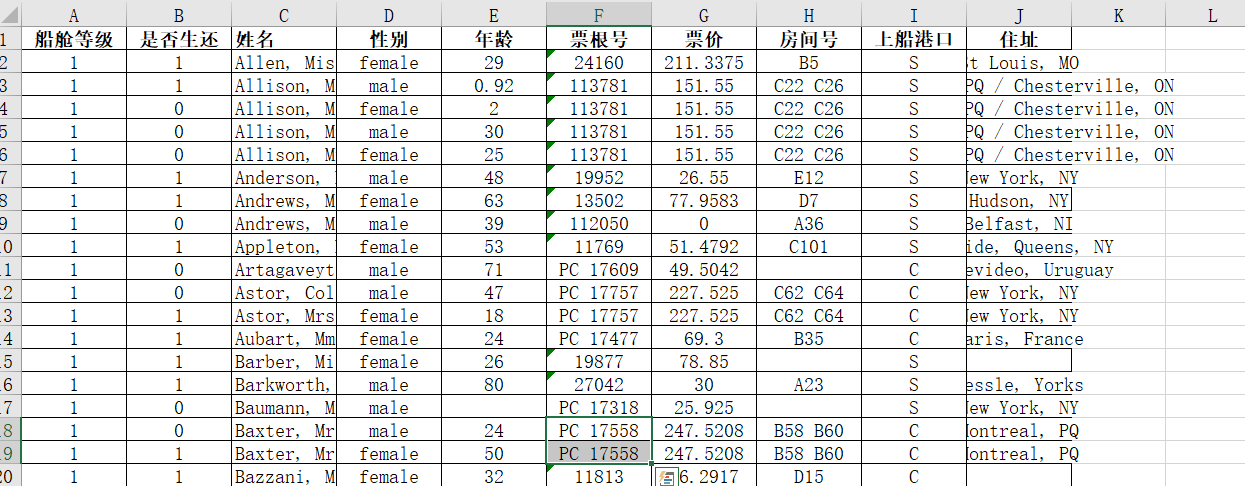
实现几个简单分析需求:
- 找出多人(2人或以上)一起登船的组的数量
- 列出这些人的信息
- 是否存在最幸运的亲朋好友(多人一起登船,同时全部人都获救)?
"操作 Excel"等于"数据处理"吗?
初学者往往误以为操作 Excel 就是在处理数据,实际上是两回事。
需求是:"姓名与住址列内容通常很长,希望最终Excel显示的时候,使用缩小字体填充"。
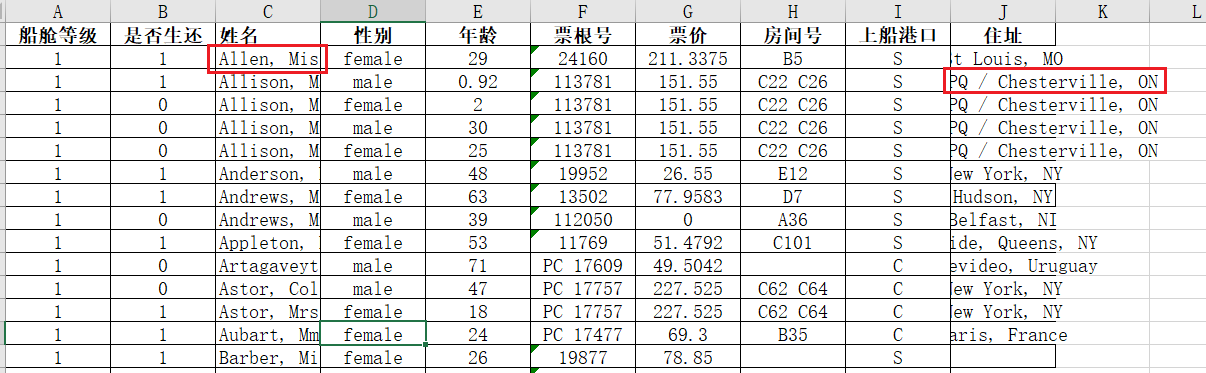
对于这种格式化设置,vba绝对是最佳选择!因为我们可以通过录制宏,自动得到大概的代码
通过简单的录制宏,我们就能写出如下实现:

如果我们使用 python 实现相同的需求,代码肯定只多不少,并且难以调试。
如果你看过我的专栏《带你玩转Python数据处理—pandas》的话,其中关于数据处理流程一节,你会想到,这就是"数据展示"的流程。
也就是说,如果你的数据任务最终需要输出 Excel 文件,vba是"数据展示"过程的最佳自动化工具。
可惜,现实中的大部分需求并不单纯,都需要进行"数据处理",那么 vba 中又是如何处理数据?
vba 使用数组+字典,就是高效率?
大部分不经思考,张口就反对 python 的同学,都是对自己的 vba "数组+字典" 的技能有着迷之自信。
来看一个数据分析相关的处理需求:
我们注意到,有些人是亲朋好友一起上船,比如:
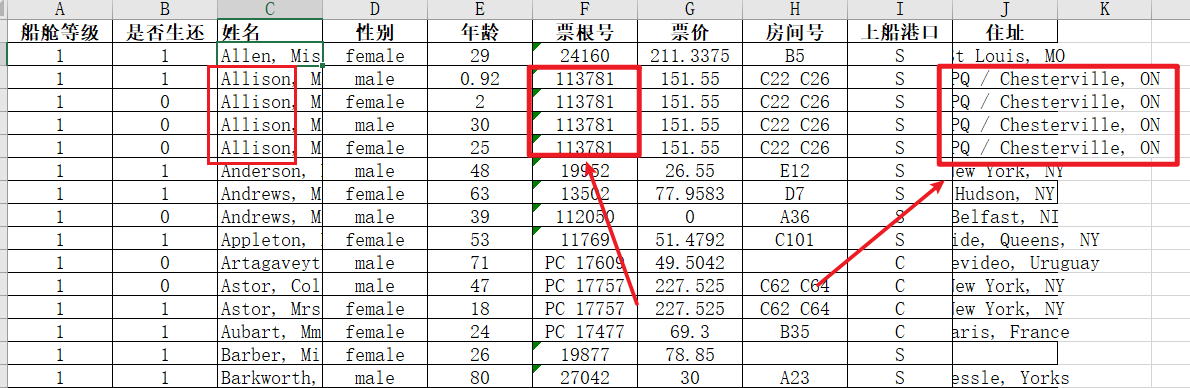
- 从"票根号"一样,可以看出来他们是一起上船
- 从"住址"一样,可以看出来他们是一家四口
我们需要统计出有多少组这些2人或以上登船的?
以下尝试用vba解决:
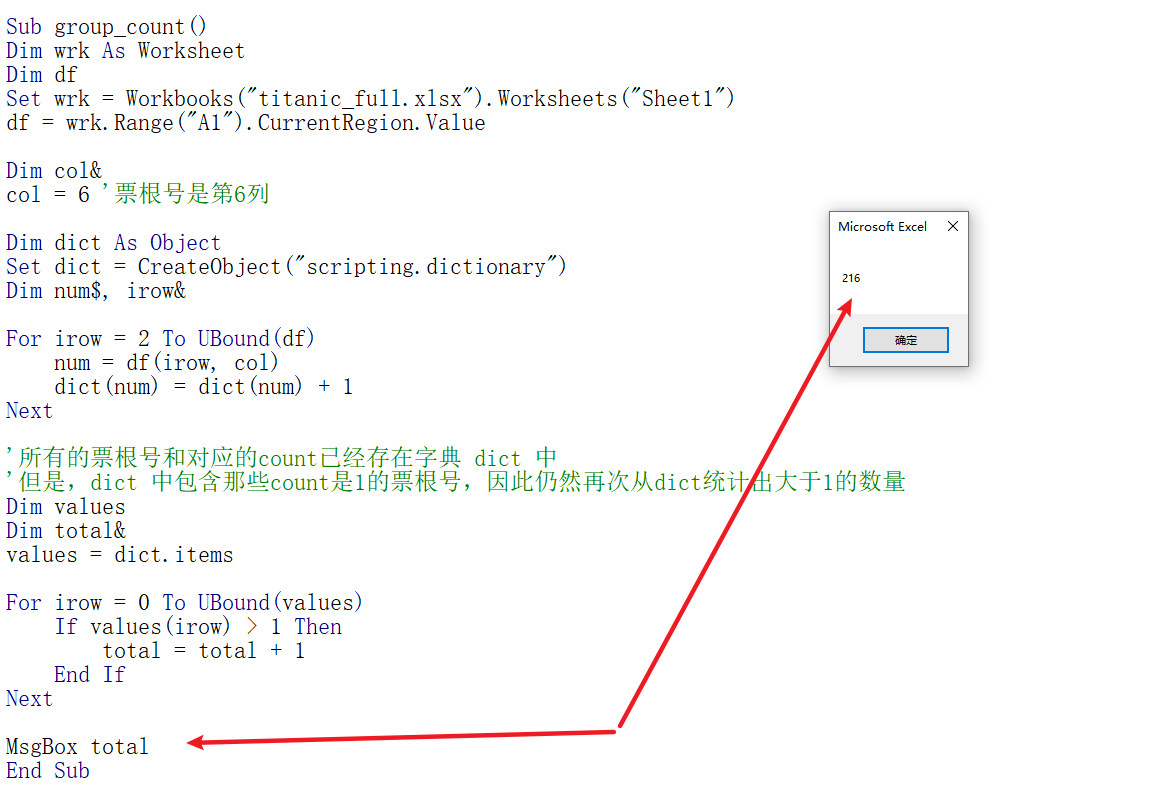
其实代码不算多,里面的技巧也只是基础,但是如果会 pandas 的同学心里肯定会说:"太繁琐了"。
因为对于 pandas 来说,如下:

代码就4句,最关键的其实只有3句,分别表示:
- 加载数据
- 按"票根号"分组统计数量
- 数量大于1的总和
这不就是一个正常人的处理思维吗?这就是简洁
能够与需求表达语义相近,多余的表达越少,即越简洁
回头看 vba 的表达,多余的表达非常多。
- Excel 有一个非常好用的统计工具——透视表。你可以尝试通过录制宏得到透视表的操作代码,但是你仍然会发现有许多多余的表达。
- Sql 的表达更加简洁,但是实现如上的需求,你会发现他的表达顺序需要"绕"一下
有些不服气的同学会说:"我写出这段vba代码也就1分钟,反正也能得到正确结果"
当需求不断变化,你就会发现这样子的代码最终走向无法实现的死胡同。
刚刚我们知道了有216组亲朋好友是一起登船的,但只有一个数字,我们希望看看这216数据的大概样子。
也就是说输出这些乘客数据。
python 的实现:
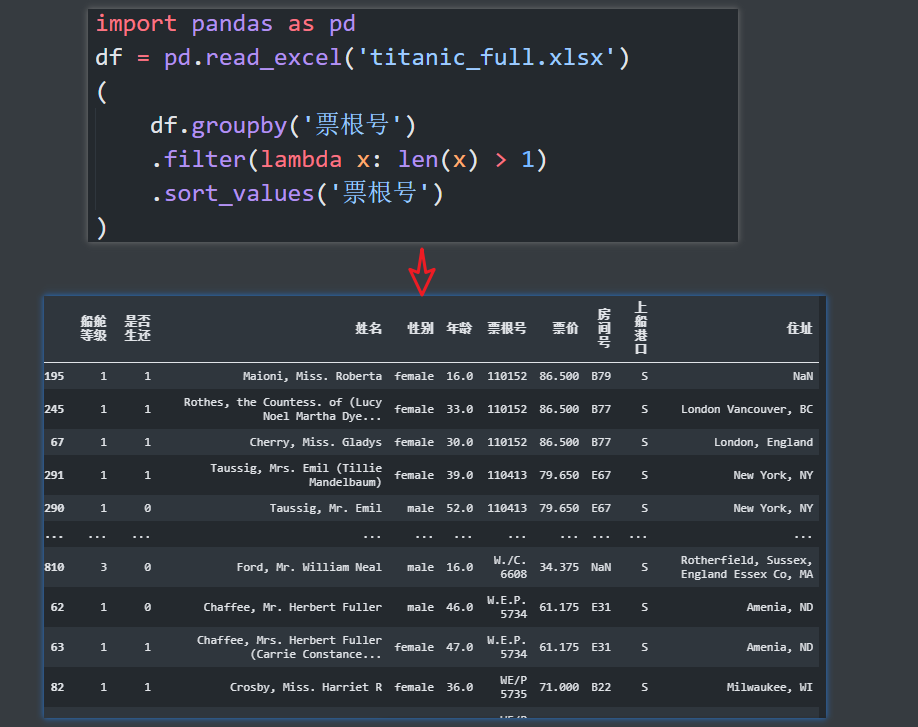
- 顺便排序一下,方便观察
- 这里代码多余的表达,就是那个 lambda 单词。如果换成是 sql ,就非常简洁
vba 的实现太麻烦了,就留给那些不服气的 vba 粉丝吧
现在你大概能够稍微理解,为什么 Python 在数据领域这么受宠了。
数据分析中的数据处理,需要你的代码赶上你的思维速度,只有简洁的语言才能做到。
按理说,sql 应该是更好的选择,但实际上很多复杂需求实现,sql 需要大量的嵌套查询,此时就一点都不简洁了。以后再举例说明
现实的需求是 "操作Excel" + "数据处理" ,怎么办?
这时候最理想的情况是,使用 vba 操作 Excel,数据处理交给 Python,中间就需要一个桥梁把 vba 与 python 打通,这就是 xlwings 或其他类似的库的最佳实践方式。
如果你完全使用 xlwings 控制 Excel,Python 代码操作 Excel 写起来非常别扭,一旦你理清楚 "操作Excel" 与 "数据处理" 的区别,自然而然知道如何组织你的代码。
Python 需要单独安装,因此他比不上 vba
这是一种无聊的结论,因为任何自动化工具都需要安装,比如学习性价比最高的 Sql ,他也需要安装相应的驱动程序才能执行。
而我本人的工作环境有一部分任务是需要放在服务器上执行,此时是不可能安装 Excel,vba 也用不上了,但我不能因此作出"vba比不上python"的结论吧。
如果你的工作环境不能安装 python,但你又需要做大量数据处理任务,那么我只能说非常不幸,你只能牺牲自己大量的时间使用vba去完成需求。
Vba 就不能有 pandas 的存在吗?
"说了半天,不就是 python 比 vba 多了一个 pandas 库而已吗,找个vba牛人去写一个 vba-pandas 就行啦!"
vba 天生缺少了一种语言特性,使得你即使有写库的能力,也无法发挥。
这就是提取逻辑的能力.
通常来说,如果一段代码有些数据不是固定,我们可以提取成函数的参数,比如最简单的数字计算:
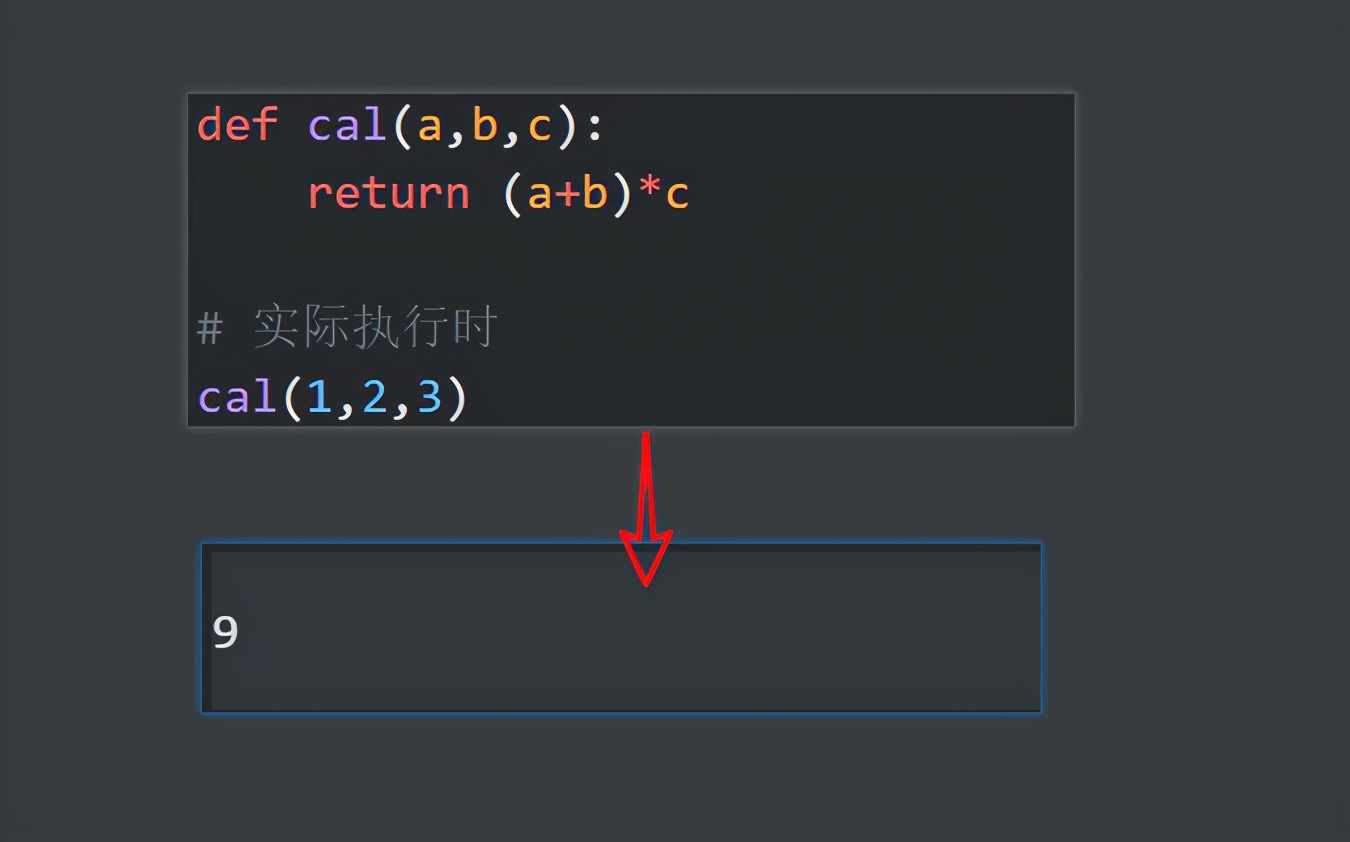
- 分别定义3个参数,让你输入,但计算方式是固定的
对于 vba 来说他同样可以做到,但是如果是其中一段代码不是固定,能否把他提取为参数呢?
而 python 就能做到,比如以下的函数,可以让你输入3个数字,并且由你决定前2个数字的计算方式,最后与第3个数字做乘法:
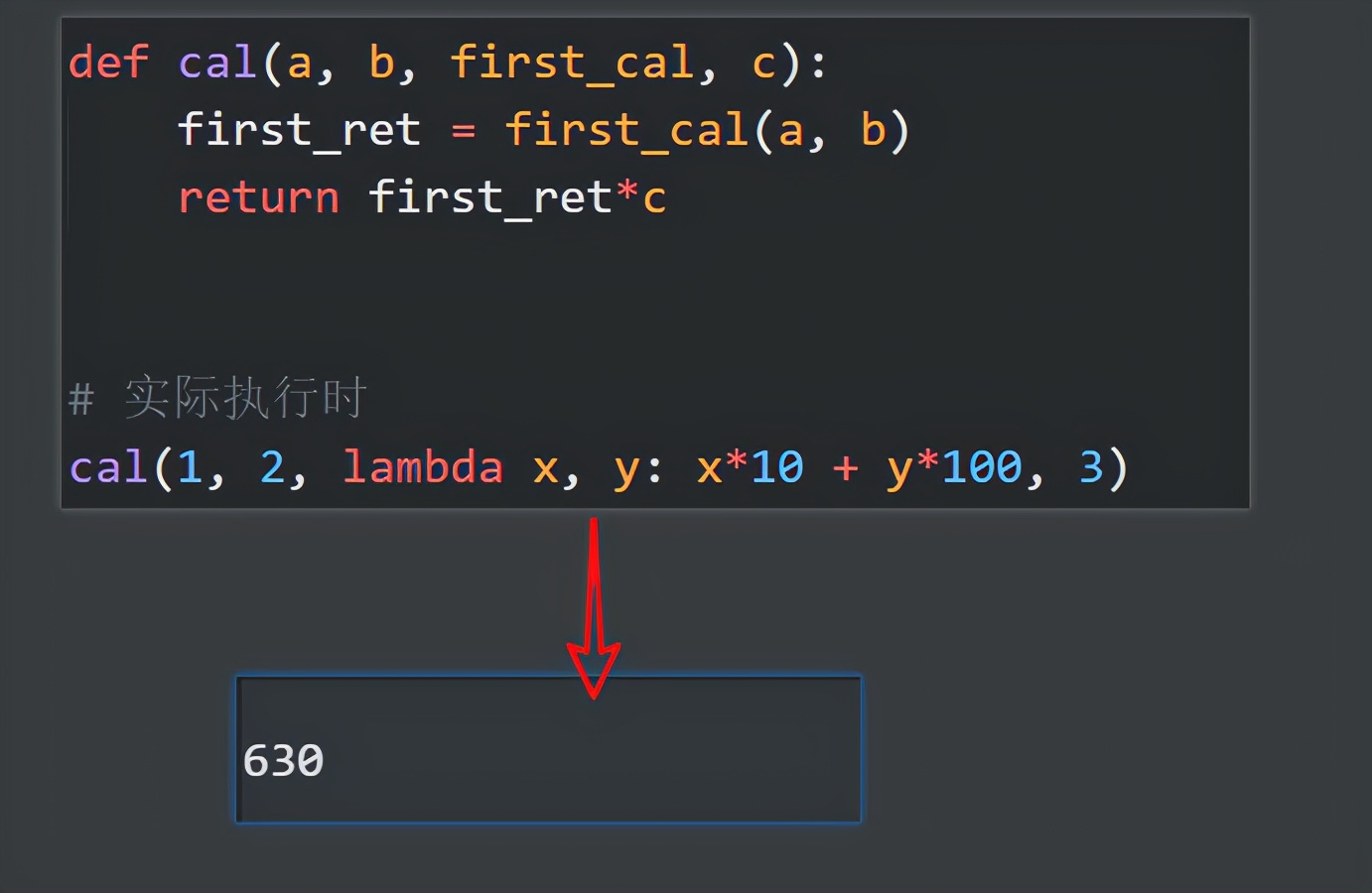
结果时,第一个数乘以10 + 第二个数乘以100(这是变化的逻辑,由使用函数的人自行决定),最后乘以第三个数(这是固定逻辑,由定义函数的人决定)
vba 需要使用接口做到同样的效果,非常麻烦,对于数据任务没有任何实用价值
这有什么用处?用最后一个需求说明:
- 是否存在最幸运的亲朋好友(多人一起登船,同时全部人都获救)?
假如说,我只给你一组相同"票根号"的乘客数据,该如何判断他们都是生还呢?

只要看"生还"列是否都为1就可以。方式非常多,除了上面的做法,还可以"生还列求和,看看是否等于记录行数"
前一个需求中使用的 filter 就是可以接受一段逻辑(函数),pandas 负责帮你分组,你只需要在函数中描述出符合条件的逻辑即可:
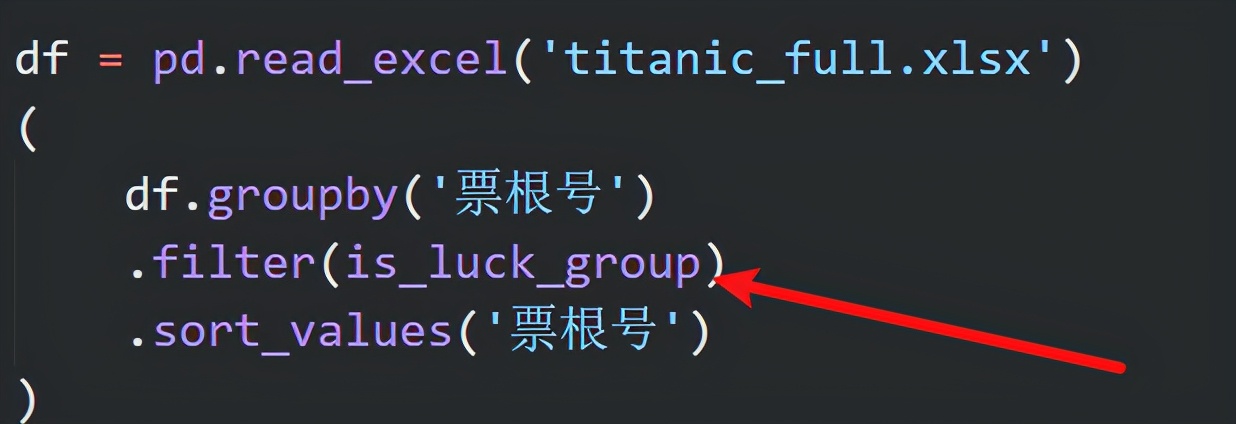
- 把刚刚定义的函数,传给 filter 函数
而 vba 无法做到这一点,就意味着他无法做出 pandas 一样好用的库!
因为许多看似复杂的流程,其实是由许多固定的逻辑 + 变化的逻辑 组成。
比如分组的原理就类似 vba 中使用字典,这是相对固定的,完全可以让库完成。
但是分组后,每一组的处理逻辑却是变化的,由使用者临时决定,比如之前的需求分组中我们有时候需要计数,有时候需要筛选。筛选的逻辑也是千变万化。
最后
任何工具都有他的适用场景,如何合理利用才是我们的学习方向,而非一根经地排斥自己不熟悉的工具。